语义场景补全(SSC)相关文章与数据集总结
首先附上链接
SSC
- NDC-Scene: Boost Monocular 3D Semantic Scene Completion in Normalized Device Coordinates Space, ICCV 2023.
- OG: Equip vision occupancy with instance segmentation and visual grounding, arXiv 2023.
- FB-OCC: 3D Occupancy Prediction based on Forward-Backward View Transformation, CVPRW 2023.
- Symphonize 3D Semantic Scene Completion with Contextual Instance Queries, arXiv 2023.
- OVO: Open-Vocabulary Occupancy, arXiv 2023.
- OccNet: Scene as Occupancy, ICCV 2023.
- SceneRF: Self-Supervised Monocular 3D Scene Reconstruction with Radiance Fields, ICCV 2023.
- Behind the Scenes: Density Fields for Single View Reconstruction, CVPR 2023.
- Semantic Scene Completion from a Single Depth Image, CVPR 2017
- LMSCNet: Lightweight Multiscale 3D Semantic Completion, 3DV 2020
- MonoScene: Monocular 3D Semantic Scene Completion, CVPR 2022
- StereoScene: BEV-Assisted Stereo Matching Empowers 3D Semantic Scene Completion, arXiv 2023.
- OccDepth: A Depth-aware Method for 3D Semantic Occupancy Network, arXiv 2023.
- VoxFormer: a Cutting-edge Baseline for 3D Semantic Occupancy Prediction, CVPR 2023
- TPVFormer: An academic alternative to Tesla’s Occupancy Network, CVPR2023
- OccFormer: Dual-path Transformer for Vision-based 3D Semantic Occupancy Prediction, ICCV 2023
- SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving, ICCV 2023
- S4C: Self-Supervised Semantic Scene Completion with Neural Fields, arXiv 2023
- PanoOcc: Unified Occupancy Representation for Camera-based 3D Panoptic Segmentation, arXiv 2023.
- PointOcc: Cylindrical Tri-Perspective View for Point-based 3D Semantic Occupancy Prediction, arXiv 2023.
- RenderOcc: Vision-Centric 3D Occupancy Prediction with 2D Rendering Supervision, arXiv 2023.
相关 Dataset/Benchmark
- PointSSC: A Cooperative Vehicle-Infrastructure Point Cloud Benchmark for Semantic Scene Completion, arXiv 2023.
- Occ3D: A Large-Scale 3D Occupancy Prediction Benchmark for Autonomous Driving, arXiv 2023
- OpenOccupancy: A Large Scale Benchmark for Surrounding Semantic Occupancy Perception, ICCV 2023
