Opencv
main modules
core
定义基本数据结构的紧凑模块,包括稠密的多维数组 Mat 和所有其他模块使用的基本功能。
imgproc
一个图像处理模块,包括线性和非线性图像滤波、几何图像变换(调整大小、仿射和透视变换、通用的基于表的重映射)、色彩空间转换、直方图等。
imgcodecs
图像文件的读取和写入
videoio
视频输入和输出
highgui
GUI界面
calib3d
相机标定和三维重建
features2d
2d特征的检测,描述,匹配以及在图像上绘制2d特征点和匹配对
objdetect
用于目标检测的基于Haar 特征的级联分类器
dnn
用于构建深度神经网络,主要是测试网络的输出,不支持网络训练
ml
一组用于统计分类、回归和数据聚类的类和函数。
- flann
FLANN库的opencv接口(功能不完整)
- flann
photo
照片处理算法,包括修补,去噪,HDR成像等
stitching
图像拼接
gapi
OpenCV Graph API(或 G-API)是一个新的 OpenCV 模块,旨在使常规图像处理快速且便携。这两个目标是通过引入新的基于图的执行模型来实现的
contrib modules
alphamat
从背景图像中提取具有软边界的前景
aruco
ArUco 标记是二进制方形基准标记,可用于相机姿态估计。他们的主要好处是他们的检测是鲁棒、快速和简单的。
aruco 模块包括这些类型的标记的检测以及使用它们进行姿势估计和相机校准的工具。
bgsegm
背景分割
bioinspired
视网膜模型及其在图像处理中的应用
ccalib
多相机和广角相机标定
cnn_3dobj
用于3D物体分类和位姿估计的卷积神经网络
cvv
应用于计算机视觉类应用的交互式Debug
dnn_objdetect
使用卷积神经网络进行目标检测
dnn_superres
使用卷积神经网络进行图像放大(提高分辨率)
face
人脸识别的相关算法
fuzzy
模糊数学理论在图像处理中的应用,主要是F变换
hdf
hdf5文件的输入和输出
Julia
OpenCV的Julia语言封装
line_descriptor
从图像中检测直线
mcc
图像色彩校正
phase_unwrapping
二维相位展开
sfm
运动结构恢复
stereo
稠密立体匹配
structured_light
结构光反射图案的解析
Text
Tesseract文字识别框架
tracking
图像中的物体追踪
viz
可视化窗口(类似Qt)
ximgproc
拓展图像处理模块。包含结构森林,变化域滤波器,导向滤波,自适应流行滤波器,联合双边滤波器和超像素。
xphoto
白平衡调整
Opencv如何对像素进行操作
取
Mat cv::imread ( const String & filename,
int flags = IMREAD_COLOR
)
filename (必须的):需要读取的图像名,你也可以写成读取的路径:绝对路劲和相对路径都可
flag (可选):flag时读取图像的格式。
如果你没有flag选项就按照原始的图像格式,如果有flag选项就按照flag格式读取
flag可以是数字,也可以是具体的类型(枚举)
enum ImreadModes {
IMREAD_UNCHANGED = -1, //!< If set, return the loaded image as is (with alpha channel, otherwise it gets cropped).
IMREAD_GRAYSCALE = 0, //!< If set, always convert image to the single channel grayscale image.
IMREAD_COLOR = 1, //!< If set, always convert image to the 3 channel BGR color image.
IMREAD_ANYDEPTH = 2, //!< If set, return 16-bit/32-bit image when the input has the corresponding depth, otherwise convert it to 8-bit.
IMREAD_ANYCOLOR = 4, //!< If set, the image is read in any possible color format.
IMREAD_LOAD_GDAL = 8, //!< If set, use the gdal driver for loading the image.
IMREAD_REDUCED_GRAYSCALE_2 = 16, //!< If set, always convert image to the single channel grayscale image and the image size reduced 1/2.
IMREAD_REDUCED_COLOR_2 = 17, //!< If set, always convert image to the 3 channel BGR color image and the image size reduced 1/2.
IMREAD_REDUCED_GRAYSCALE_4 = 32, //!< If set, always convert image to the single channel grayscale image and the image size reduced 1/4.
IMREAD_REDUCED_COLOR_4 = 33, //!< If set, always convert image to the 3 channel BGR color image and the image size reduced 1/4.
