主要记录SSC中的理论与代码实现(第二章)
主要从开篇之作SSCNet(2017)开始讲起,然后按激光雷达点云输入(LMSCNet,2020;S3CNet,2021a;JS3C-Net,2021),单双目以及两者融合的顺序
紧接上回,双目视觉的解决方案
OccDepth
第一个只输入视觉的立体3D SSC方法。为了有效地利用深度信息,提出了一种立体软特征分配(Stereo-SFA)模块,通过隐式学习立体图像之间的相关性来更好地融合3D深度感知特征。占用感知深度(OAD)模块将知识提取与预先训练的深度模型明确地用于生成感知深度的3D特征。此外,为了更有效地验证立体输入场景,我们提出了基于TartanAir的SemanticTartanAir数据集。这是一个虚拟场景,可以使用真实的地面实况来更好地评估该方法的有效性。
代码链接如下: OccDepth: A Depth-aware Method for 3D Semantic Occupancy Network, arXiv 2023.
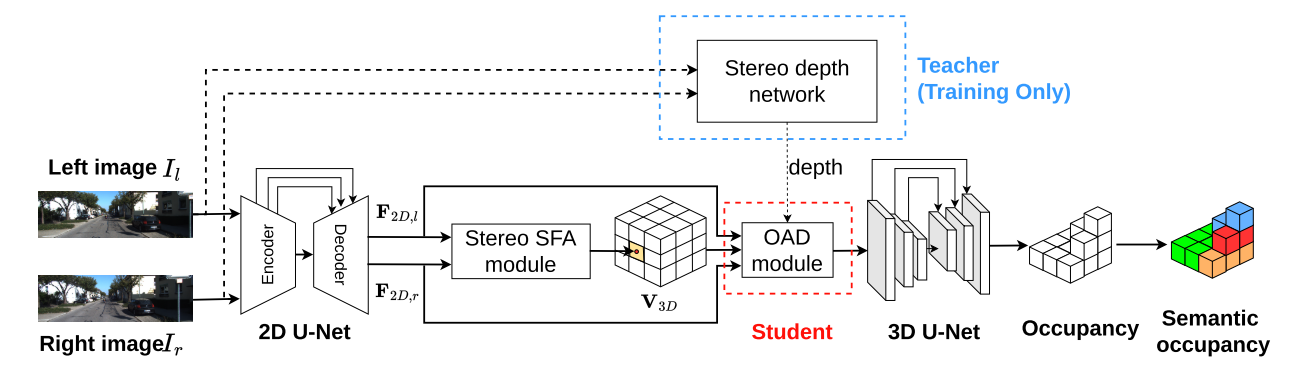
3D SSC是通过桥接立体SFA模块来从立体图像中推断出来的,该模块用于将特征提升到3D空间,OAD模块用于增强深度预测,3D U-Net用于提取几何结构和语义。立体深度网络仅在训练中用于提供深度监督。
代码介绍
代码方面类似monoscene,都使用了使用PyTorch Lightning,训练代码train.py介绍如下:
导入模块: 脚本以各种导入语句开始,包括数据模块、模型、实用程序和配置。
Hydra配置:
main函数被@hydra.main装饰,这表明可以使用Hydra进行配置,Hydra是一个强大的配置管理工具。配置路径根据config_path环境变量确定。主要函数:
main函数是脚本的入口点。它加载使用Hydra指定的配置。实验名称: 基于各种配置设置,创建了
exp_name变量,用于命名实验。数据模块设置: 根据选择的数据集(例如 “kitti”、”NYU” 或 “tartanair”),实例化了相应的数据模块。数据模块处理数据加载和预处理。
模型初始化: 创建了“OccDepth”模型的实例。模型接受各种参数,包括类别名称、类别权重和配置设置。
日志记录和回调: 根据配置,脚本设置了使用TensorBoard的日志记录,并定义了各种回调,包括模型检查点和学习率监视器。
从上次继续或从头开始训练: 脚本检查模型检查点文件(例如 “last.ckpt”)是否存在。如果存在,则继续从那个点训练。否则,从头开始训练模型。
训练: 脚本初始化PyTorch Lightning Trainer,并调用
fit方法,使用指定的数据模块来训练模型。训练过程由各种配置设置控制,包括GPU数量、梯度裁剪和其他超参数。随机种子初始化: 使用
seed_everything设置随机种子。执行: 当运行脚本时,将调用主函数。
总之,该脚本旨在训练”OccDepth”模型,可用于不同的数据集,并允许使用Hydra进行灵活的配置。它设置数据加载、模型和训练流程,并且如果有可用的检查点,可以从那个点继续训练。训练结果和日志将保存在配置中指定的目录中。
接着看一下OccDepth.py的模型
“OccDepth” 是一个PyTorch模型,用于语义分割和深度预测的任务。这个模型主要由以下组件构成:
**构造函数
__init__**:构造函数初始化模型的各种参数和组件。以下是一些重要的参数和配置项:class_names:类别名称列表,用于分类问题。class_weights:类别权重,用于处理类别不平衡的情况。class_weights_occ:用于处理类别不平衡的另一组类别权重。full_scene_size:场景的完整尺寸。project_res:2D特征到3D特征的投影分辨率。config:模型的配置参数,包括超参数等。infer_mode:是否为推理模式,如果是,则不使用上下文先验(context prior)。
特征提取器:使用UNet结构进行特征提取。这些提取到的特征被用于语义分割。