- Occ4cast: LiDAR-based 4D Occupancy Completion and Forecasting, arXiv 2023.
- OccNet: Scene as Occupancy, ICCV 2023.
- SSCBench: A Large-Scale 3D Semantic Scene Completion Benchmark for Autonomous Driving, arXiv 2023.
我们从SSCBench数据集开始介绍起
SSCBench: A Large-Scale 3D Semantic Scene Completion Benchmark for Autonomous Driving
SSCBench提供的数据集格式与SemanticKITTI兼容,这是一个综合了 KITTI-360 、nuScenes和Waymo 中的场景的全面基准,总体而言,我们的SSCBench由三个子集组成,包括38562帧用于训练,15798帧用于验证,12553帧用于测试,总计66913帧(~67K),大大超过了上述SemanticKITTI的规模~7.7倍。SSCBench 便于在各种实际场景中轻松探索基于摄像头和LiDAR的SSC。
相关工作
- 单眼感知和3D语义场景完成。单眼相机的简单性、效率、可负担性和可访问性使单眼感知成为视觉和机器人界关注的焦点。SSCNet(2017)引入了单目3D语义场景完成(SSC)的概念,该概念旨在从单个深度图像重建和完成3D体积内的语义和几何结构。然而,由于缺乏室外数据集,他们只考虑有界的室内场景。Semantickitti(2019)构建了第一个基于KITTI的户外数据集,用于街景中的3D语义场景完成。现有的方法通常依赖于3D输入,如激光雷达点云(Lmscnet,2020;S3CNet,2021a;JS3C-Net,2021),而最近的基于单目视觉的解决方案也出现了(Monoscene,2022;Voxformer,2023),双目视觉的解决方案也出现了(OccDepth,2021)。然而,户外SSC的发展受到数据集缺乏的阻碍,SemanticKITTI(Behley et al.,2019)是唯一支持街景SSC的数据集。构建多样化的数据集对于释放SSC在自主系统中的全部潜力至关重要。
- 街景中的点云分割。3D激光雷达分割旨在为点云分配逐点语义标签,在这一领域,源于PointNet++(2017)的基于点的方法在小型合成点云上表现良好。基于体素的方法通过最初通过笛卡尔坐标将3D空间划分为体素来处理点云。注意,3D激光雷达分割旨在基于原始激光雷达扫描对场景进行分类和理解,而3D语义场景完成包括在相机或激光雷达的输入下完成遮挡区域。
- 自动驾驶数据集和基准。自动驾驶研究在高质量数据集上蓬勃发展,这些数据集是训练和评估感知、预测和规划算法的生命线。2012年,开创性的KITTI数据集引发了自动驾驶研究的一场革命,开启了包括物体检测、跟踪、映射和光学/深度估计在内的多项任务。从那时起,研究界接受了这一挑战,产生了丰富的数据集。这些数据集通过应对多模式融合、多任务学习、恶劣天气、协同驾驶、重复驾驶,以及密集交通场景等。有几个有影响力且广泛使用的驾驶数据集,如KITTI-360(2022)、nuScenes(2020)和Waymo(2017)。它们提供了激光雷达和相机记录以及点云语义和边界注释,因此,我们可以通过聚合多个语义点云并利用3D框来处理动态对象,为SSC创建准确的地面实况标签。
介绍SSCNet
本文的重点是语义场景补全,这是一个任务,从单视图深度地图观察生成一个完整的三维体素表示的体积占用和语义标签的场景。之前的工作分别考虑了场景补全和深度地图的语义标记。然而,我们注意到这两个问题是紧密联系在一起的。为了利用这两个任务的耦合特性,我们引入了语义场景完成网络(SSCNet),这是一个端到端3D卷积网络,以单个深度图像作为输入,并同时输出相机视图截锥中所有体素的占用率和语义标签。我们的网络使用了一个基于扩张的3D上下文模块,以有效地扩展接受域,使3D上下文学习成为可能。为了训练我们的网络,我们构建了SUNCG——一个人工创建的大规模合成3D场景数据集,包含密集的体积标注。我们的实验表明,联合模型在语义场景完成任务方面优于单独处理每个任务的方法和替代方法。数据集、代码和经过训练的模型将在接受后在线提供。

语义场景补全网络(SSCNet),SSCNet [36] 是第一个将语义分割和场景完成与 3D CNN 端到端结合的工作。这是一种端到端的3D卷积网络,它以单个深度图像为输入,同时输出相机视图截头体中所有体素的占用和语义标签。网络使用基于扩张的3D上下文模块来有效地扩展感受野并实现3D上下文学习。
数据编码(第3.1节)、网络架构(第3.2节)和训练数据生成(第4节)。
- 数据编码。采用截断有符号距离函数(TSDF)对三维空间进行编码,其中每个体素都存储到其最近表面的距离值d,该值的符号表示体素是在自由空间中还是在遮挡空间中。对标准TSDF进行了以下修改:(1)消除视图相关性:选择计算到整个观测表面上任何地方最近点的距离。(2)消除空位中的强梯度,使用flipped TSDF(翻转的TSDF)