IMREAD_REDUCED_GRAYSCALE_8 = 64, //!< If set, always convert image to the single channel grayscale image and the image size reduced 1/8.
IMREAD_REDUCED_COLOR_8 = 65, //!< If set, always convert image to the 3 channel BGR color image and the image size reduced 1/8.
IMREAD_IGNORE_ORIENTATION = 128 //!< If set, do not rotate the image according to EXIF's orientation flag.
};
存
bool cv::imwrite ( const String & filename,
InputArray img,
const std::vector< int > ¶ms=std::vector< int >()
) filename (必须)同上
img (必须)表示需要保存的Mat类型的图像数据
通常,使用此功能只能保存 8 位单通道或 3 通道(具有“BGR”通道顺序)图像,除去一些特殊情况。
enum ImwriteFlags {
IMWRITE_JPEG_QUALITY = 1, //!< For JPEG, it can be a quality from 0 to 100 (the higher is the better). Default value is 95.
IMWRITE_JPEG_PROGRESSIVE = 2, //!< Enable JPEG features, 0 or 1, default is False.
IMWRITE_JPEG_OPTIMIZE = 3, //!< Enable JPEG features, 0 or 1, default is False.
IMWRITE_JPEG_RST_INTERVAL = 4, //!< JPEG restart interval, 0 - 65535, default is 0 - no restart.
IMWRITE_JPEG_LUMA_QUALITY = 5, //!< Separate luma quality level, 0 - 100, default is 0 - don't use.
IMWRITE_JPEG_CHROMA_QUALITY = 6, //!< Separate chroma quality level, 0 - 100, default is 0 - don't use.
IMWRITE_PNG_COMPRESSION = 16, //!< For PNG, it can be the compression level from 0 to 9. A higher value means a smaller size and longer compression time. If specified, strategy is changed to IMWRITE_PNG_STRATEGY_DEFAULT (Z_DEFAULT_STRATEGY). Default value is 1 (best speed setting).
IMWRITE_PNG_STRATEGY = 17, //!< One of cv::ImwritePNGFlags, default is IMWRITE_PNG_STRATEGY_RLE.
IMWRITE_PNG_BILEVEL = 18, //!< Binary level PNG, 0 or 1, default is 0.
IMWRITE_PXM_BINARY = 32, //!< For PPM, PGM, or PBM, it can be a binary format flag, 0 or 1. Default value is 1.
IMWRITE_EXR_TYPE = (3 << 4) + 0, /* 48 */ //!< override EXR storage type (FLOAT (FP32) is default)
IMWRITE_WEBP_QUALITY = 64, //!< For WEBP, it can be a quality from 1 to 100 (the higher is the better). By default (without any parameter) and for quality above 100 the lossless compression is used.
IMWRITE_PAM_TUPLETYPE = 128,//!< For PAM, sets the TUPLETYPE field to the corresponding string value that is defined for the format
