主要记录SSC中的理论与代码实现(第一章)
主要从开篇之作SSCNet(2017)开始讲起,然后按激光雷达点云输入(LMSCNet,2020;S3CNet,2021a;JS3C-Net,2021),单双目以及两者融合的顺序
首先是开篇之作SSCNet
官方代码实在caffe框架上搭建的,第一个将语义分割和场景完成与 3D CNN 端到端结合的工作,从单视图深度地图观察生成一个完整的三维体素表示的体积占用和语义标签的场景,利用这两个任务的耦合特性,引入了语义场景完成网络(SSCNet)
代码链接: SSCNet: Semantic Scene Completion from a Single Depth Image, 2017

代码:
使用Caffe框架的网络定义txt文件,主要包括下面几个部分:
- 数据层 (layer { name: “data” … }): 这是数据输入层,它从SUNCG数据集中加载数据。数据集包括深度信息(可能是三维数据)以及标签信息(seg_label)。还包括一些参数,如体素大小、裁剪大小、类别映射等。
- 卷积层 (layer { name: “conv1_1” … }): 这是一个卷积层,用于提取特征。它定义了卷积核的数量、大小、填充等参数。
- ReLU 层 (layer { name: “relu1_1” … }): 这是激活函数层,通常用于引入非线性性。ReLU(Rectified Linear Unit)是一种常见的激活函数。
- 池化层 (layer { name: “pool2” … }): 这是一个池化层,用于降低特征图的分辨率,通常用于减少计算复杂度。
- Eltwise 层 (layer { name: “res3_2” … }): 这是一个元素级操作层,通常用于残差网络(ResNet)中,用于连接不同层的输出。
- 全连接层 (layer { name: “fc12” … }): 这是一个全连接层,用于将卷积层的输出映射到最终的分类标签或预测。
- SoftmaxWithLoss 层 (layer { name: “loss” … }): 这是损失层,通常与Softmax函数一起使用,用于计算损失函数,用于模型训练。
数据层配置
数据层在深度学习模型中是一个关键组成部分,用于加载和处理输入数据。在你提供的代码中,数据层的定义如下:
layer {
name: "data"
type: "SuncgData"
top: "data"
top: "seg_label"
top: "seg_weight"
suncg_data_param {
file_data: "../../../../data/depthbin/SUNCGtrain_1_500"
file_data: "../../../../data/depthbin/SUNCGtrain_501_1000"
file_data: "../../../../data/depthbin/SUNCGtrain_1001_2000"
file_data: "../../../../data/depthbin/SUNCGtrain_1001_3000"
file_data: "../../../../data/depthbin/SUNCGtrain_3001_5000"
file_data: "../../../../data/depthbin/SUNCGtrain_5001_7000"
file_list: ""
vox_unit: 0.02
vox_margin: 0.24
vox_size: 240
vox_size: 144
vox_size: 240
crop_size: 240
crop_size: 144
crop_size: 240
label_size: 60
label_size: 36
label_size: 60
seg_classes: 11
shuffle: true
occ_empty_only: true
neg_obj_sample_ratio: 2
seg_class_map: ...
seg_class_weight: ...
occ_class_weight: ...
with_projection_tsdf: false
batch_size: 1
tsdf_type: 1
data_type: TSDF
surf_only: false
}
}
主要参数如下
name: “data”: 数据层的名称,用于在模型中引用该层。
type: “SuncgData”: 数据层的类型,指定了如何处理数据。
top: “data”, top: “seg_label”, top: “seg_weight”: 数据层的输出,模型中其他层可以引用这些输出。
suncg_data_param: 数据层的参数配置块。
file_data: 数据文件的路径,用于加载数据。这里看起来是从SUNCG数据集中加载深度信息。
vox_unit, vox_margin, vox_size: 与体素(Voxel)的设置相关。
vox_unit是体素的大小,vox_margin是体素的边缘大小,vox_size是体素在每个维度的数量。这些参数定义了体素网格的离散化空间。crop_size 和 label_size: 数据的裁剪大小和标签大小。
crop_size表示输入数据的裁剪尺寸,label_size表示标签的大小。seg_classes: 指定了分类任务中的类别数量。
shuffle: 一个布尔值,表示是否在加载数据时进行洗牌(打乱数据顺序)。
occ_empty_only: 一个布尔值,可能表示只关注占用(occupied)和空闲(empty)之间的区别。
neg_obj_sample_ratio: 负对象采样比例。
seg_class_map, seg_class_weight, occ_class_weight: 用于定义不同类别的映射和权重。
seg_class_map用于将一些类别映射到其他类别,seg_class_weight和occ_class_weight用于类别的权重设置。with_projection_tsdf 和 surf_only: 控制是否使用投影TSDF和是否仅考虑表面信息。投影TSDF通常用于三维重建,而
surf_only可能用于指示仅关注表面的信息。batch_size: 训练时的批处理大小,影响每次模型权重更新时使用的样本数量。
tsdf_type 和 data_type: 与数据类型相关的参数,例如TSDF数据类型。
surf_only: 一个布尔值,可能表示是否仅考虑表面数据。
这些参数共同定义了数据层的行为,确保数据被正确加载和预处理,以供深度学习模型使用。
LMSCNet
代码链接: LMSCNet: Lightweight Multiscale 3D Semantic Completion, 3DV 2020
一种从体素化稀疏三维激光雷达扫描中完成多尺度三维语义场景的新方法,使用具有全面多尺度跳跃连接的2D UNet主干来增强特征流,以及3D分割头
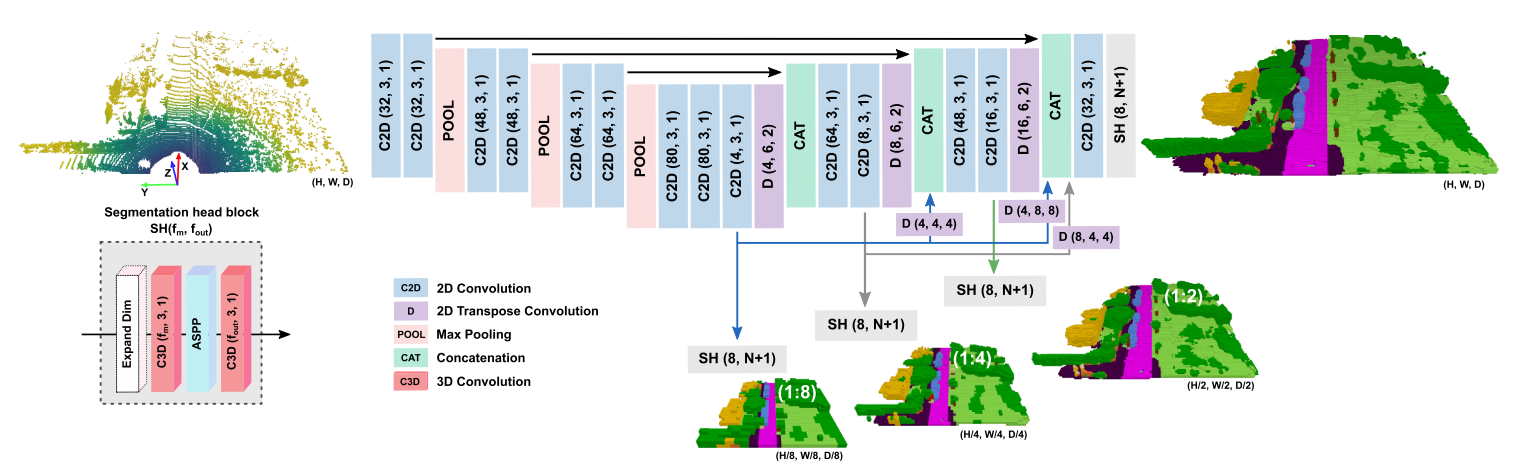
首先看配置文件LMSCNet.yaml这段代码是一个用于训练深度学习模型的Python脚本,基于LMSCNet网络。以下是关于训练设置以及代码的关键部分的解释:
训练设置
数据加载器设置:
NUM_WORKERS: 4:用于数据加载的工作线程数。
数据集设置:
- 数据增强:
FLIPS: true:表示是否进行数据增强,包括翻转等。
- 模态设置:
3D_LABEL: true:表示是否使用3D标签数据。3D_OCCLUDED: true:表示是否使用3D遮挡数据。3D_OCCUPANCY: true:表示是否使用3D占用数据。
ROOT_DIR: /datasets_local/datasets_lroldaoj/semantic_kitti_v1.0/:数据集的根目录。TYPE: SemanticKITTI:数据集的类型,这里是SemanticKITTI。
- 数据增强:
模型设置:
TYPE: LMSCNet:使用的模型类型为LMSCNet。
优化器设置:
BASE_LR: 0.001:学习率的初始值。BETA1: 0.9:Adam优化器的beta1参数。BETA2: 0.999:Adam优化器的beta2参数。MOMENTUM: NA:动量参数(未设置)。TYPE: Adam:优化器的类型。WEIGHT_DECAY: NA:权重衰减参数(未设置)。
输出设置:
OUT_ROOT: ../SSC_out/:输出结果的根目录。
调度器设置:
FREQUENCY: epoch:学习率调度的频率为每个epoch。LR_POWER: 0.98:学习率调度的幂次方。TYPE: power_iteration:学习率调度类型。
状态设置:
RESUME: false:是否从之前的检查点中恢复训练(未设置为恢复)。
训练设置:
BATCH_SIZE: 4:每个批次的样本数量。CHECKPOINT_PERIOD: 15:保存检查点的周期。EPOCHS: 80:总共训练的轮数。SUMMARY_PERIOD: 50:汇总损失的周期。
验证设置:
BATCH_SIZE: 8:验证时的批次大小。SUMMARY_PERIOD: 20:验证损失的周期。
LMSCNet网络代码解释
当分析这个神经网络模型时,我们可以将其分解为以下几个关键组件和部分。以下是对这些组件和部分的更详细解释:
SegmentationHead(分割头部)
SegmentationHead 类用于处理单一尺度的语义分割任务。它包括以下组件:
First Convolution (第一个卷积层):
conv0定义了一个3D卷积层,用于将输入的特征从一个尺度(inplanes)转换到planes。这是模型的初始特征处理步骤。ASPP Block (空间金字塔池化块):
ASPP是”空间金字塔池化块”的缩写,它由多个卷积层和扩张卷积层(dilated convolution)组成。这些层用于捕捉不同感受野(receptive field)下的特征。这有助于模型更好地理解图像中的上下文信息。conv1包括多个扩张卷积层,bn1是相应的批归一化层,然后再通过conv2进行进一步处理。这些层通过 ReLU 激活函数进行激活。Convolution for Output (用于输出的卷积):
conv_classes是用于生成最终语义分割预测的卷积层,其输出通道数等于目标类别数nbr_classes。
LMSCNet(语义分割网络)
LMSCNet 类定义了整个语义分割网络,它的结构包括:
Encoder Blocks (编码块): 这些块包括卷积层和激活函数,它们用于从输入数据提取特征。编码块分层堆叠,逐渐降低分辨率。其中