- 网络架构。网络以高分辨率三维体积为输入,首先使用几个三维卷积层来学习局部几何表示。我们使用带有步长和池化层的卷积层,将分辨率降低到原始输入的四分之一。然后,我们使用基于膨胀的3D上下文模块来捕获更高级别的对象间上下文信息。之后,来自不同尺度的网络响应被连接并馈送到另外两个卷积层中,以聚合来自多个尺度的信息。最后,使用体素方向的softmax层来预测最终的体素标签。
- 训练数据生成。SUNCG:一个大型合成场景数据集。SUNCG数据集包含45622个不同的场景,这些场景具有通过Planner5D平台手动创建的逼真的房间和家具布局[25]。有49884个有效楼层,包含404058个房间和5697217个对象实例,这些实例来自2644个覆盖84个类别的唯一对象网格。为了生成模拟典型图像捕获过程的合成深度图,我们使用一组简单的启发式方法来拾取相机视点。给定一个3D场景,我们从地板上间隔1米且不被物体占据的位置的统一网格开始。然后,我们根据NYU Depth v2数据集的分布选择相机姿势。1然后,我们使用Kinect的内部特性和分辨率渲染深度图。之后,我们使用一组简单的启发式方法来排除不好的观点。SUNCG数据集中的3D场景由有限数量的对象实例组成,我们通过首先对库中的每个单独对象进行体素化,然后根据每个场景配置和视点变换标签来加快体素化过程
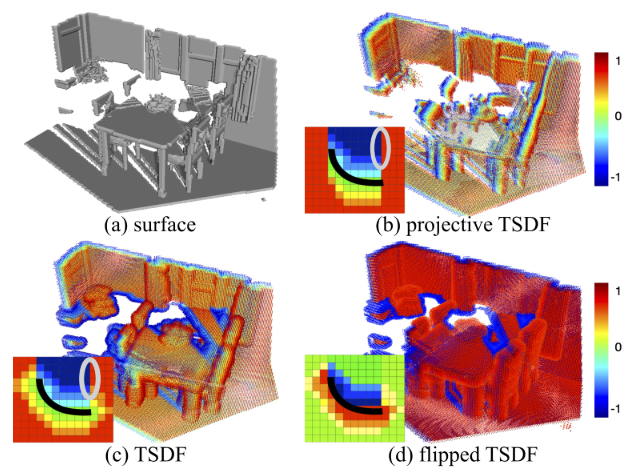
上图显示表面(a)的不同编码。投影TSDF (b)是根据相机计算的,因此是视景相关的。准确的TSDF (c)具有较少的视图依赖性,但在沿着遮挡边界的空空间中显示出强烈的梯度(用灰色圈出)。相反,翻转TSDF (d)在近地表有最强的梯度。
上图显示合成训练数据。我们收集了一个大规模的合成三维场景数据集来训练我们的网络。对于每个3D场景,我们选择一组摄像机位置,并生成成对的渲染深度图像和体积地面真实作为训练示例。
介绍LMSCNet
一种从体素化稀疏三维激光雷达扫描中完成多尺度三维语义场景的新方法。与文献相反,我们使用具有全面多尺度跳跃连接的2D UNet主干来增强特征流,以及3D分割头。在SemanticKITTI基准测试中,与所有其他已发布的方法相比,我们的方法在语义完成方面表现相当,在占用完成方面表现更好,同时明显更轻、更快。
方法
我们解决密集 3D 语义完成的问题,其中的任务是为每个单独的体素分配语义标签。给定稀疏 3D 体素网格,目标是预测 3D 语义场景表示,其中每个体素被分配一个语义标签 C = [c0, c1, … 。 。 , cN],其中 N 是语义类别的数量,c0 代表自由体素。我们的架构称为 LMSCNet,如下图所示,使用轻量级 UNet 风格架构来预测多个尺度的 3D 语义完成,允许快速粗略推理,有利于移动机器人应用。我们主要沿高度轴使用 2D 卷积,而不是贪婪的 3D 卷积;类似于鸟瞰图。下面我们详细介绍我们的定制轻量级 2D/3D 架构、多尺度重建和整体训练流程
!["LMSCNet:轻量级多尺度语义完成网络。我们的管道使用具有 2D 主干卷积(蓝色)和 3D 分割头(灰色)的 UNet 架构来执行不同尺度的 3D 语义分割和完成,同时保持低复杂性。卷积参数显示为:(滤波器数量、内核大小和步幅)。请注意,我们有意降低 2D 特征维度并使用 Atrous 3D 卷积(来自 [26] 的 ASPP 块)来保持较低的推理复杂度。"](/pic/LMSCNet.png)
介绍S3CNet
主要贡献如下:(a)一种基于稀疏张量的神经网络架构,该架构能够有效地从稀疏的三维点云数据中学习特征,并联合解决耦合的场景完成和语义分割问题;(b) 一种新颖的几何感知三维张量分割损失;(c) 一种多视图融合和语义后处理策略,解决了远距离或遮挡区域和小尺寸对象的挑战。给定单个稀疏点云帧,我们的模型预测了一个密集的3D占用长方体,其中为每个体素单元分配了语义标签(如图1所示),生成了原始输入中不包含的3D环境的丰富信息,如激光雷达扫描之间的间隙、遮挡区域和未来场景。
利用逐点法向量作为几何特征编码来指导我们的模型根据对象的局部曲面凸性来填充间隙。我们还利用从球面范围图像计算的基于LiDAR的翻转截断有符号距离函数(fTSDF[5])作为空间编码,来区分场景的自由空间、占用空间和遮挡空间。至于未来的场景,由于这些区域远离车辆,主要是道路或其他形式的地形,我们提出了稀疏语义场景完成网络的2D变体,以支持通过与鸟瞰图(BEV)语义图预测的多视图融合来构建3D场景。为了解决稀疏性,我们利用Minkowski引擎[6],一个用于稀疏张量的自动微分库来构建我们的2D和3D语义场景完成网络。我们还采用了组合的几何启发语义分割损失来提高语义标签预测的准确性。
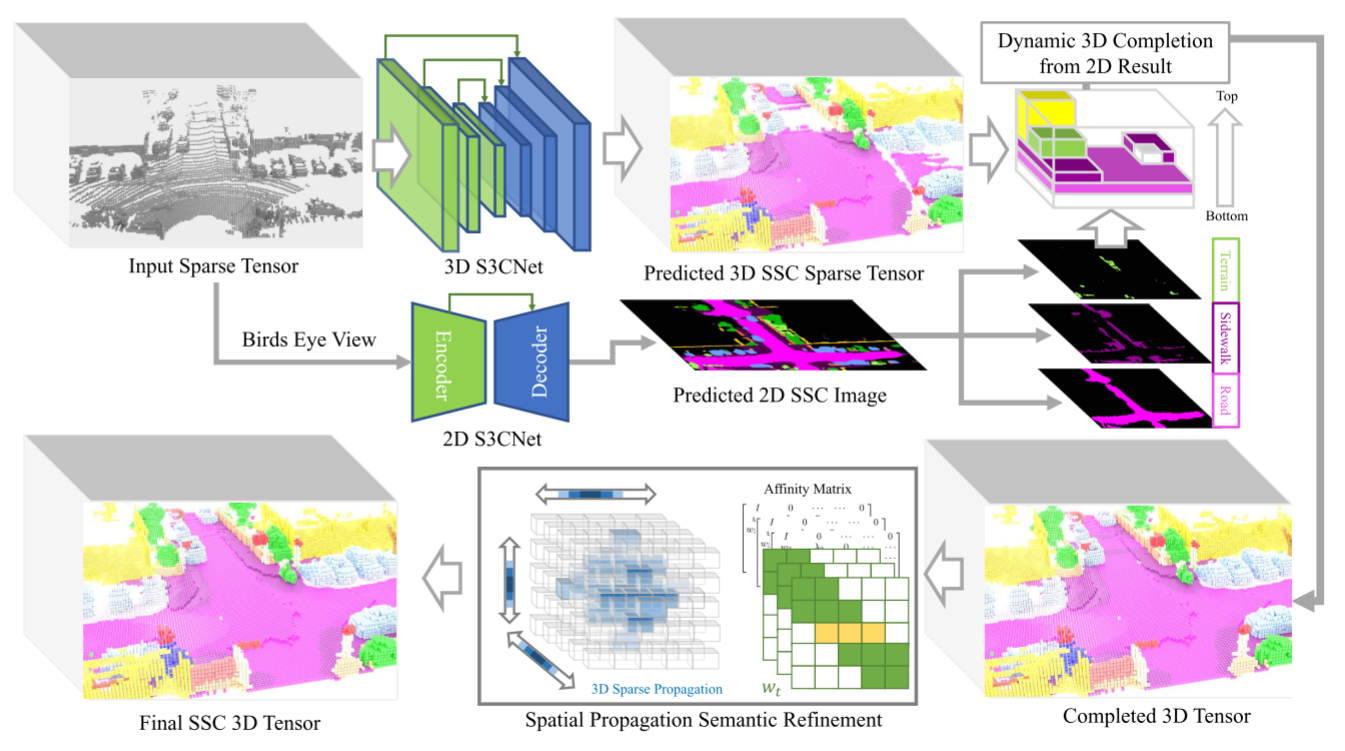