IMWRITE_TIFF_RESUNIT = 256,//!< For TIFF, use to specify which DPI resolution unit to set; see libtiff documentation for valid values
IMWRITE_TIFF_XDPI = 257,//!< For TIFF, use to specify the X direction DPI
IMWRITE_TIFF_YDPI = 258 //!< For TIFF, use to specify the Y direction DPI
};
ROI区域
定义
有事需要让一个处理函数只在图像的某个部分起作用,所以需要定义图像的子区域,也就是ROI区域(region of interest)感兴趣区域
int main(){
cv::Mat image= cv::imread("3.png");
cv::Mat logo= cv::imread("2.jpg");
cv::Mat imageROI(image,
cv::Rect(0,
0,
logo.cols,
logo.rows));
imshow("1",imageROI);
//将logo替换image中的感兴区域imageROI
logo.copyTo(imageROI);
imshow("2",logo);
imshow("3",image);
cv::waitKey(0);
return 0;
}扩展:除了使用起点和终点位置,还可以通过列数和行数实现ROI区域定义:
cv:: Mat imageROI = image(cv::Range(0,logo.rows),
cv::Range(0,logo.cols));
指针遍历
像素遍历就是将图像的所有像素都访问一次。由于图像像素数量非常庞大,高效遍历就十分必要
int nl= image.rows; // 行数
// 每行的元素数量
int nc= image.cols * image.channels();
for (int j=0; j<nl; j++) {
// 取得行 j 的地址,这里以uchar图像类型作为例子
uchar* data= image.ptr<uchar>(j);
for (int i=0; i<nc; i++) {
// 处理每个像素 data[i]
} // 一行结束
}例子:减色算法,对每个像素做减色,对于8为无符号字符类型的彩色图有256x256x256中颜色,减色就是减色颜色的种类
/*
减色算法:假设 N 是减色因子,将图像中每个像素的值除以 N(这里假定使用整数除法,不保留
余数)。然后将结果乘以 N,得到 N 的倍数,并且刚好不超过原始像素 值。加上 N / 2,就得到
相邻的 N 倍数之间的中间值。对所有 8 位通道值重复这个过程,就会得到 (256 / N) × (256 / N) ×
(256 / N)种可能的颜色值
*/
void colorReduce(cv::Mat image, int div =64){
int nl =image.rows;
int nc =image.cols;
for(int j=0;j<nl;j++){
uchar* data=image.ptr<uchar>(j);
for(int i=0;i<nc;i++){
data[i]= data[i]/div*div+div/2;
}
}
}
int main(){
cv::Mat image=cv::imread("1.jpg");
colorReduce(image);
cv::imshow("1",image);
cv::waitKey();
return 0;
}
迭代器遍历
//创建迭代器bagin和end,注意要给出图像的数据类型,此处以cv::Vec3b为例
//在opencv中cv::Vec3b向量包含三个无符号字符类型的数据,可以用于描述彩色图的三通道。
cv::Mat_<cv::Vec3b>::iterator it= image.begin<cv::Vec3b>();
cv::Mat_<cv::Vec3b>::iterator itend= image.end<cv::Vec3b>();
// 扫描全部像素
for ( ; it!= itend; ++it) {
//处理每个像素 (*it)[0] (*it)[1] (*it)[2]
}
//或者
while (it!= itend) {
// 处理每个像素 ---------------------
...
// 像素处理结束 ---------------------
++it;
} Opencv点检测
Harris角点检测
角点定义
角点是图像中某些属性较为突出的像素点,例如像素值最大或者最小的点、线段的顶点、孤立的边缘点等,图中圆圈包围的线段的拐点就是一些常见的角点。常用的角点有以下几种。