Encoder_block1处理输入数据,然后Encoder_block2、Encoder_block3和Encoder_block4分别进行更多的特征提取。Output Scales (输出尺度): 模型产生多个尺度的语义分割输出,包括1:8、1:4、1:2和1:1。每个输出尺度都有相应的卷积层和
SegmentationHead。这些层用于生成不同分辨率下的语义分割预测。反卷积层 (Deconvolution Layers): 这些层包括
deconv_1_8__1_2、deconv_1_8__1_1、deconv1_4、deconv1_2和deconv1_1,用于上采样,将较低分辨率的输出转换为高分辨率。这些层用于与高分辨率的编码块特征进行连接。权重初始化和损失计算: 类中还包括了初始化权重的函数
weights_initializer,以及用于计算损失的函数compute_loss。损失计算使用交叉熵损失,针对每个尺度的输出都会计算相应的损失。类别权重 (Class Weights): 模型使用
get_class_weights函数计算类别权重,以便处理不平衡的类别分布。其他辅助函数: 类还包括其他用于获取目标数据、设置训练尺度等的辅助函数。
这个模型的核心思想是从低分辨率到高分辨率逐步提取特征,并生成多尺度的语义分割预测。模型的损失函数考虑了所有尺度的预测,以便综合多尺度信息来进行训练。这有助于提高语义分割任务的性能,特别是在处理不同尺度的对象时。模型的训练和验证过程通常需要提供训练数据、优化器和学习率调度器等组件。
JS3CNet
一种增强的联合单扫LiDAR点云语义分割方法,该方法利用学习的形状先验形式场景完成网络,即JS3C-Net
代码链接: JS3CNet: Sparse Single Sweep LiDAR Point Cloud Segmentation via Learning Contextual Shape Priors from Scene Completion, AAAI 2021
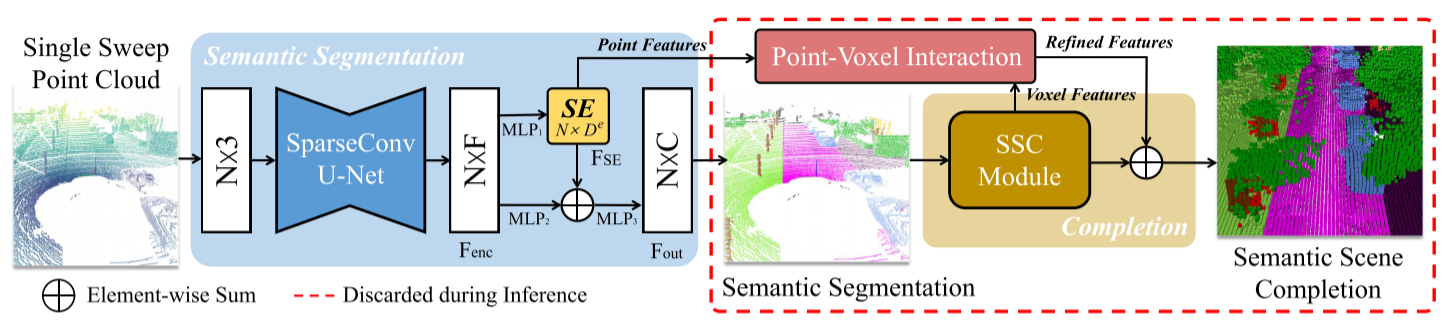
代码分析
JS3C_default_kitti.yaml这是一个JS3CNet网络的配置文件。配置文件用于定义训练和测试JS3CNet网络时的各种参数和设置。以下是关于配置文件的详细解释:
GENERAL:
task: train
manual_seed: 123
dataset_dir: /home/yxu/data/semantic_kitti/dataset/
debug: Falsetask: 定义任务类型,这里设置为”train”表示进行训练。manual_seed: 随机数种子,用于确保实验的可复现性。dataset_dir: 数据集的目录路径。debug: 是否启用调试模式,设置为”False”表示不启用。
DATA:
dataset: SemanticKITTI
classes_seg: 19
classes_completion: 20dataset: 数据集的名称,这里使用SemanticKITTI数据集。classes_seg: 语义分割任务的类别数,这里设置为19。classes_completion: 完备性任务的类别数,这里设置为20。
Segmentation:
model_name: SubSparseConv
m: 16
block_residual: False
block_reps: 1
seg_groups: 1
use_coords: False
feature_dims: [16,32,48,64,80,96,112]
input_channel: 3
scale: 10
full_scale: [0, 2048]
max_npoint: 250000
mode: 4Segmentation部分包含了与语义分割任务相关的参数设置。model_name: 语义分割模型的名称,这里使用SubSparseConv。m: SubSparseConv模型的参数,这里设置为16。block_residual: 是否使用块残差,设置为”False”表示不使用。block_reps: 块的重复次数,这里设置为1。seg_groups: 分割组的数量,这里设置为1。use_coords: 是否使用坐标信息,设置为”False”表示不使用。feature_dims: 特征维度的设置。input_channel: 输入通道的数量,这里设置为3。scale: 数据集的尺度。full_scale: 数据集的完全尺度范围。max_npoint: 最大点数,这里设置为250,000。mode: 模式设置,这里设置为4。
Completion:
model_name: SSCNet
m: 32
feeding: both
no_fuse_feat: False
block_residual: True
block_reps: 2
use_coords: False
mode: 0
full_scale: [256, 256, 32]
interaction: True
pooling_type: mean
fuse_k: 5
point_cloud_range: [0, -25.6, -2, 51.2, 25.6, 4.4]
voxel_size: 0.2
search_k: 8
feat_relation: FalseCompletion部分包含了与完备性任务相关的参数设置。model_name: 完备性模型的名称,这里使用SSCNet。m: SSCNet模型的参数,这里设置为32。feeding: 输入数据的类型,这里设置为”both”,表示同时输入特征和概率。no_fuse_feat: 是否不融合特征,设置为”False”表示融合特征。block_residual: 是否使用块残差,设置为”True”表示使用。block_reps: 块的重复次数,这里设置为2。use_coords: 是否使用坐标信息,设置为”False”表示不使用。mode: 模式设置,这里设置为0。full_scale: 完全尺度范围的设置。interaction: 是否启用交互,设置为”True”表示启用。pooling_type: 池化类型,这里设置为”mean”。fuse_k: 融合参数k的设置。point_cloud_range: 点云范围的设置。voxel_size: 体素大小的设置。search_k: 搜索参数k的设置。feat_relation: 特征关系的设置,这里设置为”False”。
TRAIN:
epochs: 100
train_workers: 10
optim: Adam
batch_size: 2
learning_rate: 0.001
lr_decay: 0.7
decay_step: 10
momentum: 0.9
weight_decay: 0.0001
save_freq: 16
uncertainty_loss: True
loss_weight: [1.0, 0.8]
pretrain_path:
train_from: 0
seg_num_per_class: [55437630, 320797, 541736, 2578735, 3274484, 552662, 184064, 78858, 240942562, 17294618, 170599734, 6369672, 230413074, 101130274, 476491114, 9833174, 129609852, 4506626, 1168181]
complt_num_per_class: [7632350044, 15783539, 125136, 118809, 646799, 821951, 262978, 283696, 204750, 61688703, 4502961, 44883650, 2269923, 56840218, 15719652, 158442623, 2061623, 36970522, 1151988, 334146]TRAIN部分包含了训练相关的参数设置。epochs: 训练的轮数,这里设置为100。train_workers: 数据加载器的工作进程数,这里设置为10。optim: 优化器的选择,这里使用Adam。batch_size: 批量大小,这里设置为2。learning_rate: 学习率,这里设置为0.001。lr_decay: 学习率的衰减率,这里设置为0.7。decay_step: 学习率衰减的步数,这里设置为10。momentum: 优化器的动量,这里设置为0.9。weight_decay: 权重衰减,这里设置为0.0001。save_freq: 模型保存的频率,这里设置为16。uncertainty_loss: 是否启用不确定性损失,设置为”True”表示启用。loss_weight: 损失的权重,这里是一个列表,包括语义损失和完备性损失的权重。pretrain_path: 预训练模型的路径。train_from: 从哪一轮训练开始,这里设置为0。seg_num_per_class: 每个类别的语义分割样本数量。complt_num_per_class: 每个类别的完备性样本数量。
这个配置文件包含了JS3CNet网络的各种参数和设置,用于训练和测试语义分割和完备性任务。
J3SC_Net 是 JS3CNet 网络的核心部分,主要用于同时处理语义分割和点云完备性分割任务。它是一个继承自 PyTorch 的 nn.Module 的模型,下面将对其进行详细介绍:
class J3SC_Net(nn.Module):
def __init__(self, args):
super().__init__()
self.args = args
self.seg_head = seg_model(args)
self.complet_head = complet_model(args)
self.voxelpool = model_utils.VoxelPooling(args)
self.seg_sigma = nn.Parameter(torch.Tensor(1).uniform_(0.2, 1), requires_grad=True)
self.complet_sigma = nn.Parameter(torch.Tensor(1).uniform_(0.2, 1), requires_grad=True)
def forward(self, x):
seg_inputs, complet_inputs, _ = x
# 分割头部分
seg_output, feat = self.seg_head(seg_inputs)
# 完备性头部分
coords = complet_inputs['complet_coords']
coords = coords[:, [0, 3, 2, 1]]