整个系统管道如图所示。从一次激光雷达扫描中,我们构建了两个稀疏张量,将场景封装为内存高效的2D和3D表示。每个张量通过其对应的语义场景完成网络,2D S3CNet或3D S3CNet,以在相应维度上语义地完成场景。我们提出了一种动态体素融合方法,用预测的2D语义BEV图进一步加密重建场景(详细讨论见第3.3节)。这抵消了对3D网络的显著内存需求——3D空间中的指数稀疏性增长使在一定范围内完成类变得困难。使用稀疏张量空间传播网络[30],我们细化融合2D-3D预测的噪声区域中的语义标签。
介绍JS3C-Net
提出了一种增强的联合单扫LiDAR点云语义分割方法,该方法利用学习的形状先验形式场景完成网络,即JS3C-Net。具体来说,通过在LiDAR序列中合并数十个连续帧,在没有额外标注的情况下,实现了一个大的完整点云作为语义场景完成(SSC)任务的地面真相。利用这些标注优化的SSC可以捕获引人注意的形状先验,使不完整的输入完整到带有语义标签的可接受形状(Song et al. 2017)。因此,完全端到端的训练策略使得完成的形状先验在本质上有利于语义分割(SS)。进一步提出了一个设计良好的点体素交互(PVI)模块,用于SS和SSC任务之间的隐式相互知识融合。具体来说,通过PVI模块,利用逐点分割和逐体补全来维护粗全局结构和细粒度局部几何。更重要的是,我们设计的SSC和PVI模块是一次性的。为了实现这一点,JS3C-Net以级联的方式将SS和SSC结合在一起,这意味着它不会影响SS的信息流,同时在推理阶段丢弃SSC和PVI模块。因此,它可以避免生成完整的高分辨率密集体而带来额外的计算负担。
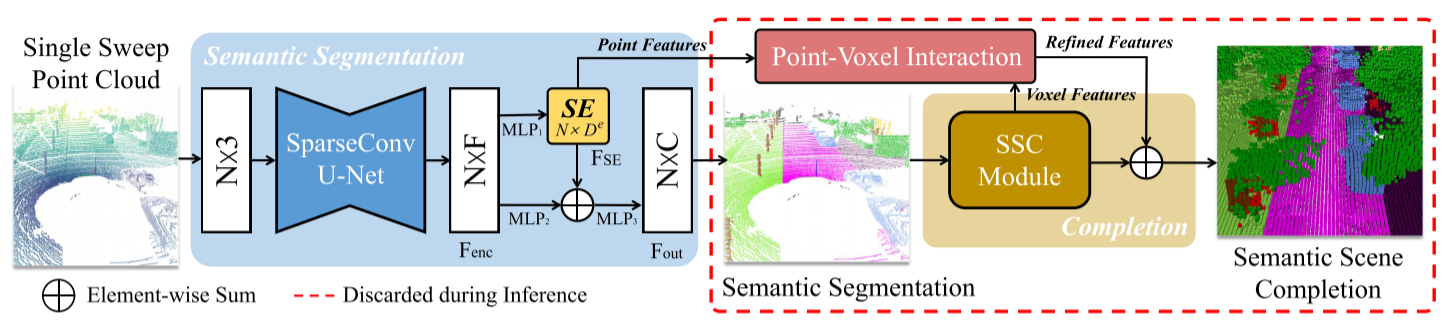
JS3C Net的总体管道。在给定稀疏不完全单扫描点云的情况下,首先使用稀疏卷积U-Net对Fenc进行点特征编码。基于初始编码,MLP1用于生成形状嵌入(SE)FSE,该FSE与通过MLP2传递的初始编码一起流入MLP3,以生成用于点云语义分割的Fout。然后,来自SE的不完整细粒度点特征和来自语义场景完成(SSC)模块的完整体素特征流入点-体素交互(PVI)模块,以实现细化特征,最终在监督下输出完成体素。请注意,SSC和PVI模块可以在推理过程中丢弃。
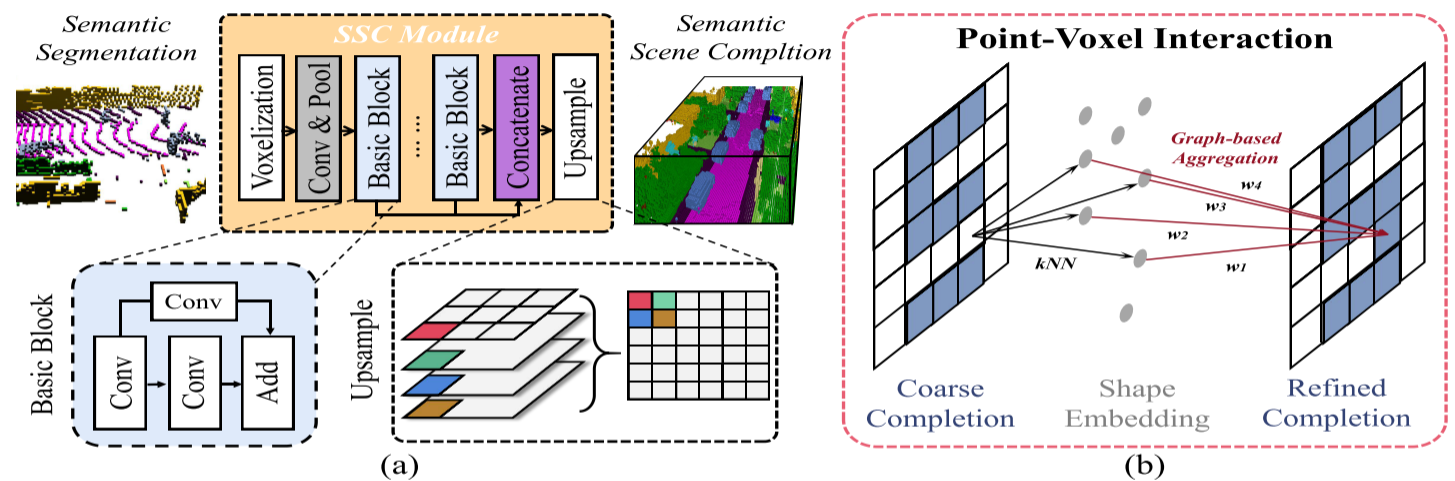
上图 (a)部分显示了SSC模块的内部结构,该模块以分割网络中的语义概率为输入,通过多个卷积块和密集的上样本生成完整体积。(b)部分演示了PVI模块的一个二维实例,该实例利用数字“5”的粗全局结构的中心点,从原始点云中查询k个最近邻,然后应用基于图的聚合,通过细粒度的局部几何实现完整的“5”。
MonoScene介绍
一种能在室内与室外场景均可使用的单目 SSC 方案:
- 提出一种将 2D 特征投影到 3D 的方法: FLoSP
- 提出一种 3D Context Relation Prior (3D CRP) 提升网络的上下文意识
- 新的SSC损失函数,用于优化场景类亲和力(affinity)和局部锥体(frustum)比例

Monoscene 网络流程
- 输入 2d 图片,经过 2d unet 提取多层次的特征
- Features Line of Sight Projection module (FLoSP) 用于将 2d 特征提升到 3d 位置上,增强信息流并实现2D-3D分离
- 3D Context Relation Prior (3D CRP) 用于增强长距离的上下文信息提取
- loss 优化:Scene-Class Affinity Loss:提升类内和类间的场景方面度量;Frustum Proportion Loss:对齐局部截头体中的类分布,提供超越场景遮挡的监督信息
网络结构
- 2D unet:EfficientNetB7 用于提取图像特征
- 3D UNets:2层 encoder-decoder 结构,用于提取 3d 特征
- completion head:3D ASPP 结构和 softmax 层,用于处理 3D UNet 输出得到3d场景 completion 结果
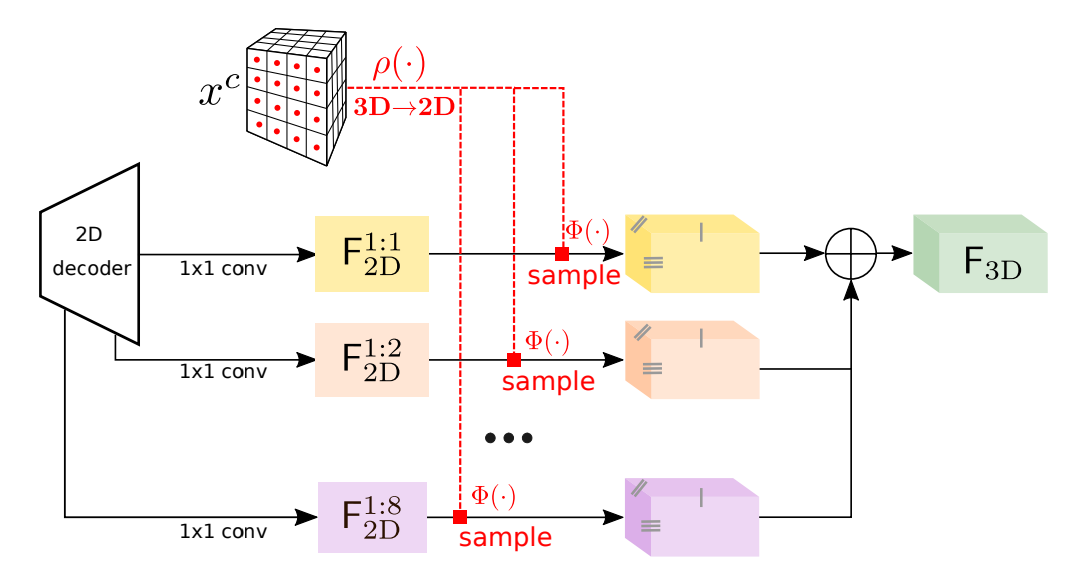
Features Line of Sight Projection (FLoSP)
从3维网络处理后者将为来自2维特征的集合提供线索。整个过程如下图所示,实际上假设已知相机内参,将3维体素中心投影到2维,从2维的解码器特征图采样得到对应特征,在所有尺度集合上进行重复,最终的3维特征图可用如下表示:
StereoScene介绍