- 灰度梯度的最大值对应的像素点;
- 两条直线或者曲线的交点;
- 一阶梯度的导数最大值和梯度方向变化率最大的像素点;
- 一阶导数值最大,但是二阶导数值为0的像素点;
Harris算法原理
Harris角点是最经典的角点之一,其从像素值变化度对角点进行定义,像素值的局部最大峰值即为Harris角点。Harris角点的检测过程如图9-3所示,首先以某个像素为中心构建一个矩形滑动窗口,滑动窗口覆盖图像像素值通过线性叠加得到得到滑动窗口所有像素值的衡量系数,该系数与滑动窗口范围内的像素值成正比,当滑动窗口范围内像素值整体变大时,该衡量系数也变大。在图像中以每个像素为中心向各个方向移动滑动窗口,当滑动窗口无论向哪个方向移动像素值衡量系数都缩小时,滑动窗口中心点对应的像素点即为Haris角点
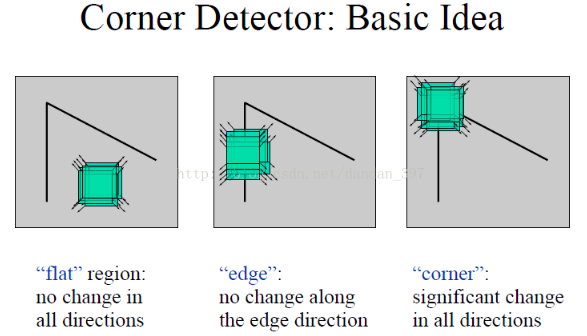
角点检测最原始的想法就是取某个像素的一个邻域窗口,当这个窗口在各个方向上进行小范围移动时,观察窗口内平均的像素灰度值的变化(即E(u,v),Window-averaged change of intensity)。从上图可知,我们可以将一幅图像大致分为三个区域(‘flat’,‘edge’,‘corner’),这三个区域变化是不一样的。

其中:
- u、v是窗口在水平,竖直方向的偏移;
- w(x,y)表示滑动窗口权重函数,可以是常数,也可以是高斯函数;

图中蓝线圈出的地方我们称之为Harris角点的梯度协方差矩阵,记为M。其中,Ix和Iy分别为X方向和Y方向的梯度。 由于E(x,y)取值与M相关,进一步对其进行简化,定义Harris角点评价系数R为:
R=det(M)-k(tr(M))^2
其中k为常值权重系数,det(M)=λ1λ2,tr(M)=λ1+λ2,λ1和λ2是梯度协方差矩阵M的特征向量,将特征向量代入得:
R=λ1λ2-k(λ1+λ2)^2
当R较大时,说明两个特征向量较相似或者接近,则该点为角点;当R<0时,说明两个特征向量相差较大,则该点位于直线上;当|R|较小,说明两个特征值较小,则该点位于平面。
Opencv实现
cornerHarris()——计算角点Harris评价系数R
void cv::cornerHarris(
InputArray src,
OutputArray dst,
int blockSize,
int ksize,
double k,
int borderType = BORDER_DEFAULT)- src:待检测Harris角点的输入图像,图像必须是CV_8U或者CV_32F的单通道灰度图像;
- dst:存放Harris评价系数R的矩阵,数据类型为CV_32F的单通道图像,与输入图像具有相同的尺寸
- blockSize:邻域大小(窗口大小),通常取2;
- ksize:Sobel算子的半径,用于得到图像梯度信息,该参数需要是奇数,多使用3或者5;
- k:计算Harris评价系数R的权重系数,一般取值为0.02~0.04;
- borderType:像素外推算法标志,这里使用默认。
drawKeypoints()——一次性绘制所有的角点(关键词)
绘制关键点
void drawKeypoints(
InputArray image,
const std::vector<KeyPoint>& keypoints, InputOutputArray outImage,
const Scalar& color=Scalar::all(-1),
int flags=DrawMatchesFlags::DEFAULT )
//KeyPoint类数据
class KeyPoint{
float angle //关键点的角度
int class_id //关键点的分类号
int octave //特征点来源(“金字塔”)
Point2f pt //关键点坐标
float response //最强关键点的响应
float size //关键点邻域的直径 - image:绘制关键点的原图像,图像可以是单通道的灰度图像和三通道的彩色图像;
- keypoints:来自原图像中的关键点向量,vector向量中存放着表示关键点的KeyPoint类型的数据;
- outImage:绘制关键点后的输出图像;
- color:关键点空心圆的颜色,默认使用随机颜色绘制空心圆;
- flag:绘制功能选择标志,其实就是设置特征点的那些信息需要绘制,那些不需要绘制,有以下几种模式可选:
| 标志参数 | 简记 | 含义 |
|---|---|---|
| DEFAULT | 0 | 只绘制特征点的坐标点,显示在图像上就是一个个小圆点,每个小圆点的圆心坐标都是特征点的坐标。 |
| DRAW_OVER_OUTIMG | 1 | 函数不创建输出的图像,而是直接在输出图像变量空间绘制,要求本身输出图像变量就是一个初始化好了的,size与type都是已经初始化好的变量 |