if args['DATA']['dataset'] == 'SemanticKITTI':
coords[:, 3] += 1
elif args['DATA']['dataset'] == 'SemanticPOSS':
coords[:, 3][coords[:, 3] > 31] = 31
if args['Completion']['feeding'] == 'both':
feeding = torch.cat([seg_output, feat], 1)
elif args['Completion']['feeding'] == 'feat':
feeding = feat
else:
feeding = seg_output
# 使用Voxelpool模块进行特征池化操作
features = self.voxelpool(
invoxel_xyz=complet_inputs['complet_invoxel_features'][:, :, :-1],
invoxel_map=complet_inputs['complet_invoxel_features'][:, :, -1].long(),
src_feat=feeding,
voxel_center=complet_inputs['voxel_centers']
)
if self.args['Completion']['no_fuse_feat']:
features[...] = 1
features = features.detach()
# 创建SparseConvTensor,用于点云完备性分割
batch_complet = spconv.SparseConvTensor(
features.float(), coords.int(), args['Completion']['full_scale'], args['TRAIN']['batch_size']
)
batch_complet = dataset.sparse_tensor_augmentation(batch_complet, complet_inputs['state'])
# 使用完备性头部分进行点云完备性分割
complet_output = self.complet_head(batch_complet)
return seg_output, complet_output, [self.seg_sigma, self.complet_sigma]主要组成部分:
seg_head和complet_head:这是分割头和完备性头的模型,它们通过args参数配置,用于执行分割任务和完备性任务。这些模型的初始化在__init__方法中进行。voxelpool模块:用于对特征进行池化操作。根据输入参数,它将输入特征和相关的信息池化成新的特征。seg_sigma和complet_sigma:这是可学习的参数,分别表示语义分割和完备性分割任务的不确定性。模型在训练过程中会学习这些参数。
前向传播(forward 方法):
在前向传播中,J3SC_Net 接受一个输入 x,其中 x 包含了分割和完备性任务的输入。首先,模型通过语义分割头 (seg_head) 处理分割任务的输入数据 seg_inputs,生成 seg_output 和 feat。
然后,对完备性任务的输入数据进行处理。首先调整坐标 coords,然后根据 args 的配置选择适当的输入数据 feeding。接下来,使用 voxelpool 模块对特征进行池化操作,生成 features。
最后,将生成的 features 传递给完备性头部分 (complet_head) 进行点云完备性分割。模型的输出包括语义分割结果 seg_output 和点云完备性分割结果 complet_output,以及模型学习的不确定性参数 seg_sigma 和 complet_sigma。
J3SC_Net 模型将同时执行语义分割和点云完备性分割任务,使其成为 JS3CNet 网络的核心组件。这种多任务学习可以在处理点云数据时提高效率和性能。
SSCNet 是一个用于点云完备性分割的神经网络模型,它是 JS3CNet 中完备性分割部分的模型。下面将详细介绍 SSCNet 模型的主要组成部分。
SSCNet_Decoder
SSCNet_Decoder 是 SSCNet 的解码器部分。它主要负责将输入特征映射到点云的完备性分割结果。该解码器采用了类似 U-Net 架构的设计,分为不同的块(Block),其中包括卷积、批归一化和 ReLU 激活函数层。以下是 SSCNet_Decoder 中各个块的主要部分:
Block 1:包括两个卷积层,每个卷积层后接批归一化和 ReLU 激活函数。该块的输出与一个残差块相加,并经过最大池化。
Block 2:与 Block 1 类似,包括两个卷积层,批归一化和 ReLU 激活函数。输出与残差块相加。
Block 3:包括两个卷积层,批归一化和 ReLU 激活函数。没有残差连接。
Block 4:包括两个卷积层,批归一化和 ReLU 激活函数。没有残差连接。
Block 5:包括两个卷积层,批归一化和 ReLU 激活函数。没有残差连接。
Prediction:该块用于生成最终的点云完备性分割结果。它包括两个卷积层,最终输出预测结果。
SSCNet_Decoder 的各个块逐渐提取并综合特征,最终生成点云完备性分割的预测结果。
SSCNet
SSCNet 是完备性分割网络的主要模型。它包含以下组件:
Decoder:前面介绍的SSCNet_Decoder,用于点云完备性分割任务。它将输入的点云特征进行解码操作,最终生成点云完备性分割的预测结果。upsample:这是上采样模块,用于上采样点云完备性分割的结果,以便与语义分割结果相融合。interaction_module(可选):如果配置中启用了交互模块(args['Completion']['interaction']为True),则此组件用于执行点云之间的交互操作。这可以有助于改进点云完备性分割性能。
SSCNet 的前向传播过程首先将输入特征通过 Decoder 进行解码,然后根据配置选择是否执行交互操作,最后经过上采样模块生成最终的点云完备性分割结果。
这些组件一起构成了 SSCNet 模型,用于处理点云数据的完备性分割任务。
complet_head 是用于点云语义完成任务的头部模块。它定义了一个 Unet 模型,用于处理 3D 点云数据。
类 Unet
这个类包含了 Unet 模型的构建和前向传播方法。以下是类 Unet 的详细分析:
构造方法
__init__:- 这个方法接受一个配置参数
config,用于指定模型的各种参数和配置信息。 m是配置中指定的通道数。input_dim是输入数据的维度,如果配置中指定了使用坐标信息 (use_coords为True),则为 4,否则为 1。sparseModel是一个 SparseConvNet 序列模型,它包含了 Unet 架构,包括编码器、解码器和跳跃连接部分。
- 这个方法接受一个配置参数
前向传播方法
forward:- 这个方法接受输入
x,其中x包含seg_coords和seg_features。 x被传递给sparseModel,这一步会进行 Unet 架构的前向传播。- 如果在配置中启用了
interaction,则模型还会执行特征嵌入过程,以处理点云的交互信息。 - 最后,模型执行线性变换,将特征映射到类别预测空间,并返回预测结果以及特征信息。
- 这个方法接受输入
函数 Merge(tbl)
这个函数是用于处理训练数据的工具函数,它接受一个包含多个样本数据的列表 tbl。
- 函数通过迭代遍历每个样本数据,并从每个样本中提取出所需的数据,分别处理分割和完成任务的部分。
- 分割部分的数据包括坐标信息、标签和特征。
- 完成部分的数据包括点云坐标、输入数据、体素中心坐标、有效性信息、标签、统计信息以及点云体素特征。
- 这些数据被整理成适合输入到模型的格式,并以字典形式返回,包括
seg_inputs和complet_inputs。 - 还返回了一个包含样本文件名的列表,用于后续的分析和处理。
总之,complet_head 中的代码定义了一个用于点云语义完成任务的 Unet 模型,同时提供了一个数据处理函数 Merge(tbl),用于将原始数据整理成适合输入模型的格式。
model_utils.py 包含了用于模型训练和实用工具的函数和类。下面是该文件中主要部分的详细分析:
checkpoint_restore(model, exp_name, use_cuda=True, train_from=0):- 此函数用于从检查点文件中恢复模型的参数。
model是模型对象,exp_name是实验名称,use_cuda是是否使用 CUDA 运行模型,train_from是指定的训练起始时期。- 函数会查找以 “.pth” 结尾的模型检查点文件,找到最新的模型检查点并加载到模型中。
- 如果指定了
train_from大于0,会从该时期开始训练。 - 函数返回模型训练的当前时期。
VoxelPooling:- 这是一个用于点云特征池化的自定义模块。
- 通过此模块,可以将点云体素汇聚为单一特征。
- 模块会对点云体素进行池化操作,并考虑了点云体素之间的关系。
Loss:- 这是一个自定义的损失函数模块,用于计算训练中的损失。
- 它计算分割损失和完成损失,支持带权重的损失计算。
- 如果
uncertainty_loss被启用,还会计算损失的不确定性。
interaction_module:- 这是一个模块,用于模型中的点云交互。
- 它允许点云之间的特征交互,可以选择使用特征关系或直接的插值方法。
- 此模块通过模型的前向传播执行点云特征的交互操作。
ResidualBlock,VGGBlock,UBlock:- 这些模块用于构建模型的特定类型的块,如残差块、VGG 块和 U 块。
- 这些块用于构建点云处理模型的不同组件。
其他工具函数:
- 文件中还包括了其他用于文件读写、坐标转换、特征提取和其他辅助功能的函数。
总之,model_utils.py 包含了模型训练中的损失函数、模型恢复函数、自定义模块和工具函数,这些组成部分用于构建和训练点云处理模型。
MonoScene
一种能在室内与室外场景均可使用的单目 SSC 方案:
- 提出一种将 2D 特征投影到 3D 的方法: FLoSP
- 提出一种 3D Context Relation Prior (3D CRP) 提升网络的上下文意识
- 新的SSC损失函数,用于优化场景类亲和力(affinity)和局部锥体(frustum)比例
代码链接: MonoScene: Monocular 3D Semantic Scene Completion, CVPR 2022

Monoscene 网络流程
- 输入 2d 图片,经过 2d unet 提取多层次的特征