3D语义场景补全(SSC)是一个需要从不完整观测中推断出密集3D场景的不适定问题。以往的方法要么明确地融合3D几何信息,要么依赖于从单目RGB图像中学习到的3D先验知识。然而,像LiDAR这样的3D传感器昂贵且具有侵入性,而单目相机由于固有的尺度模糊性而难以建模精确的几何信息。在这项工作中,研究者提出了StereoScene用于3D语义场景补全(SSC),它充分利用了轻量级相机输入而无需使用任何外部3D传感器。研究者的关键想法是利用立体匹配来解决几何模糊性问题。为了提高其在不匹配区域的鲁棒性,论文引入了鸟瞰图(BEV)表示法,以激发具有丰富上下文信息的未知区域预测能力。在立体匹配和BEV表示法的基础上,论文精心设计了一个相互交互聚合(MIA)模块,以充分发挥两者的作用,促进它们互补聚合。
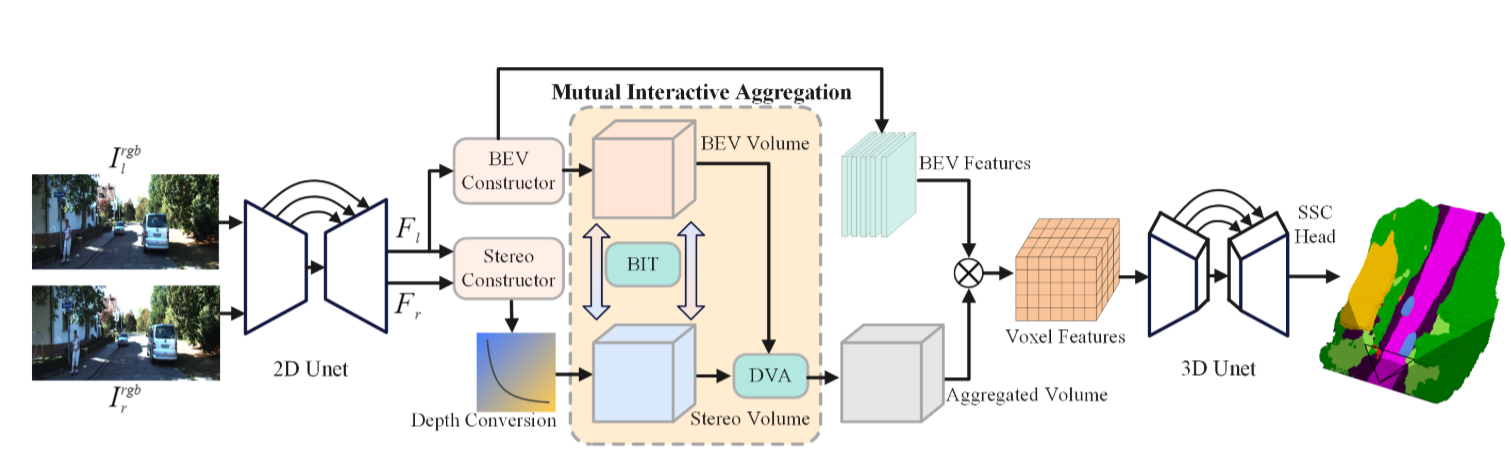
整体的StereoScene框架如上图所示。论文遵循使用连续的2D和3 UNetsf作为backbones。给定输入的双目图像,我们使用2D UNet来提取多尺度特征。BEV潜在体积和立体几何体积分别由BEV构造器和立体构造器构造。为了充分利用这两个卷的互补潜力,提出了一个相互交互聚合模块来相互引导和聚合它们。
介绍OccDepth
第一个只输入视觉的立体3D SSC方法。为了有效地利用深度信息,提出了一种立体软特征分配(Stereo-SFA)模块,通过隐式学习立体图像之间的相关性来更好地融合3D深度感知特征。占用感知深度(OAD)模块将知识提取与预先训练的深度模型明确地用于生成感知深度的3D特征。此外,为了更有效地验证立体输入场景,我们提出了基于TartanAir的SemanticTartanAir数据集。这是一个虚拟场景,可以使用真实的地面实况来更好地评估该方法的有效性。
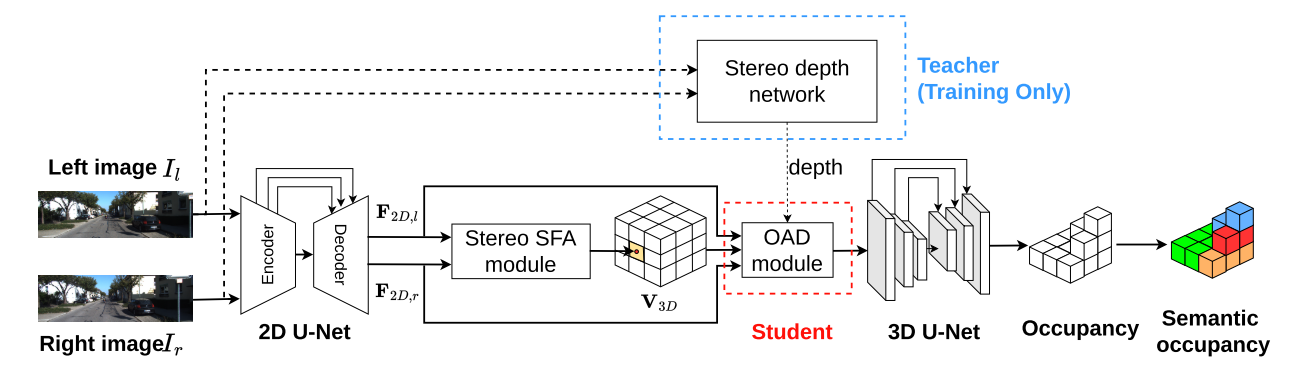
3D SSC是通过桥接立体SFA模块来从立体图像中推断出来的,该模块用于将特征提升到3D空间,OAD模块用于增强深度预测,3D U-Net用于提取几何结构和语义。立体深度网络仅在训练中用于提供深度监督。
介绍VoxFormer
一种基于 Transformer 的语义场景完成框架,可以仅从 2D 图像输出完整的 3D 体积语义。我们的框架采用两阶段设计,从深度估计中一组稀疏的可见和占用体素查询开始,然后是从稀疏体素生成密集 3D 体素的致密化阶段。这种设计的一个关键思想是,2D 图像上的视觉特征仅对应于可见的场景结构,而不对应于被遮挡或空白的空间。因此,从可见结构的特征化和预测开始更为可靠。一旦我们获得了稀疏查询集,我们就应用屏蔽自动编码器设计,通过自注意力将信息传播到所有体素。
VoxFormer由类不可知的查询建议(阶段-1)和类特定的语义分割(阶段-2)组成,其中阶段-1提出了一组稀疏的占用体素,阶段-2完成了从阶段-1给出的建议开始的场景表示。具体而言,阶段1具有轻量级的基于2D CNN的查询建议网络,该网络使用图像深度来重建场景几何结构。然后,它从整个视场上预定义的可学习体素查询中提出了一组稀疏的体素。第2阶段基于一种新颖的稀疏到密集类MAE架构,如图(a)所示。它首先通过允许所提出的体素关注图像观察来加强其特征化。接下来,未提出的体素将与可学习的掩码标记相关联,并且将通过自注意来处理全套体素,以完成每体素语义分割的场景表示。
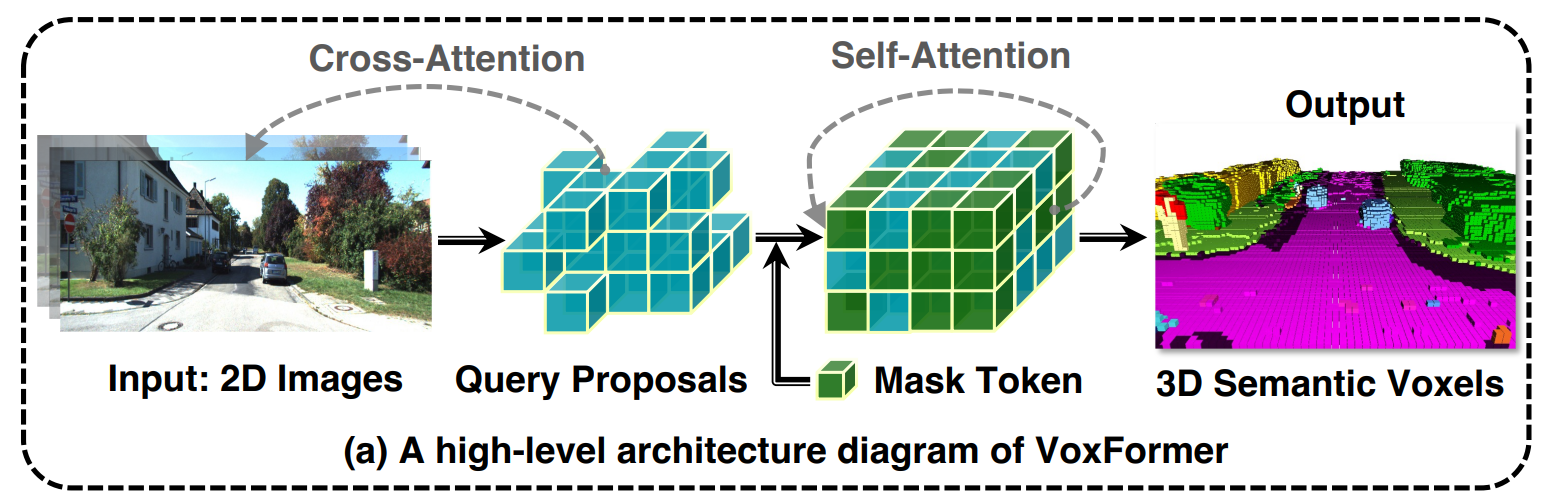
VoxFormer的总体框架如下图所示,给定RGB图像,通过ResNet50[61]提取2D特征,并通过现成的深度预测器估计深度。校正后的估计深度启用了类不可知查询建议阶段:将选择位于占用位置的查询,以与图像特征进行可变形的交叉关注。之后,将添加掩码令牌,用于通过可变形的自我注意来完成体素特征。细化的体素特征将被上采样并投影到输出空间,用于每个体素的语义分割。请注意,我们的框架支持单个或多个图像的输入。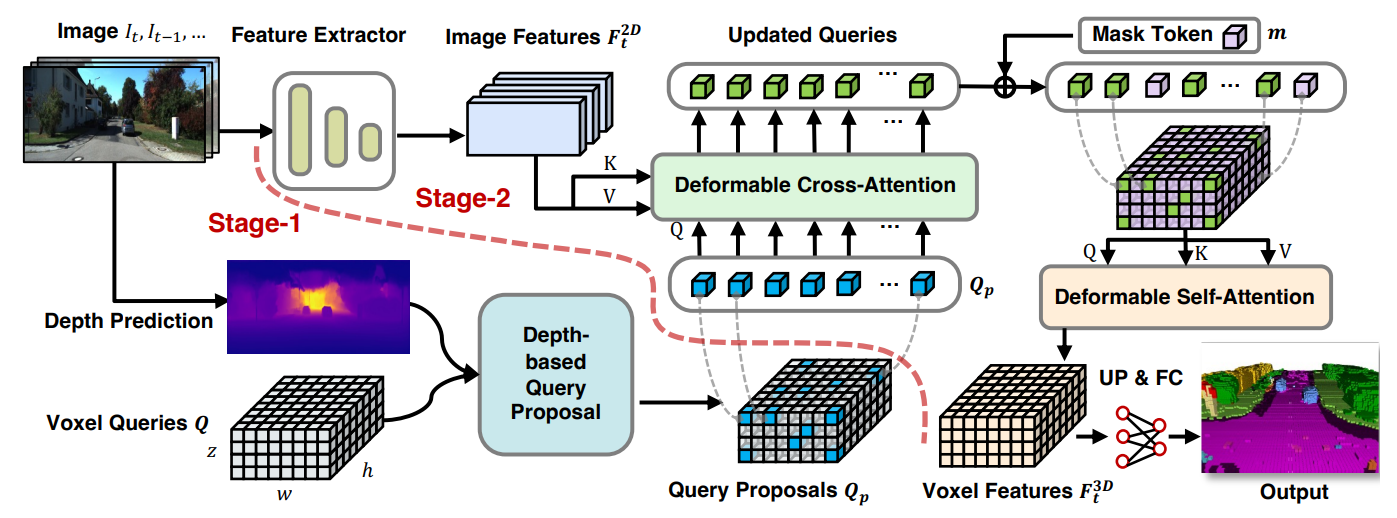
介绍OccFormer
提出了一种双路变压器网络OccFormer,该网络可以有效地处理三维体积进行语义占用预测。OccFormer实现了摄像机生成的3D体素特性的长程、动态和高效编码。它是通过将繁重的三维处理分解为局部和全局的变压器路径沿水平面得到的。在占位解码器中,我们将传统的Mask2Former用于3D语义占位,提出了保留池化和类引导采样,显著缓解了稀疏性和类的不平衡。
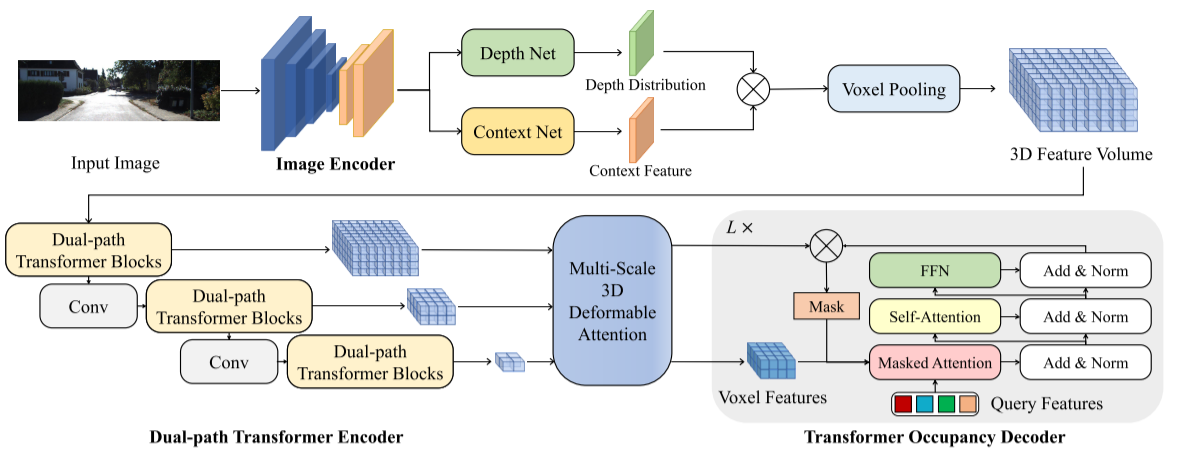
上图显示的为所提出的用于基于相机的3D语义占用预测的OccFormer的框架。该流水线由用于提取多尺度2D特征的图像编码器、用于将2D特征提升到3D体积的图像到3D变换以及用于获得3D语义特征并预测3D语义占用的基于变换器的编码器-解码器组成。
对于编码器部分:
我们提出了 dual-path transformer 模块,以释放 self-attention 的能力,同时限制了二次复杂性 (quadratic complexity)。
具体来说,