| NOT_DRAW_SINGLE_POINTS | 2 | 单点的特征点不被绘制 |
| DRAW_RICH_KEYPOINTS | 4 | 绘制特征点的时候绘制的是一个个带有方向的圆,这种方法同时显示图像的坐标,size,和方向,是最能显示特征的一种绘制方式 |
Harris 算法实现步骤:
(1)计算图像在两个方向上的梯度
(2)计算两个方向梯度乘积
(3)使用高斯函数进行加权平均,生成矩阵元素和
(4)计算每个像素Harris响应值,并对小于某一个阈值的像素置0
(5)在阈值的邻域内进行非最大值抑制,局部最大值即为Harris角点Harris算法优劣:
(1)优点:计算简单,提取的特征点均匀且合理稳定(对图像旋转、亮度变化、噪声影响和视点变换不敏感);
(2)缺点:a.对尺度很敏感,不具有尺度不变性;b.提取的角点精度是像素级的;c.需要设计对应的描述子和匹配算法;
int main(){
cv::Mat image=cv::imread("1.png");
cv::Mat grayImage;
cv::cvtColor(image,grayImage,CV_BGR2GRAY);
cv::Mat dstImage;
cv::cornerHarris(grayImage,dstImage,2,3,0.01);
cv::imshow("直接显示",dstImage);
cv::Mat thredImage;
threshold(dstImage, thredImage, 0.0001, 255, CV_THRESH_BINARY);
imshow("【阀值后显示】", thredImage);
cv::waitKey();
return 0;
}
绘制匹配点
void cv::drawMatches (
InputArray img1,
const std::vector< KeyPoint > & keypoints1,
InputArray img2,
const std::vector< KeyPoint > & keypoints2,
const std::vector< DMatch > & matches1to2,
InputOutputArray outImg,
const Scalar & matchColor = Scalar::all(-1),
const Scalar & singlePointColor = Scalar::all(-1),
const std::vector< char > & matchesMask = std::vector< char >(),
DrawMatchesFlags flags = DrawMatchesFlags::DEFAULT
)- img1:第一个源图像,
- keypoints1:第一个源图像的关键点,
- img2:第二个源图像,
- keypoints2:第二个源图像的关键点,
- matches1to2:从第一张图像匹配到第二张图像,
- outimg: 输出图像。它的内容取决于定义在输出图像中绘制的内容的标志值,
- matchColor:匹配的颜色(线和连接的关键点),
- singlePointColor:单个关键点(圆圈)的颜色,表示关键点不匹配,
- matchesMask:确定绘制哪些匹配项的掩码。如果掩码为空,则绘制所有匹配项。
- flags:标志设置绘图功能
SIFT特征点检测
SIFT综述
尺度不变特征转换(SIFT)是一种电脑视觉的算法用来侦测与描述影像中的局部性特征,它在空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变量,此算法由 David Lowe在1999年所发表,2004年完善总结。
Lowe将SIFT算法分解为如下四步:
- 尺度空间极值检测:搜索所有尺度上的图像位置。通过高斯微分函数来识别潜在的对于尺度和旋转不变的兴趣点。
- 关键点定位:在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。
- 方向确定:基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。
- 关键点描述:在每个关键点周围的邻域内,在选定的尺度上测量图像局部的梯度。这些梯度被变换成一种表示,这种表示允许比较大的局部形状的变形和光照变化。
SIFT算法的OpenCV实现
OpenCV中的SIFT函数主要有两个接口。
构造函数:
SIFT::SIFT(int nfeatures=0, int nOctaveLayers=3, double contrastThreshold=0.04, double
edgeThreshold=10, double sigma=1.6) - nfeatures:特征点数目(算法对检测出的特征点排名,返回最好的nfeatures个特征点)。