- Features Line of Sight Projection module (FLoSP) 用于将 2d 特征提升到 3d 位置上,增强信息流并实现2D-3D分离
- 3D Context Relation Prior (3D CRP) 用于增强长距离的上下文信息提取
- loss 优化:Scene-Class Affinity Loss:提升类内和类间的场景方面度量;Frustum Proportion Loss:对齐局部截头体中的类分布,提供超越场景遮挡的监督信息
网络结构
- 2D unet:EfficientNetB7 用于提取图像特征
- 3D UNets:2层 encoder-decoder 结构,用于提取 3d 特征
- completion head:3D ASPP 结构和 softmax 层,用于处理 3D UNet 输出得到3d场景 completion 结果
代码介绍
monoscene.py使用PyTorch Lightning构建的一个名为MonoScene的模型类,用于单目深度估计和场景分割的任务。以下是该类的主要组件和功能的详细解释:
初始化方法 (
__init__):这是类的构造方法,在创建MonoScene对象时被调用。它接受多个参数,包括类别数 (n_classes)、类别名称 (class_names)、特征数量 (feature)、类别权重 (class_weights) 等,用于初始化模型的各种参数和组件。其中的许多参数用于配置损失函数和训练过程中的各种选项。这里还创建了一个UNet 2D模型和多个FLoSP (Feature Learning from Single Point) 模型,用于3D场景估计。前向传播方法 (
forward):forward方法定义了如何计算模型的前向传播。它接受一个输入批次 (batch),包括图像 (img),并根据输入数据的尺寸进行前向传播计算。首先,通过UNet 2D模型 (net_rgb) 处理输入图像,然后根据尺度变化对图像进行3D投影,最终由UNet 3D模型 (net_3d_decoder) 进行3D场景估计。前向传播的结果保存在out变量中。step方法:step方法执行了训练、验证和测试过程中的通用逻辑。它接受一个数据批次 (batch)、一个步骤类型 (step_type) 和一个度量指标 (metric)。在该方法中,对输入数据进行前向传播,计算并更新损失,同时也更新度量指标。这部分逻辑用于在训练、验证和测试时共享相同的操作。训练步骤 (
training_step):training_step方法是PyTorch Lightning中定义训练步骤的函数。它调用了step方法,以及指定了步骤类型 (“train”) 和训练度量指标 (self.train_metrics)。验证步骤 (
validation_step) 和 验证结束方法 (validation_epoch_end):这两个方法用于在验证集上进行评估。validation_step方法执行一个验证步骤,计算损失和更新验证度量指标 (self.val_metrics)。validation_epoch_end方法在每个验证周期结束后,从度量指标中获取评估结果并进行记录。测试步骤 (
test_step) 和 测试结束方法 (test_epoch_end):这两个方法用于在测试集上进行评估,与验证过程类似。配置优化器 (
configure_optimizers):在此方法中配置了模型的优化器和学习率调度器。根据数据集的不同(NYU或KITTI),选择了不同的优化器和学习率调度策略。指标记录和日志输出:在不同的步骤中,通过
self.log方法记录和输出训练、验证和测试的损失、IoU、精确度等度量指标。这些度量指标在每个epoch结束时会被重置,以便记录下一个epoch的结果。
这段代码使用了PyTorch Lightning来规范化训练和评估流程,提供了清晰的组织结构,以及易于扩展和修改的接口,使其更容易适应不同的任务和数据集。根据您的需求,可以调整和扩展这个类来满足您的具体任务。
让我们逐行解释MonoScene类中的代码:
import pytorch_lightning as pl
import torch
import torch.nn as nn
from monoscene.models.unet3d_nyu import UNet3D as UNet3DNYU
from monoscene.models.unet3d_kitti import UNet3D as UNet3DKitti
from monoscene.loss.sscMetrics import SSCMetrics
from monoscene.loss.ssc_loss import sem_scal_loss, CE_ssc_loss, KL_sep, geo_scal_loss
from monoscene.models.flosp import FLoSP
from monoscene.loss.CRP_loss import compute_super_CP_multilabel_loss
import numpy as np
import torch.nn.functional as F
from monoscene.models.unet2d import UNet2D
from torch.optim.lr_scheduler import MultiStepLR这些行导入所需的Python库和模块,包括PyTorch、PyTorch Lightning、模型类、损失函数和其他依赖项。
class MonoScene(pl.LightningModule):这一行定义了一个名为MonoScene的PyTorch Lightning模型类,它继承自pl.LightningModule,这是PyTorch Lightning中定义自定义模型的基类。
def __init__(
self,
n_classes,
class_names,
feature,
class_weights,
project_scale,
full_scene_size,
dataset,
n_relations=4,
context_prior=True,
fp_loss=True,
project_res=[],
frustum_size=4,
relation_loss=False,
CE_ssc_loss=True,
geo_scal_loss=True,
sem_scal_loss=True,
lr=1e-4,
weight_decay=1e-4,
):这是MonoScene类的构造方法 (__init__)。它接受许多参数,这些参数用于配置模型的不同方面,如类别数、类别名称、特征数量、损失权重、训练选项等。这些参数被用于初始化模型的各个组件和超参数。
super().__init()这一行调用了基类的构造方法,即pl.LightningModule的构造方法。
self.project_res = project_res
self.fp_loss = fp_loss
self.dataset = dataset
self.context_prior = context_prior
self.frustum_size = frustum_size
self.class_names = class_names
self.relation_loss = relation_loss
self.CE_ssc_loss = CE_ssc_loss
self.sem_scal_loss = sem_scal_loss
self.geo_scal_loss = geo_scal_loss
self.project_scale = project_scale
self.class_weights = class_weights
self.lr = lr
self.weight_decay = weight_decay这些行将构造方法中传入的参数赋值给对象的属性,以便它们可以在整个类中使用。
self.projects = {}
self.scale_2ds = [1, 2, 4, 8] # 2D scales
for scale_2d in self.scale_2ds:
self.projects[str(scale_2d)] = FLoSP(
full_scene_size, project_scale=self.project_scale, dataset=self.dataset
)
self.projects = nn.ModuleDict(self.projects)这一部分初始化了模型的projects属性,其中包含多个FLoSP模型,用于将2D特征投影到3D场景。不同的投影比例 (scale_2d) 在这里被迭代,为每个比例创建一个FLoSP模型,并将它们存储在projects字典中。
self.n_classes = n_classes
if self.dataset == "NYU":
self.net_3d_decoder = UNet3DNYU(
self.n_classes,
nn.BatchNorm3d,
n_relations=n_relations,
feature=feature,
full_scene_size=full_scene_size,
context_prior=context_prior,
)
elif self.dataset == "kitti":
self.net_3d_decoder = UNet3DKitti(
self.n_classes,
nn.BatchNorm3d,
project_scale=project_scale,
feature=feature,
full_scene_size=full_scene_size,
context_prior=context_prior,
)这一部分初始化了模型的3D解码器 (net_3d_decoder),根据数据集的类型 (“NYU” 或 “kitti”) 选择不同的UNet 3D模型。该解码器将用于对3D场景进行估计。
self.net_rgb = UNet2D.build(out_feature=feature, use_decoder=True)这一行创建了模型的2D UNet模型 (net_rgb),该模型用于处理输入图像,其中的feature参数指定了模型的特征数量。
# log hyperparameters
self.save_hyperparameters()这一行记录了模型的超参数,以便后续可以查看它们。
self.train_metrics = SSCMetrics(self.n_classes)