- local path 沿每个二维BEV切片运行,并使用共享窗口注意力 ( shared windowed attention) 来捕捉细粒度的细节。
- global path 对 collapsed 的BEV特征进行处理,以获得场景级的理解。
- 最后,双路径的输出被自适应地融合以生成输出的三维特征体 3D feature volume 。
双路径设计明显打破了三维特征体的挑战性处理,我们证明了它比传统的三维卷积有明显优势。
对于解码器部分:
我们是第一个将最先进的 Mask2Former[9] 方法用于三维语义占用预测的。
我们进一步提出使用最大池化而不是默认的双线性来计算 attention的 masked regions,这可以更好地保留小类。此外,我们还提出了 class-guided 的采样方法,以捕获前景区域,从而进行更有效的优化。
介绍S4CNet
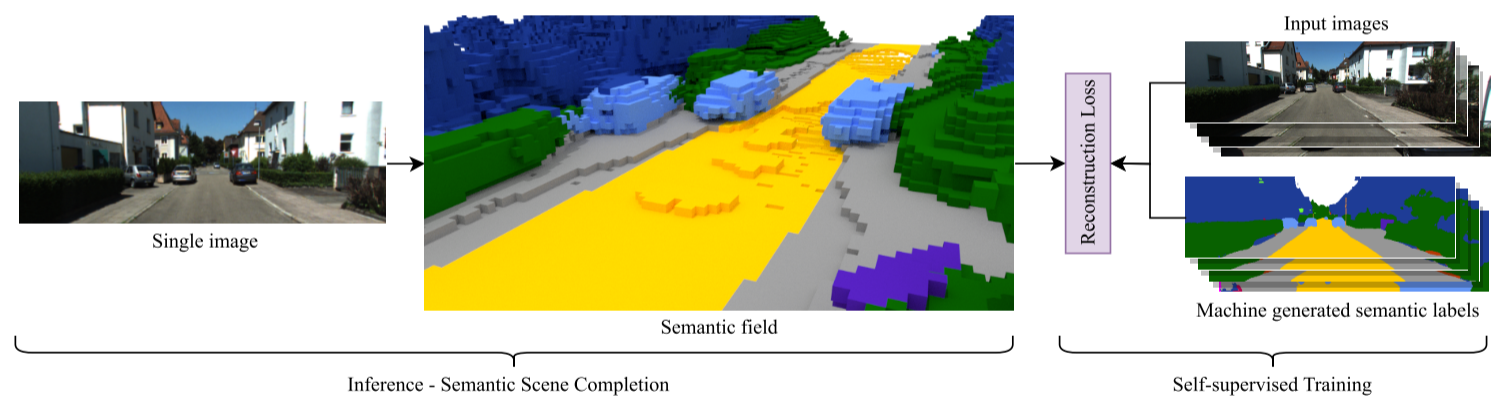
S4C是第一种完全自我监督的语义场景完成(SSC)方法,该方法仅基于图像数据(和相机姿势)进行训练。我们的方法从单个图像中预测体积场景表示,即使在遮挡区域中也能捕获几何和语义信息。与以前的SSC方法相比,我们不需要任何3D地面实况信息,允许使用仅图像的数据集进行训练。尽管缺乏基本事实数据,但我们的方法与性能差异很小的监督方法相比具有竞争力。
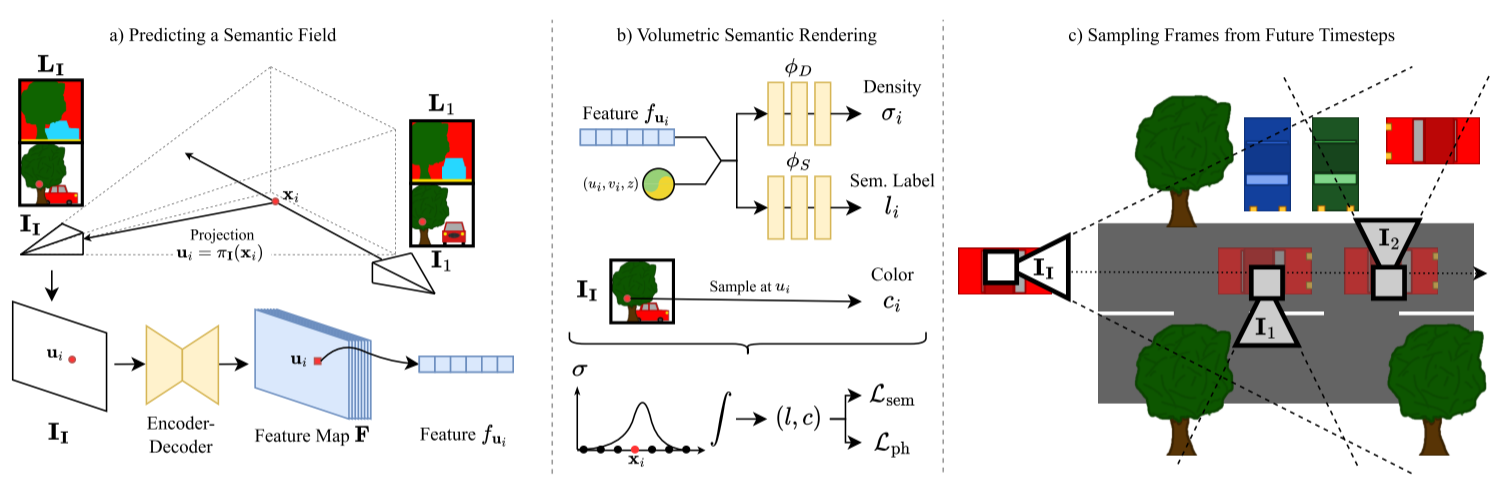
上图显示网络概述a) 根据输入图像II,编码器-解码器网络预测描述图像的截头体中的语义场的像素对齐特征图F。像素ui的特征fui对从光学中心通过像素投射的光线上的语义和占用分布进行编码。b) 语义场允许通过体积渲染来渲染新颖的视图及其相应的语义分割。将3D点xi投影到输入图像中,并因此将F投影到采样fui中。结合xi的位置编码,两个MLP分别对点σi和语义标签li的密度进行解码。用于新颖视图合成的颜色ci是通过颜色采样从其他图像中获得的。c) 为了获得最佳效果,我们要求训练视图覆盖尽可能多的场景表面。因此,我们从随机的未来时间步长中采样侧视图,这些时间步长观察在输入帧中被遮挡的场景区域。
语义多视图一致性训练
SSC的所有现有方法都依赖于3D地面实况数据进行训练。这些数据通常是从带注释的激光雷达扫描中获得的,这是非常困难和昂贵的。与3D数据相比,具有语义标签的图像是大量可用的。我们建议利用这些可用的2D数据来训练用于3D语义场景完成的神经网络。为了使我们的方法尽可能通用,我们使用从预先训练的语义分割网络生成的伪语义标签。这使我们能够以完全自我监督的方式,仅从姿势图像中训练我们的架构,而不需要2D或3D地面实况数据。
训练数据和目标:该方法的目标是进行语义场景完成,包括对3D场景的重建和分配语义标签。与传统方法不同,传统方法依赖于昂贵的从LiDAR扫描中获得的3D真实数据,这种方法旨在利用具有语义标签的2D图像数据的丰富性。作者建议使用从预训练的语义分割网络生成的伪语义标签来训练SSC的神经网络。这种方法允许在不需要2D或3D真实数据的情况下进行全面的自我监督训练。
数据来源:在自动驾驶场景中,汽车上装有多个摄像头,包括前置摄像头和侧置摄像头。该方法在多个时间步的视频序列中使用这些摄像头拍摄的多个构图图像进行训练。
训练目标:从这些帧中随机选择一部分作为新视图合成的重建目标。神经网络经过训练,可以根据其他帧的语义场和颜色样本来重建颜色信息和语义标签。
训练信号:训练信号是通过测量伪语义真值语义掩模和重建图像之间的差异生成的。这种差异用作训练期间的损失函数。
战略视图选择:为了确保有效的训练,选择训练视图是经过策略性考虑的。选择了带有与输入图像的随机偏移的侧置摄像视图。这些视图对于捕捉输入图像中被遮挡的区域提供了重要线索,为场景完成提供了重要线索。
重建块:只从不同帧中随机选择的块进行颜色(ˆPi,k)和语义标签(ˆSi)的重建。这种方法旨在进行高效的训练,同时确保神经网络学习了一般场景几何和特定对象的语义。
损失函数:进行SSC的训练涉及使用语义和光度重建损失的组合。光度损失有助于捕捉一般场景几何,而语义损失对于区分对象和学习粗略几何非常重要,并且引导模型学习物体周围更清晰的边缘。
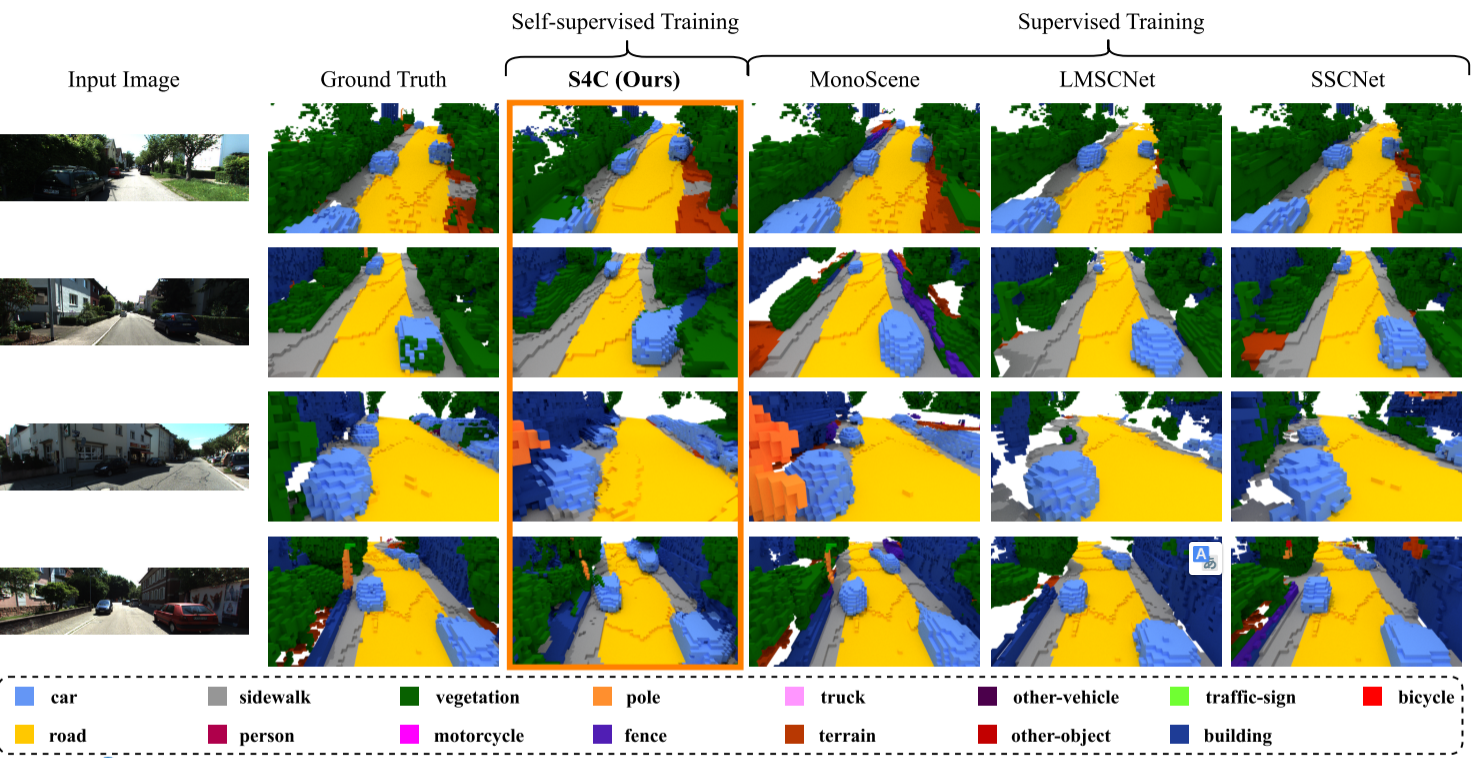
上图显示的是在SSCBench-KITTI-360预测体素网格。对占用图的定性评价表明,该方法能够准确地重建和标注场景。特别是与MonoScene等其他基于图像的方法相比,S4C能够恢复图像1中右侧车道等细节。S4C产生的体素占用显示出比基于激光雷达的训练更少的洞,后者再现了在地面上发现的洞。
与Occ3D,OpenOccupancy以及Occ4cast对比。
我们将SSCBench与同时进行的相关工作Occ3D进行了比较(Tian et al.,2023)。差异在于:
- (a)设置:Occ3D使用周围视图图像作为输入,并且只考虑相机可见的3D体素的重建。SSCBench考虑了一个更具挑战性但更有意义的设置(也是一个公认的设置):如何仅使用单眼视觉输入在可见和遮挡区域重建和完成3D语义。这项任务需要对时间信息和三维几何关系进行推理,以摆脱有限的视野;
- (b) 规模:SSCBench提供了比Occ3D更多的数据集,由于单目驾驶记录丰富,计划增加更多数据集;
- (c) 可访问性:我们继承了先驱KITTI广泛使用的设置,从而使SSCBench更容易被社区访问;
- (d) 全面性:我们将SSC方法与单目、三目和点云输入进行比较,并为跨领域泛化测试提供统一的标签。另一个相关的基准,OpenOccupancy(Wang et al.,2023),也表现出类似的差异,特别是它只使用了nuScenes数据集(Caesar et al.,2020),这导致了多样性的限制。
Occ4cast提出了一个新的LiDAR感知任务:将占用补全和预测Occupancy Completion and Forecasting(OCF)统一到一个框架中
主要贡献总结如下:
- 我们提出了OCF任务,该任务要求从稀疏的3D输入中获得时空密集的4D感知。
- 我们利用公共自动驾驶数据生成了一个名为OCFBench的大规模数据集。
- 我们提出了基线方法来处理OCF任务,并在我们的数据集上提供了详细的基准。
数据集介绍:
- SemanticKITTI:大规模的 LiDAR 点云标注数据集 SemanticKITTI,标注 28 类语义,共 22 个 sequences,43000 scans,不仅支持3D语义分割,而且是第一个户外SSC基准。一个明显的局限性是它在生成真值时遗漏了动态物体,导致了标签的不准确,产生痕迹。其次,它受到规模有限和缺乏多样化地理覆盖范围的限制,数据收集仅限于一个城市。
- SSCBench-KITTI-360。KITTI-360(Liao et al.,2022)在著名的KITTI数据集的基础上,引入了一个丰富的数据收集框架,具有不同的传感器模态和全景视点(一个透视立体相机和一对鱼眼相机),并提供了全面的注释,包括一致的2D和3D语义实例标签以及3D边界基元。密集和连贯的标签不仅支持分割和检测等既定任务,还支持语义SLAM(Bowman et al.,2017)和新视图合成(Zhang et al.,2023a)等新应用。虽然KITTI-360包括基于点云的语义场景完成,但SSC的流行方法仍然以体素化表示为中心(Roldao等人,2022),这在机器人技术中表现出更广泛的适用性。我们利用开源训练和验证集,我们构建了由9个长序列组成的SSCBench-KITTI-360。为了减少冗余,我们按照SemanticKITTI SSC基准,每5帧采样一次。训练集包括来自场景00、02-05、07和10的8487帧,而验证集包括来自情景06的1812帧。测试集包括来自场景09的2566帧。数据集总共包含12865(~13K)帧,比SemanticKITTI的规模高出约1.5倍。
- SSCBench-nuScenes。与KITTI的前置摄像头不同,nuScenes(Caesar et al.,2020)捕捉到了自我车辆周围的360度全景。它提供了各种各样的多模式传感数据,包括在波士顿和新加坡收集的相机图像、激光雷达点云和雷达数据。nuScenes为复杂的城市驾驶场景提供了细致的注释,包括不同的天气条件、施工区域和不同的照明。全景nuScenes(Fong et al.,2022)用语义和实例标签扩展了原始nuScene数据集。凭借全面的指标和评估协议,nuScenes在自动驾驶研究中得到了广泛应用(Gu et al.,2023;胡等人,2023,李等人,2021;Huang等人,2023.)。nuScenes数据集由1K 20秒的场景组成,其中仅为训练和验证集提供标签,共850个场景。从可用的850个场景中,我们分配了500个场景用于训练,200个场景用于验证,150个场景用于测试。这种分布导致20064帧用于训练,8050帧用于验证,5949帧用于测试,总计34078帧(~34K)。这个规模大约是SemanticKITTI的四倍。由于“nuScenes”仅为频率为2Hz的关键帧提供注释,因此在SSCBench“nuScene”中没有下采样。
- SSC Bench Waymo。Waymo数据集(Sun et al.,2020)收集自美国各地,提供了大规模的多模式传感器记录。Waymo提供了5台相机,其组合水平视场为~230度,略小于nuScenes。数据是在多个城市的不同条件下采集的,包括旧金山、凤凰城和山景城,确保了每个城市的广泛地理覆盖。它包括1000个用于训练和验证的场景,以及150个用于测试的场景,每个场景的时间跨度为20秒。评论为了构建SSCBench Waymo,我们利用开源训练和验证场景,并将它们重新分配到500、298和202个场景中,分别用于训练、验证和测试。为了减少基准测试的冗余和训练时间,我们将原始数据的样本减少了10倍。这种下采样产生了10011帧的训练集、5936帧的验证集和4038帧的测试集,总计19985帧(~20K)。