- nOctaveLayers:金字塔中每组的层数(算法中会自己计算这个值,后面会介绍)。
- contrastThreshold:过滤掉较差的特征点的对阈值。contrastThreshold越大,返回的特征点越少。
- edgeThreshold:过滤掉边缘效应的阈值。edgeThreshold越大,特征点越多(被多滤掉的越少)。
- sigma:金字塔第0层图像高斯滤波系数,也就是σ。
重载操作符:
void SIFT::operator()(InputArray img, InputArray mask, vector<KeyPoint>& keypoints,
OutputArray
descriptors, bool useProvidedKeypoints=false) - img:8bit灰度图像 mask:图像检测区域(可选)
- keypoints:特征向量矩阵
- descipotors:特征点描述的输出向量(如果不需要输出,需要传cv::noArray())。
- useProvidedKeypoints:是否进行特征点检测。ture,则检测特征点;false,只计算图像特征描述。
SURF特征
SURF(Speeded Up Robust Features)是对SIFT的一种改进,主要特点是快速。SURF与SIFT主要有以下几点不同处理:
1、SIFT在构造DOG金字塔以及求DOG局部空间极值比较耗时,SURF的改进是使用Hessian矩阵变换图像,极值的检测只需计算Hessian矩阵行列式,作为进一步优化,使用一个简单的方程可以求出Hessian行列式近似值,使用盒状模糊滤波(box blur)求高斯模糊近似值。
2、 SURF不使用降采样,通过保持图像大小不变,但改变盒状滤波器的大小来构建尺度金字塔。
3、在计算关键点主方向以及关键点周边像素方向的方法上,SURF不使用直方图统计,而是使用哈尔(haar)小波转换。SIFT的KPD达到128维,导致KPD的比较耗时,SURF使用哈尔(haar)小波转换得到的方向,让SURF的KPD降到64维,减少了一半,提高了匹配速度
ORB特征
ORB特征由关键点和描述子两部分组成,关键点称为“Oriented FAST”,是一种改进的FAST 角点。它的描述子称为BRIEF(Binary Robust Independent Elementary Feature)。
提取 ORB 特征分为如下两个步骤:
- FAST 角点提取:找出图像中的“角点”。相较于原始的 FAST,ORB 中计算了特征点的主方向,为BRIEF 描述子增加了旋转不变特性。
- BRIEF 描述子的计算:对前一步提取出特征点的周围图像区域进行描述。ORB 对 BRIEF 进行了改进,主要是在BRIEF 中使用了先前计算的方向信息。
FAST关键点
FAST 是一种角点,主要检测局部像素灰度变化明显的地方,以速度快著称。它的思想是:如果一个像素与邻域的像素差别较大(过亮或过暗),那么它可能是角点。检测步骤如下:
- 在图像中选取像素 p,假设它的亮度为Ip。
- 设置一个阈值 T(比如,Ip的20%)。
- 以像素 p 为中心,选取半径为3的圆上的16个像素点。
- 假如选取的圆上有连续的 N 个点的亮度大于 Ip+T 或小于 Ip−T,那么像素p 可以被认为是特征点(N通常取12,即为 FAST-12。其他常用的N取值为9和11,它们分别被称为FAST-9和FAST-11)。
- 循环以上四步,对每一个像素执行相同的操作。
在FAST-12算法中,可以进行预测试操作,以快速地排除绝大多数不是角点的像素。
具体操作为,对于每个像素,直接检测邻域圆上的第 1, 5, 9, 13 个像素的亮度。只有当这 4个像素中有 3 个同时大于 Ip+T或小于 Ip−T 时,当前像素才有可能是一个角点,否则应该直接排除。这大大加速了角点检测。
还需要用非极大值抑制(Non-maximal suppression),在一定区域内仅保留响应极大值的角点,避免角点集中的问题。

FAST特征点的计算仅仅是比较像素间亮度的差异,所以速度非常快。它的缺点是重复性不强,分布不均匀,不具有方向信息。同时,由于它固定取半径为3的圆,存在尺度问题:远处看着像是角点的地方,接近后看可能就不是角点了。
针对 FAST 角点不具有方向性和尺度的弱点,ORB添加了尺度和旋转的描述。尺度不变性由构建图像金字塔解决,在金字塔的每一层上检测角点。特征的旋转是由灰度质心法(Intensity Centroid)实现。
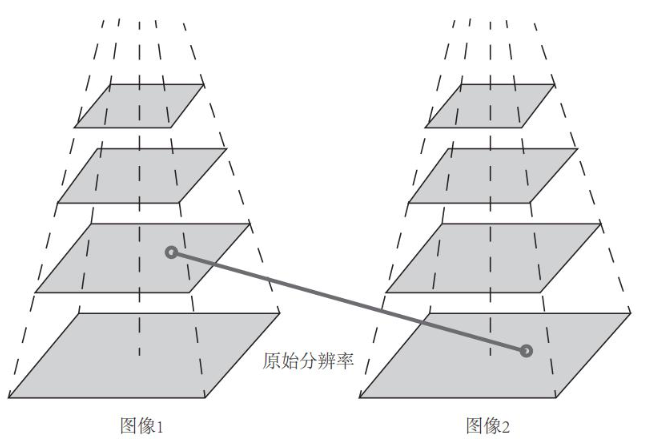
图像金字塔如上图,金字塔底层是原始图像,每往上一层,就对图像进行一个固定倍率的缩放,这样就有了不同分辨率的图像。较小的图像可以看成是远处看过来的场景。在特征匹配算法中,我们可以匹配不同层上的图像,从而实现尺度不变性。例如,如果相机在后退,那么我们应该能够在上一个图像金字塔的上层和下一个图像的下层中找到匹配。