self.val_metrics = SSCMetrics(self.n_classes)
self.test_metrics = SSCMetrics(self.n_classes)这些行初始化了训练、验证和测试度量指标 (train_metrics, val_metrics, test_metrics),用于跟踪模型性能。
这只是构造方法的设置部分。整个MonoScene类的构造方法用于初始化模型的各个组件和超参数。在下面的部分中,将解释类中的其他方法。
def forward(self, batch):
img = batch["img"]
bs = len(img)
out = {}
x_rgb = self.net_rgb(img)
x3ds = []
for i in range(bs):
x3d = None
for scale_2d in self.project_res:
# project features at each 2D scale to target 3D scale
scale_2d = int(scale_2d)
projected_pix = batch["projected_pix_{}".format(self.project_scale)][i].cuda()
fov_mask = batch["fov_mask_{}".format(self.project_scale)][i].cuda()
if x3d is None:
x3d = self.projects[str(scale_2d)](
x_rgb["1_" + str(scale_2d)][i],
projected_pix // scale_2d,
fov_mask,
)
else:
x3d += self.projects[str(scale_2d)](
x_rgb["1_" + str(scale_2d)][i],
projected_pix // scale_2d,
fov_mask,
)
x3ds.append(x3d)
input_dict = {"x3d": torch.stack(x3ds)}
out = self.net_3d_decoder(input_dict)
return out这是模型的前向传播函数 forward。在这个函数中,输入图像 img 被传递给 2D UNet 模型 net_rgb 以提取特征。然后,特征将根据指定的投影比例 (self.project_res) 投影到3D场景中。对于每个输入样本,它会循环遍历不同的投影比例,并调用FLoSP模型 (self.projects) 来执行特征投影。最终,投影的特征将被传递给3D解码器 net_3d_decoder 进行3D场景估计。
def step(self, batch, step_type, metric):
bs = len(batch["img"])
loss = 0
out_dict = self(batch)
ssc_pred = out_dict["ssc_logit"]
target = batch["target"]
if self.context_prior:
P_logits = out_dict["P_logits"]
CP_mega_matrices = batch["CP_mega_matrices"]
if self.relation_loss:
loss_rel_ce = compute_super_CP_multilabel_loss(
P_logits, CP_mega_matrices
)
loss += loss_rel_ce
self.log(
step_type + "/loss_relation_ce_super",
loss_rel_ce.detach(),
on_epoch=True,
sync_dist=True,
)这个方法 step 用于执行训练、验证和测试步骤的公共逻辑。它接受批量数据 batch、步骤类型 step_type(如 “train”、”val”、”test”)和度量对象 metric 作为参数。在这个方法中,模型的前向传播被调用,并计算损失 loss。具体的损失计算依赖于模型的配置和目标。在这里,根据模型的配置,可以计算包括关系损失 (loss_rel_ce) 的不同损失项。如果启用了关系损失 (self.relation_loss),则将计算关系损失并将其添加到总损失中。
class_weight = self.class_weights.type_as(batch["img"])
if self.CE_ssc_loss:
loss_ssc = CE_ssc_loss(ssc_pred, target, class_weight)
loss += loss_ssc
self.log(
step_type + "/loss_ssc",
loss_ssc.detach(),
on_epoch=True,
sync_dist=True,
)
if self.sem_scal_loss:
loss_sem_scal = sem_scal_loss(ssc_pred, target)
loss += loss_sem_scal
self.log(
step_type + "/loss_sem_scal",
loss_sem_scal.detach(),
on_epoch=True,
sync_dist=True,
)
if self.geo_scal_loss:
loss_geo_scal = geo_scal_loss(ssc_pred, target)
loss += loss_geo_scal
self.log(
step_type + "/loss_geo_scal",
loss_geo_scal.detach(),
on_epoch=True,
sync_dist=True,
)在这一部分中,根据模型的配置,计算了交叉熵损失 (loss_ssc)、语义分割损失 (loss_sem_scal) 和几何尺度损失 (loss_geo_scal)。这些损失用于对模型进行监督训练,以便它能够学习适应输入数据并进行3D场景估计。
if self.fp_loss and step_type != "test":
frustums_masks = torch.stack(batch["frustums_masks"])
frustums_class_dists = torch.stack(
batch["frustums_class_dists"]
).float() # (bs, n_frustums, n_classes)
n_frustums = frustums_class_dists.shape[1]
pred_prob = F.softmax(ssc_pred, dim=1)
batch_cnt = frustums_class_dists.sum(0) # (n_frustums, n_classes)
frustum_loss = 0
frustum_nonempty = 0
for frus in range(n_frustums):
frustum_mask = frustums_masks[:, frus, :, :, :].unsqueeze(1).float()
prob = frustum_mask * pred_prob # bs, n_classes, H, W, D
prob = prob.reshape(bs, self.n_classes, -1).permute(1, 0, 2)
prob = prob.reshape(self.n_classes, -1)
cum_prob = prob.sum(dim=1) # n_classes
total_cnt = torch.sum(batch_cnt[frus])
total_prob = prob.sum()
if total_prob > 0 and total_cnt > 0:
frustum_target_proportion = batch_cnt[frus] / total_cnt
cum_prob = cum_prob / total_prob # n_classes
frustum_loss_i = KL_sep(cum_prob, frustum_target_proportion)
frustum_loss += frustum_loss_i
frustum_nonempty += 1
frustum_loss = frustum_loss / frustum_nonempty
loss += frustum_loss
self.log(
step_type + "/loss_frustums",
frustum_loss.detach(),
on_epoch=True,
sync_dist=True,
)在这部分代码中,计算
了与模型输出的SSC预测和输入数据中的frustum masks 相关的损失项。如果 self.fp_loss 被设置为 True 并且步骤类型不是 “test”,则将计算frustum损失。这个损失考虑了模型对视场的理解,以及模型的预测与输入数据的关系。
最后,损失项被添加到总损失 loss 中,并使用 self.log 方法记录损失,以便在训练期间进行监控。
y_true = target.cpu().numpy()
y_pred = ssc_pred.detach().cpu().numpy()
y_pred = np.argmax(y_pred, axis=1)
metric.add_batch(y_pred, y_true)
self.log(step_type + "/loss", loss.detach(), on_epoch=True, sync_dist=True)在这里,真实标签和模型预测的标签用于计算模型性能指标,并将它们传递给 metric 对象。度量对象用于跟踪模型性能,并使用 self.log 方法记录损失。
这部分代码覆盖了step 方法中的主要逻辑,它是用于训练、验证和测试的公共代码。
def training_step(self, batch, batch_idx):
return self.step(batch, "train", self.train_metrics)这个方法是用于训练的步骤。它调用了 step 方法,并传递了相应的参数。在训练期间,它还返回损失以供 PyTorch Lightning 进行后续的处理。
def validation_step(self, batch, batch_idx):
self.step(batch, "val", self.val_metrics)这个方法是验证步骤。它也调用了 step 方法,但不返回损失,而是将性能指标记录到验证度量对象 val_metrics 中。
