OCC-VO: Dense Mapping via 3D Occupancy-Based Visual Odometry for Autonomous Driving
论文链接:OCC-VO-pdf
代码链接:OCC-VO-py
生成面向自动驾驶的基于3D占用栅格的视觉里程计稠密地图
主要贡献:
OCC-VO框架的设计和开发: 作者设计并开发了OCC-VO框架,该框架接受环视相机图像作为输入,并生成密集语义地图,有助于增强场景理解,从而支持感知和导航等下游任务。
3D语义占用预测模块: 在OCC-VO框架中,使用了名为TPV-Former的开源3D语义占用预测模块,用于将环视相机图像转化为3D语义占用栅格,实现对环境的语义理解。
位姿估计和地图算法的定制: 为了解决3D语义占用地图的配准问题,作者设计了一种专为此任务定制的位姿估计和地图算法。该算法以GICP算法为基础,结合语义约束,以更好地对齐点云数据,特别适用于处理具有相似几何结构但不同语义的场景,如自动驾驶道路表面。
全局语义地图的构建: 在地图创建阶段,借鉴了PFilter中的思想,消除了不可靠的点,从而创建了一个更稳健的全局语义地图。
精准的地图和姿态估计: 最终的成果是经过精心调整的姿态估计和高度准确的地图,为感知和导航任务提供了可靠的基础。
这些贡献共同构成了这项工作的核心,旨在提高环境理解和导航系统的性能,特别是在自动驾驶等领域中。
这段文本提供了关于OCC-VO框架的详细信息,包括作者、代码地址以及主要贡献。以下是以Markdown形式的总结:
摘要
OCC-VO是一个新颖的框架,充分利用深度学习技术,将2D相机图像转化为3D语义占用,以解决自主系统中的视觉里程计(VO)挑战。它使用TPV-Former模块将环视相机图像转化为3D语义占用,经过特定设计的位姿估计和地图算法,包括语义标签滤波器、动态对象滤波器以及Voxel PFilter,生成密集的全局语义地图。在Occ3D-nuScenes数据集上的评估结果表明,OCC-VO相较于ORB-SLAM3取得了更高的成功率和轨迹准确性,成功率提高了20.6%,轨迹准确性提高了29.6%。
主要贡献
设计和开发OCC-VO框架,将环视相机图像转化为密集语义地图,用于增强场景理解和支持感知和导航任务。
使用TPV-Former模块,将环视相机图像转化为3D语义占用栅格。
定制位姿估计和地图算法,包括语义标签滤波器、动态对象滤波器,以及Voxel PFilter,以提高配准和全局地图一致性。
在Occ3D-nuScenes数据集上的评估,显示OCC-VO在自动驾驶场景中取得了较高的准确性和稳健性,尤其相较于ORB-SLAM3。
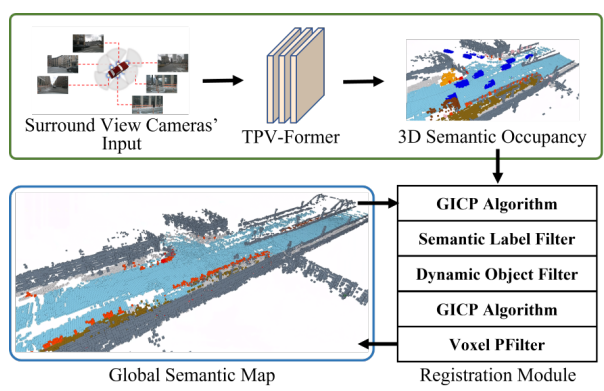
如上图所示,将同时被环绕视图摄像机捕获的6幅图像,由TPV-Former转换为3D语义占用。将得到的三维语义占用率作为点云,通过与全局语义图的配准估计出每一帧的姿态。具体来说,我们使用了GICP算法两次。首先,建立点之间的粗糙对应关系。在此之后,我们使用语义标签过滤器和动态对象过滤器来丢弃错误的匹配,从而细化第二个GICP应用程序的准确性。一旦确定了一个精确的姿势,我们利用Voxel PFilter将数据的框架合并到全局语义地图中,为全局一致性纠正TPV-Former对地图的推断中的错误。
内容概述
系统概述:介绍了OCC-VO的工作流程,包括图像转化、姿态估计、过滤器应用,以及全局地图维护。
语义标签过滤器:介绍了基于语义标签的对象过滤方法,以提高配准准确性。有效地防止了各种物体或曲面之间的错误点匹配对优化解的影响。
动态对象过滤器:解释了如何处理动态对象,以平衡准确性和场景恶化。具体来说,使用语义标签将具有运动潜能的对象从三维语义占用和全局语义地图中分离出来。然后对每个对象进行点云聚类,这些聚类随后被视为统一的对象。利用第一个GICP的转换结果,我们比较了每个物体的位置。这让我们能够识别相对位移,并决定一个物体是否是动态的,是否应该被移除。利用每个输入的静态部分,进行了精细化配准,从而提高了姿态估计的精度。
Voxel PFilter:介绍了引入Voxel PFilter来维护全局地图的一致性,校正网络干扰噪音。
实验:使用Occ3D-nuScenes数据集评估OCC-VO,比较其性能和执行时间分析。
总结
OCC-VO是一个新颖的VO框架,结合3D语义占用栅格,用于自动驾驶场景中的密集地图生成。通过设计的滤波器,OCC-VO在自动驾驶环境中取得了更高的准确性和稳健性。未来的工作将包括将环路闭合检测等模块整合到OCC-VO中,以发展成为一个完整的SLAM系统。
详细阅读细节
挑战一:由于3D语义占用不同于场景结构的原始捕获,例如激光雷达扫描,因此出现了挑战。因此,使用这些数据来执行点云配准带来了几个问题。
- 问题一:三维语义占用的粗分辨率导致地标位置估计的不确定性,进而影响配准的准确性。
- 问题二:由于神经网络模型的不完善,可能导致路标构造不准确甚至部分缺失
- 问题三:区分静止环境和动态对象非常重要,特别是在自动驾驶等应用中,因为它们的匹配可能导致姿态估计不太准确。
解决一:
- 方法一:设计了一种适合三维语义占用的姿态估计和映射算法。以Lidarbased SLAM中常用的GICP算法作为我们的基线。该算法通过特征匹配和迭代优化来实现点云的对齐。
- 方法二:在配准过程中引入语义约束,类似于ColorICP在几何结构相似但语义不同的情况下,例如自动驾驶环境中的路面,这些语义约束非常有效
- 方法三:实现了一个动态目标滤波器,以提高地图精度和姿态估计精度
- 方法四:在映射阶段,我们利用PFilter中的思想消除不可靠点,构建更健壮的全局语义映射。最终结果是一个微调的姿态估计和一个高度精确的地图