通过以上方法,FAST 角点便具有了尺度与旋转的描述,从而大大提升了其在不同图像之间表述的鲁棒性。所以在 ORB中,把这种改进后的 FAST 称为 Oriented FAST。
BRIEF描述子
在提取 Oriented FAST 关键点后,对每个点计算其描述子,ORB 使用改进的BRIEF特征描述。BRIEF 是一种二进制描述子,其描述向量由许多个 0 和 1 组成,这里的 0 和 1 编码了关键点附近两个随机像素(比如p和q)的大小关系:如果p 比 q 大,则取 1,反之就取 0。如果我们取了 128个这样的 p, q,最后就得到 128 维由 0、1 组成的向量。关于一对随机点的选择方法,ORB论文原作者测试了以下5种方法,发现方法(2)比较好:

原始的 BRIEF 描述子不具有旋转不变性,因此在图像发生旋转时容易丢失。而 ORB 在 FAST 特征点提取阶段计算了关键点的方向,所以可以利用方向信息,计算了旋转之后的“Steer BRIEF”特征使 ORB 的描述子具有较好的旋转不变性。
ORB类定义
CV_WRAP static Ptr<ORB> create(int nfeatures=500, float scaleFactor=1.2f, int nlevels=8, int edgeThreshold=31,
int firstLevel=0, int WTA_K=2, int scoreType=ORB::HARRIS_SCORE, int patchSize=31, int fastThreshold=20);其中:
- nfeatures:需要的特征点总数;
- scaleFactor:尺度因子;
- nlevels:金字塔层数;
- edgeThreshold:边界阈值;
- firstLevel:起始层;
- WTA_K:描述子形成方法,WTA_K=2表示,采用两两比较;
- scoreType:角点响应函数,可以选择Harris或者Fast的方法;
- patchSize:特征点邻域大小
int main(){
cv::Mat image=cv::imread("1.jpg");
cv::Mat grayImage;
cv::cvtColor(image,grayImage,CV_BGR2GRAY);
vector<KeyPoint> keypoints_1;
Mat descriptors_1;
Ptr<FeatureDetector> detector = ORB::create();
Ptr<DescriptorExtractor> descriptor = ORB::create();
//-- 第一步:检测 Oriented FAST 角点位置
detector->detect ( grayImage,keypoints_1 );
//-- 第二步:根据角点位置计算 BRIEF 描述子
descriptor->compute ( grayImage, keypoints_1, descriptors_1 );
Mat outimg1;
Mat outimg2;
//-- 第三步:显示特征点
drawKeypoints( grayImage, keypoints_1, outimg1, Scalar::all(-1), DrawMatchesFlags::DEFAULT );
drawKeypoints( grayImage, keypoints_1, outimg2, Scalar::all(-1), DrawMatchesFlags::DRAW_RICH_KEYPOINTS );
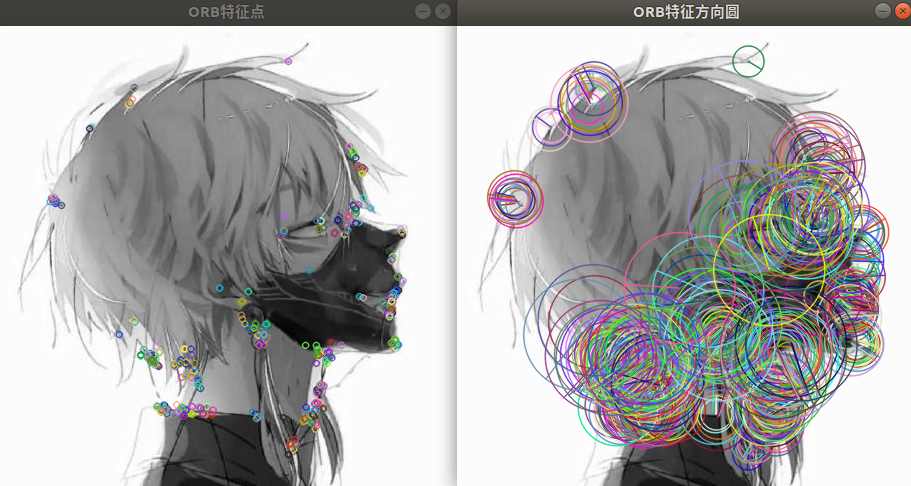
imshow("ORB特征点",outimg1);
imshow("ORB特征方向圆",outimg2);
cv::waitKey();
return 0;
}
特征提取及形成描述子
void ORB::operator()( InputArray _image, InputArray _mask, vector<KeyPoint>& _keypoints,
OutputArray _descriptors, bool useProvidedKeypoints)
- _image:输入图像;
- _mask:掩码图像;
- _keypoints:输入角点;
- _descriptors:如果为空,只寻找特征点,不计算特征描述子;
- _useProvidedKeypoints:如果为true,函数只计算特征描述子
#include <iostream>
#include <chrono>
using namespace std;
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
int main ( int argc, char** argv )
{
// 读取argv[1]指定的图像
cv::Mat image;