def validation_epoch_end(self, outputs):
metric_list = [("train", self.train_metrics), ("val", self.val_metrics)]
for prefix, metric in metric_list:
stats = metric.get_stats()
for i, class_name in enumerate(self.class_names):
self.log(
"{}_SemIoU/{}".format(prefix, class_name),
stats["iou_ssc"][i],
sync_dist=True,
)
self.log("{}/mIoU".format(prefix), stats["iou_ssc_mean"], sync_dist=True)
self.log("{}/IoU".format(prefix), stats["iou"], sync_dist=True)
self.log("{}/Precision".format(prefix), stats["recall"], sync_dist=True)
self.log("{}/Recall".format(prefix), stats["recall"], sync_dist=True)
metric.reset()这个方法在验证周期结束时被调用,用于总结验证阶段的性能。它计算各个类别的语义分割IoU、平均IoU、IoU和精确度,并使用 self.log 方法记录这些度量值。
def test_step(self, batch, batch_idx):
self.step(batch, "test", self.test_metrics)这个方法是测试步骤,类似于验证步骤,它调用 step 方法并将性能指标记录到测试度量对象 test_metrics 中。
def test_epoch_end(self, outputs):
classes = self.class_names
metric_list = [("test", self.test_metrics)]
for prefix, metric in metric_list:
print("{}======".format(prefix))
stats = metric.get_stats()
print(
"Precision={:.4f}, Recall={:.4f}, IoU={:.4f}".format(
stats["precision"] * 100, stats["recall"] * 100, stats["iou"] * 100
)
)
print("class IoU: {}, ".format(classes))
print(
" ".join(["{:.4f}, "] * len(classes)).format(
*(stats["iou_ssc"] * 100).tolist()
)
)
print("mIoU={:.4f}".format(stats["iou_ssc_mean"] * 100))
metric.reset()这个方法在测试周期结束时被调用,用于总结测试阶段的性能。它打印了精确度、召回率、IoU 和类别IoU的信息,并将这些信息显示在控制台上。
def configure_optimizers(self):
if self.dataset == "NYU":
optimizer = torch.optim.AdamW(
self.parameters(), lr=self.lr, weight_decay=self.weight_decay
)
scheduler = MultiStepLR(optimizer, milestones=[20], gamma=0.1)
return [optimizer], [scheduler]
elif self.dataset == "kitti":
optimizer = torch.optim.AdamW(
self.parameters(), lr=self.lr, weight_decay=self.weight_decay
)
scheduler = MultiStepLR(optimizer, milestones=[20], gamma=0.1)
return [optimizer], [scheduler]这个方法用于配置优化器和学习率调度器。根据数据集类型 (self.dataset),它初始化一个AdamW优化器并将其与一个学习率调度器一起返回。调度器将在训练期间按照指定的里程碑来调整学习率。
这就是MonoScene类中的所有方法和逻辑的解释。该类代表了一个用于场景语义分割的PyTorch Lightning模型,它包括了许多用于定义前向传播、计算损失和跟踪性能的方法。
import torch
import torch.nn as nn
class FLoSP(nn.Module):
def __init__(self, scene_size, dataset, project_scale):
super().__init__()
self.scene_size = scene_size
self.dataset = dataset
self.project_scale = project_scale
def forward(self, x2d, projected_pix, fov_mask):
c, h, w = x2d.shape
src = x2d.view(c, -1)
zeros_vec = torch.zeros(c, 1).type_as(src)
src = torch.cat([src, zeros_vec], 1)
pix_x, pix_y = projected_pix[:, 0], projected_pix[:, 1]
img_indices = pix_y * w + pix_x
img_indices[~fov_mask] = h * w
img_indices = img_indices.expand(c, -1).long() # c, HWD
src_feature = torch.gather(src, 1, img_indices)
if self.dataset == "NYU":
x3d = src_feature.reshape(
c,
self.scene_size[0] // self.project_scale,
self.scene_size[2] // self.project_scale,
self.scene_size[1] // self.project_scale,
)
x3d = x3d.permute(0, 1, 3, 2)
elif self.dataset == "kitti":
x3d = src_feature.reshape(
c,
self.scene_size[0] // self.project_scale,
self.scene_size[1] // self.project_scale,
self.scene_size[2] // self.project_scale,
)
return x3d
这段代码定义了一个名为 FLoSP 的 PyTorch 模块,它用于执行特征投影操作。FLoSP 的作用是将一个 2D 图像中的特征投影到 3D 空间中。让我们逐行解释这个模块的功能和实现:
class FLoSP(nn.Module)::定义了一个名为FLoSP的 PyTorch 模块,它继承自nn.Module。def __init__(self, scene_size, dataset, project_scale)::初始化方法,接受三个参数:scene_size:表示 3D 场景的大小(宽度、高度、深度)。dataset:表示数据集的名称,可以是 “NYU” 或 “kitti”。project_scale:表示投影的尺度,通常是 2 的幂次方,用于将 2D 特征图中的像素投影到 3D 空间。
self.scene_size = scene_size:将输入的scene_size存储为对象属性,以便在模块的其他方法中使用。self.dataset = dataset:将输入的dataset存储为对象属性,以便在模块的其他方法中使用。self.project_scale = project_scale:将输入的project_scale存储为对象属性,以便在模块的其他方法中使用。def forward(self, x2d, projected_pix, fov_mask)::前向传播方法,用于执行特征投影操作。接受三个输入参数:x2d:2D 特征图,是一个张量,其形状为(c, h, w),其中c表示通道数,h和w表示高度和宽度。projected_pix:包含 2D 像素坐标的张量,其形状为(bs, 2),其中bs表示批处理大小。fov_mask:表示感兴趣区域的遮罩,是一个布尔值张量,形状与projected_pix相同。
c, h, w = x2d.shape:获取输入 2D 特征图x2d的通道数、高度和宽度。src = x2d.view(c, -1):将 2D 特征图x2d重新形状为(c, h * w),即将每个像素的特征连接到一个向量中。zeros_vec = torch.zeros(c, 1).type_as(src):创建一个与src相同数据类型的零向量,用于在特征向量后添加一个零值,以匹配 3D 坐标。src = torch.cat([src, zeros_vec], 1):将零向量添加到特征向量的末尾,以将特征向量的维度从(c, h * w)扩展到(c, h * w + 1)。pix_x, pix_y = projected_pix[:, 0], projected_pix[:, 1]:从projected_pix中提取 2D 像素坐标的 x 和 y 值。img_indices = pix_y * w + pix_x:计算像素坐标对应的在扁平化 2D 特征图中的索引。img_indices[~fov_mask] = h * w:将不在感兴趣区域内的像素坐标对应的索引设置为 2D 特征图的最大索引值(类似于超出图像范围的像素索引)。img_indices = img_indices.expand(c, -1).long():将计算得到的索引扩展为(c, h * w)的长整型张量。src_feature = torch.gather(src, 1, img_indices):使用计算得到的索引从src中聚合出感兴趣的像素特征。if self.dataset == "NYU"::如果数据集是 “NYU”,则执行以下操作。否则,执行 “kitti” 分支。a.