构建Pipeline
- 先决条件。为了建立SSCBench,基于激光雷达或基于相机的SSC需要具有多模式记录的驾驶数据集。数据集应包括顺序收集的3D激光雷达点云,具有用于完成几何图形的精确传感器姿态,用于理解语义场景的逐点语义注释,以及用于处理动态实例的3D边界注释。
- 点云聚合。为了生成完整的表示,我们的方法包括在车辆前方的定义区域内叠加一组广泛的激光扫描。在像nuScenes和Waymo这样的短序列中,我们利用未来的扫描和相应区域的测量来创建密集的语义点云。在像KITTI-360这样具有多个循环闭包的长序列中,除了时间邻域之外,我们还合并了所有空间相邻点云。先进的SLAM系统(Bailey&Durrant-White,2006)提供了精确的传感器姿态,极大地促进了静态环境中点云的聚集。对于动态对象,我们通过同步来避免时空管道。我们使用实例标签将动态对象转换为当前帧内的空间对齐。
- 聚合点云的Voxeization。体素化是将连续的3D空间离散为由称为体素的体积元素组成的规则网格结构,使非结构化数据能够转换为可由卷积神经网络(CNNs)或视觉变换器(ViTs)有效处理的结构化格式。Voxelization引入了空间分辨率和内存消耗之间的权衡,并为3D感知提供了灵活和可扩展的表示(Maturana&Scherer,2015;周和图泽尔,2018;李等人,2023)。为了便于集成,SSCBench遵循SemanticKITTI的设置,体积向前延伸51.2米,每侧延伸25.6米,高度为6.4米。体素分辨率为0.2m,产生256×256×32的体素体积。每个体素的标签由其内标记点的多数投票决定,而如果不存在点,则相应地标记空体素。
- 排除未知Voxels。如果没有无处不在的场景感知,捕捉完整的3D户外动态场景几乎是不可能的。虽然可以利用空间或先验知识推理,但我们的意图是通过最小化这些步骤产生的误差来确保基本事实的保真度。因此,在训练和评估过程中,我们只考虑来自所有视点的可见和探测体素。具体来说,我们首先从不同的角度使用光线跟踪来识别和去除物体内或墙后的遮挡体素。此外,在具有稀疏感测的数据集中,其中许多体素仍然没有被标记,我们在训练和评估期间去除这些未知体素,以增强基本事实标签的可靠性
讨论与分析
- 点云密度的影响。我们的实验阐明了激光雷达输入密度对模型性能的影响。在SSCBench nuScenes数据集中,其特征是相对稀疏的激光雷达输入(32个通道),基于相机的方法在几何度量上优于基于激光雷达的方法。然而,在SSCBench Waymo数据集中,得益于密集的激光雷达输入(64个通道,5个激光雷达),基于激光雷达的方法大大优于基于相机的方法。基于激光雷达的方法对输入的敏感性变得明显,在密集输入中观察到优势,而在稀疏输入中则观察到显著的性能下降。这突出了未来研究开发强大的基于激光雷达的方法的必要性,该方法可以在利用效益的同时减轻退化。
- 单眼与三眼。表3显示了具有单目和三目输入的TPVFormer的性能。而三眼设置提供了更宽的视野,有助于提高IoU的整体性能(36.78→ 39.06)和mIoU(10.91→ 13.70),仅使用一台相机就能获得优异的结果仍然是一个引人注目的学术挑战。开发能够将模型的性能与全景图相匹配的单目方法仍然具有重要的研究价值,因为它们具有内存高效、计算高效和易于部署的特点。
- 与SemanticKITTI的比较。当将我们在SSCBench上的实验结果与SemanticKITTI的实验结果进行比较时,我们观察到了显著的差异(Behley et al.,2019)(有关更多细节,我们请读者参阅VoxFormer(Li et al.,2023))。虽然VoxFormer在IoU和mIoU等指标上在SemanticKITTI上表现出色,但它面临着SSCBench数据集多样性的挑战。这一挑战主要源于其深度估计模块无法超越SemanticKITTI进行推广。此外,LMSCNet在SemanticKITTI上通常表现出优于SSCNet的几何性能,而在SSCBench上则表现出相反的趋势。这些差异强调了两个要点。首先,他们强调了SSCBench的重要性,它为全面评估提供了多样化和苛刻的现实世界场景。其次,他们强调了在各种环境中保持高性能的稳健方法的必要性。
结论
- 限制和未来工作。SSCBench仅包含符合SSC问题惯例的3D数据。这限制了对具有时间维度的4D方法的评估。未来的工作将旨在扩大SSCBench,以包括时间信息。
- 总结。在本文中,我们介绍了SSCBench,这是一个由不同街景组成的大型基准,旨在促进稳健和可推广的语义场景完成模型的开发。通过细致的策划和全面的基准测试,我们发现了现有方法的瓶颈,并为未来的研究方向提供了宝贵的见解。我们的目标是让SSCBench刺激3D语义场景完成的进步,最终增强下一代自主系统的感知能力。