image = cv::imread ( argv[1] );
// 判断图像文件是否正确读取
if ( image.data == nullptr ) //数据不存在,可能是文件不存在
{
cerr<<"文件"<<argv[1]<<"不存在."<<endl;
return 0;
}
// 文件顺利读取, 首先输出一些基本信息 H*W rows*cols
cout<<"图像宽为"<<image.cols<<",高为"<<image.rows<<",通道数为"<<image.channels()<<endl;
cv::imshow ( "image", image ); // 用cv::imshow显示图像
cv::waitKey ( 0 ); // 暂停程序,等待一个按键输入
// 判断image的类型
if ( image.type() != CV_8UC1 && image.type() != CV_8UC3 )
{
// 图像类型不符合要求
cout<<"请输入一张彩色图或灰度图."<<endl;
return 0;
}
// 遍历图像, 请注意以下遍历方式亦可使用于随机像素访问
// 使用 std::chrono 来给算法计时
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
for ( size_t y=0; y<image.rows; y++ )
{
// 用cv::Mat::ptr获得图像的行指针
unsigned char* row_ptr = image.ptr<unsigned char> ( y ); // row_ptr是第y行的头指针
for ( size_t x=0; x<image.cols; x++ )
{
// 访问位于 x,y 处的像素
unsigned char* data_ptr = &row_ptr[ x*image.channels() ]; // data_ptr 指向待访问的像素数据
// 输出该像素的每个通道,如果是灰度图就只有一个通道
for ( int c = 0; c != image.channels(); c++ )
{
unsigned char data = data_ptr[c]; // data为I(x,y)第c个通道的值
}
}
}
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
chrono::duration<double> time_used = chrono::duration_cast<chrono::duration<double>>( t2-t1 );
cout<<"遍历图像用时:"<<time_used.count()<<" 秒。"<<endl;
// 关于 cv::Mat 的拷贝
// 直接赋值并不会拷贝数据
cv::Mat image_another = image;
// 修改 image_another 会导致 image 发生变化
image_another ( cv::Rect ( 0,0,100,100 ) ).setTo ( 0 ); // 将左上角100*100的块置零
cv::imshow ( "image", image );
cv::waitKey ( 0 );
// 使用clone函数来拷贝数据
cv::Mat image_clone = image.clone();
image_clone ( cv::Rect ( 0,0,100,100 ) ).setTo ( 255 );
cv::imshow ( "image", image );
cv::imshow ( "image_clone", image_clone );
cv::waitKey ( 0 );
// 对于图像还有很多基本的操作,如剪切,旋转,缩放等,限于篇幅就不一一介绍了,请参看OpenCV官方文档查询每个函数的调用方法.
cv::destroyAllWindows();
return 0;
}
cmake_minimum_required( VERSION 2.8 )
project( imageBasics )
# 添加c++ 11标准支持
set( CMAKE_CXX_FLAGS "-std=c++11" )
# 寻找OpenCV库
set(OpenCV_DIR ~/ssd/software/opencv3.3.1/build) #添加OpenCVConfig.cmake的搜索路径
find_package( OpenCV 3 REQUIRED )
# 添加头文件
include_directories( ${OpenCV_INCLUDE_DIRS} )
add_executable( imageBasics imageBasics.cpp )
# 链接OpenCV库
target_link_libraries( imageBasics ${OpenCV_LIBS} ) 