x3d = src_feature.reshape(c, self.scene_size[0] // self.project_scale, self.scene_size[2] // self.project_scale, self.scene_size[1] // self.project_scale):将特征投影到 3D 空间,根据输入的scene_size和project_scale进行重新形状。这一步是根据 NYU 数据集的特定情况进行的形状转换。b.
x3d = x3d.permute(0, 1, 3, 2):对投影得到的 3D 特征进行维度的置换。elif self.dataset == "kitti"::如果数据集是 “kitti”,则执行以下操作。a.
x3d = src_feature.reshape(c, self.scene_size[0] // self.project_scale, self.scene_size[1] // self.project_scale, self.scene_size[2] // self.project_scale):将特征投影到 3D 空间,根据输入的scene_size和project_scale进行重新形状。这一步是根据 kitti 数据集的特定情况进行的形状转换。return x3d:返回投影到 3D 空间的特征张量x3d。
这个模块的主要功能是将 2D 特征图中的像素特征投影到 3D 空间中,以便后续在 3D 空间中进行深度学习任务。具体的投影方法和维度变换取决于数据集的类型(”NYU” 或 “kitti”)和投影尺度(project_scale)。这个模块通常用于处理语义分割和深度估计等任务。
unet3d_kitti.py是一个3D U-Net模型的定义,用于语义分割任务。以下是代码的逐行解释:
UNet3D类继承自nn.Module,用于定义3D U-Net模型。__init__函数用于初始化模型,它接受一些参数,如类别数class_num、标准化层norm_layer、全尺寸full_scene_size、特征数feature、项目尺度project_scale、上下文先验context_prior和 Batch Normalization 层的动量bn_momentum。size_l1、size_l2和size_l3分别表示3D U-Net的3个不同尺寸层。dilations是用于处理图像的卷积核的膨胀率。self.process_l1和self.process_l2定义了两个处理层,用于处理输入3D数据,包括一系列的卷积、标准化和下采样操作。self.up_13_l2、self.up_12_l1和self.up_l1_lfull定义了上采样层,将3D数据上采样到不同尺寸的层。self.ssc_head定义了用于预测语义分割的头部,包括一系列卷积和输出层。self.context_prior用于确定是否使用上下文先验。如果context_prior为真,将定义self.CP_mega_voxels,它是上下文先验处理的一部分。forward函数接受输入数据的字典input_dict,包括x3d,表示3D数据。通过一系列处理步骤,如
self.process_l1和self.process_l2,输入数据被处理和下采样到不同尺寸层。如果存在上下文先验,将使用
self.CP_mega_voxels处理数据。使用上采样层
self.up_13_l2和self.up_12_l1将数据上采样到不同尺寸的层。最终,通过
self.ssc_head进行语义分割预测,并将结果存储在res字典中。
这个模型的核心部分是3D U-Net结构,它包含编码器和解码器部分,用于从3D输入数据中提取特征并生成语义分割结果。根据输入数据的尺寸和具体任务,该模型可以适应不同的上下文先验处理。
StereoScene
StereoScene用于3D语义场景补全(SSC),它充分利用了轻量级相机输入而无需使用任何外部3D传感器。研究者的关键想法是利用立体匹配来解决几何模糊性问题。为了提高其在不匹配区域的鲁棒性,论文引入了鸟瞰图(BEV)表示法,以激发具有丰富上下文信息的未知区域预测能力。在立体匹配和BEV表示法的基础上,论文精心设计了一个相互交互聚合(MIA)模块,以充分发挥两者的作用,促进它们互补聚合
代码链接:StereoScene: BEV-Assisted Stereo Matching Empowers 3D Semantic Scene Completion, arXiv 2023.
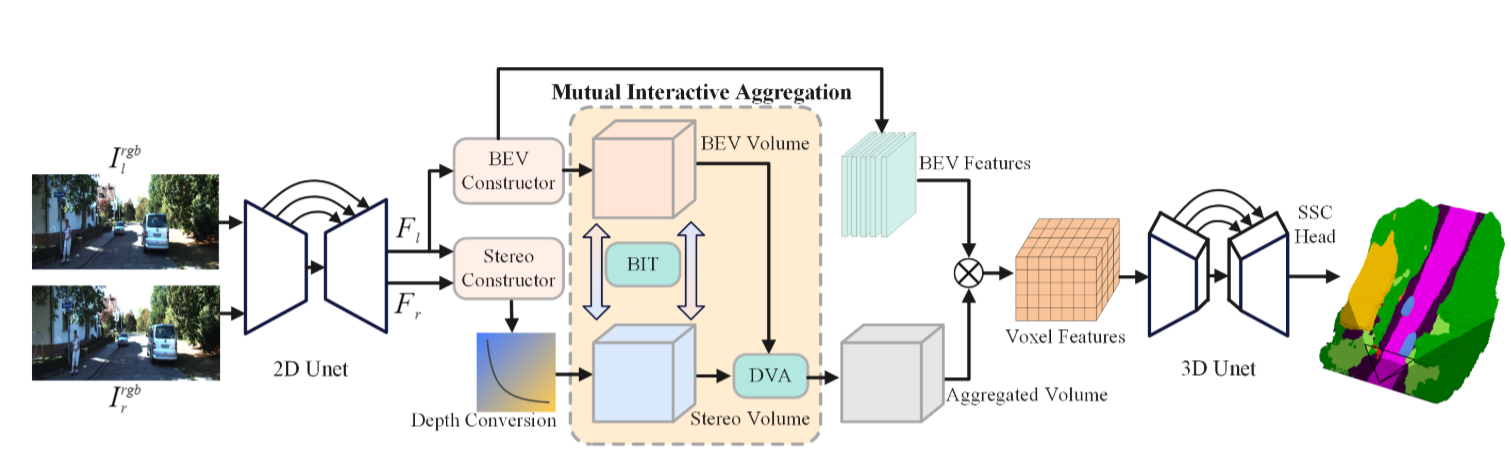
整体的StereoScene框架如上图所示。论文遵循使用连续的2D和3 UNetsf作为backbones。给定输入的双目图像,我们使用2D UNet来提取多尺度特征。BEV潜在体积和立体几何体积分别由BEV构造器和立体构造器构造。为了充分利用这两个卷的互补潜力,提出了一个相互交互聚合模块来相互引导和聚合它们。
代码解释
stereoscene.py代码是一个配置文件,它定义了一个基于 MMDetection3D 的三维计算机视觉模型的配置。以下是代码中各部分的解释:
_base_:这是导入配置的基础文件的地方,custom_nus-3d.py和default_runtime.py包含了一些共享的配置选项。这些基础配置文件通常包括数据集设置、运行时设置等。plugin和plugin_dir:这两个参数用于启用和指定 MMDetection3D 插件。插件是额外的功能模块,可以扩展 MMDetection3D 的功能。img_norm_cfg:这是图像归一化配置,指定了均值和标准差,以便对图像进行归一化。这通常用于图像预处理。class_names:定义了数据集中的类别名称。在这个例子中,有 20 个类别,包括车辆、行人、道路、建筑物等。point_cloud_range、occ_size和lss_downsample:这些参数定义了点云数据的范围、体素的大小和降采样率。它们是用于处理点云数据的重要参数。model:这是定义模型的部分。它指定了模型的各个组件,包括图像骨干网络、头部网络、点云处理头部等。这里使用的是BEVDepthOccupancy模型,该模型在三维计算机视觉中执行深度估计和语义分割任务。dataset_type和data_root:这些参数定义了数据集的类型和数据集的根目录。在这个例子中,使用的是CustomSemanticKITTILssDataset数据集,数据位于./data/occupancy/semanticKITTI/RGB/。train_pipeline和test_pipeline:这些参数定义了数据预处理和增强的步骤。它们包括图像加载、语义分割标签加载、深度图生成等。input_modality:定义了输入的模态,包括激光雷达、相机、雷达、地图等。在这个例子中,仅使用相机数据。test_config和data:这些参数定义了训练和测试数据加载的配置,包括数据预处理、数据集类型、类别、点云范围等。optimizer和optimizer_config:这些参数定义了优化器的类型、学习率和权重衰减等配置。lr_config:定义了学习率调度策略,这里使用的是阶段性学习率下降。checkpoint_config:用于定义模型检查点的保存和保留策略。runner:指定了训练的运行方式,这里使用的是按照 epoch 训练。evaluation:定义了模型评估的配置,包括评估间隔和保存最佳模型的规则。
这个配置文件的目的是定义了一个用于深度估计和语义分割的三维计算机视觉模型,并指定了数据加载和训练配置。模型的结构和数据集的具体细节在其他文件中定义。这个配置文件会被传递给 MMDetection3D 的训练和测试脚本,以实际执行训练和测试任务。
这个配置文件中定义了一个名为model的模型,其结构和配置包括以下几个主要组件:
type: 这里指定了模型的类型为BEVDepthOccupancy,这是一个自定义的三维计算机视觉模型,用于深度估计和语义分割任务。img_backbone: 定义了图像骨干网络的配置,该网络用于提取图像特征。在这个配置中,使用了CustomEfficientNet骨干网络,具体配置包括网络的类型、预训练模型的路径等。img_neck: 这部分定义了图像特征的“颈部”或附加处理,用于进一步处理骨干网络提取的特征。这里使用了SECONDFPN结构,对特征进行了上采样和融合。img_view_transformer: 这是一个自定义的视图变换器,用于将图像特征映射到点云视图,包括视角的转换和体素化。img_bev_encoder_backbone和img_bev_encoder_neck: 定义了用于处理点云的背景信息的网络。img_bev_encoder_backbone用于提取点云的背景特征,img_bev_encoder_neck用于进一步处理这些特征。pts_bbox_head: 这是点云处理头部的配置,用于执行深度估计和语义分割任务。它包括输出通道数、语义分割类别数、点云范围等配置。train_cfg和test_cfg: 分别定义了模型的训练和测试配置,这些配置包括损失函数、评价指标等。
这个model定义了整个三维计算机视觉模型的结构,包括图像骨干网络、点云处理头部等组件。模型将通过这些组件来提取和处理图像和点云数据,以执行深度估计和语义分割任务。配置文件中还包括数据加载和训练策略等,用于训练和测试这个模型。
这个model配置是在使用MMDetection框架时的一种标准格式。MMDetection使用Python的字典格式来组织模型的配置。下面是对这个model配置的格式解释:
type: 这个字段指定了要使用的模型的类型。在这个配置中,type的值是BEVDepthOccupancy,表示要使用名为BEVDepthOccupancy的自定义模型。img_backbone,img_neck,img_view_transformer,img_bev_encoder_backbone,img_bev_encoder_neck,pts_bbox_head: 这些字段用于配置模型中不同组件的设置。每个组件的配置包含了该组件的类型、参数、超参数等。train_cfg和test_cfg: 这些字段定义了模型的训练和测试配置,包括损失函数、评价指标等。这些配置用于指导训练和测试过程。
整个model配置是一个嵌套的字典,用于描述模型的结构和超参数设置。在MMDetection框架中,模型的配置采用了类似于YAML格式的字典结构,以便灵活配置不同的模型和任务。这种配置方式使得用户可以根据自己的需求轻松地定制和修改模型的设置。
bevdepth_occupancy.py在上述代码中,model 的配置与类 BEVDepthOccupancy 相关,特别是与 BEVDepthOccupancy 类中的不同函数和组件有关。
BEVDepthOccupancy 类是一个自定义的模型类,它继承自 BEVDepth 类。以下是与 model 配置中的组件相关的一些重要功能和配置项:
image_encoder和bev_encoder函数:这些函数是模型的核心组件,分别用于处理图像信息和点云信息。image_encoder用于处理输入的图像信息,而bev_encoder用于处理点云信息。这些函数将输入数据转换为特征表示。forward_pts_train函数:这个函数在模型的训练过程中使用,计算了与点云相关的训练损失。这包括点云的目标检测和语义分割任务。extract_img_feat函数:这个函数用于从输入的图像中提取特征。它将输入的图像分别送入image_encoder和img_view_transformer中,然后将它们的输出特征合并。simple_test函数:这个函数用于在测试阶段生成模型的输出。它调用了extract_feat函数来提取特征,然后将这些特征传递给点云检测头部pts_bbox_head,最后生成了测试结果。其他与损失函数、数据预处理、评估等相关的函数:代码中还包括了与训练和测试相关的其他函数,用于处理损失函数的计算、数据的预处理以及评估模型性能等任务。
总的来说,model 配置中的组件是 BEVDepthOccupancy 类中的一部分,用于定义模型的结构和训练/测试过程中的操作。这些组件协同工作以实现点云目标检测和语义分割的任务。不同的组件负责处理不同类型的输入数据(图像、点云等)并生成相应的特征表示,最终用于模型的训练和测试。这种模块化的设计使得模型可以方便地扩展和配置,以适应不同的应用场景。
occhead.py这是一个名为OccHead的模型头,主要用于3D语义分割任务。以下是对该头部的关键要点:
输入和输出:
- 输入:
OccHead头部的输入包括体素特征(voxel_feats)以及点云信息(points)。 - 输出:它的输出通常有两部分,一部分是用于体素级别的语义分割(
output_voxels),另一部分是用于点云级别的语义分割(output_points)。
- 输入:
监督方式:
- 该头部支持两种不同级别的监督方式:体素级别和点云级别。
- 体素级别监督是指根据体素特征生成语义分割结果,用于离散的体素数据。
- 点云级别监督是指根据点云信息生成语义分割结果,用于稠密点云数据。
损失函数:
- 对于体素级别监督,支持交叉熵(
voxel_ce)、Lovasz-Softmax(voxel_lovasz)、Voxel Semantic Scaling(voxel_sem_scal)、Voxel Geometric Scaling(voxel_geo_scal)、IoU损失(voxel_dice)等损失函数。 - 对于点云级别监督,支持交叉熵(
point_ce)和Lovasz-Softmax(point_lovasz)损失函数。
- 对于体素级别监督,支持交叉熵(
学习策略:
- 对于体素级别监督,通过卷积操作生成语义分割结果。
- 对于点云级别监督,采样相关的体素特征和图像特征,然后使用多层感知机(Mlp)处理这些特征生成点云级别的语义分割结果。
语义Kitti:
- 该模型头部支持语义Kitti数据集,并提供了相关的损失函数和度量指标。
损失权重:
- 您可以设置不同损失函数的权重,以控制它们对最终损失的贡献。
可选功能:
- 该模型头部支持不同的可选功能,如软权重(
soft_weights)和图像特征采样(sampling_img_feats)。
- 该模型头部支持不同的可选功能,如软权重(
其他:
- 还包括一些图像处理操作,如上采样和网格采样。
总之,OccHead是一个用于语义分割任务的多功能头部,支持体素级别和点云级别的监督,提供了多种损失函数和度量指标以用于不同的数据集和任务。这些选择和配置可以根据具体的任务需求进行调整和优化。