2D-3D投影层:这部分用于将2D特征映射到3D特征。包括两种投影方法:”flosp” 和 “flosp_depth”。
- “flosp” 模型对2D特征进行投影以生成3D场景特征。
- “flosp_depth” 模型不仅对2D特征进行投影,还用深度信息进行额外的处理。
3D语义分割头部:这一部分负责将3D特征用于语义分割。具体的网络结构可能取决于不同的数据集(”NYU” 或 “kitti”)。
2D语义分割头部:用于2D语义分割的头部网络。
深度预测头部:根据需求,模型可以生成深度预测。
训练、验证和测试步骤:这些步骤在不同的数据集和任务上运行,计算损失、评估性能,并记录指标。这包括分类损失、语义分割IoU、精度和召回。
优化器和学习率调度器:在
configure_optimizers方法中配置了优化器和学习率调度器。通常使用AdamW优化器和学习率衰减策略。模型的输入数据预处理:输入数据是图像,通过
process_rgbs方法处理,生成特征图。模型的前向传播:通过
forward方法执行模型的前向传播操作,包括特征提取、2D-3D投影、3D语义分割等。损失计算:根据任务类型和模型预测,计算不同的损失,包括分类损失、语义分割损失、深度损失等。
评估指标:评估模型性能,包括IoU、精度、召回等。
超参数配置:模型的超参数(如学习率、权重衰减等)在构造函数中进行了设置。
导出模型和计算FLOPs和参数数量:通过条件选择,模型可以导出为ONNX格式,并计算模型的浮点运算数(FLOPs)和参数数量。
总体而言,”OccDepth” 模型用于处理多视图数据的语义分割和深度预测任务,具有丰富的配置选项和评估指标,以满足不同数据集和任务的需求。这个模型的复杂性和功能强大,适用于一系列3D场景理解任务。
SFA.py用于执行2D到3D的稀疏特征聚合。以下是该模块的功能和工作原理的简要说明:
SFA类继承自nn.Module,它包含了一个用于2D到3D投影的聚合过程。__init__函数接受以下参数:scene_size:3D场景的大小,通常表示为一个包含三个维度大小的元组或列表。dataset:表示使用的数据集的名称,例如”NYU”或”kitti”。project_scale:投影尺度,用于将2D特征映射到3D场景中。
forward函数执行2D到3D的稀疏特征聚合操作:- 输入
x2d是包含多个视图的2D特征的张量。 projected_pix是每个像素在3D场景中的投影坐标。fov_mask是表示视野范围的掩码。
主要的工作步骤包括:
- 对于每个视图,将2D特征映射到3D场景中。这是通过计算权重和聚合来实现的。
- 对不同视图之间的特征进行加权平均。
- 根据数据集类型(”NYU”或”kitti”)重塑3D场景特征的形状。
- 输入
这个模块的关键思想是将多个2D视图的特征信息聚合到3D场景中,以增强3D场景的表示。这对于处理多视图或多帧输入的问题(如3D物体检测或重建)非常有用。模块的实现中包含了一系列的数学运算,包括加权平均和角度余弦相似度等。这有助于捕捉不同视图之间的相关性和信息融合。
这是一个名为 FlospDepth 的PyTorch模块,通常用于深度预测和点云处理。以下是该模块的功能和工作原理的简要说明:
初始化和配置:
__init__函数接受多个参数,包括场景边界、深度范围、输出通道数等,用于初始化模型的各个部分和配置。- 可以选择不同的深度网络(
DepthNet)配置。
深度网络:
DepthNet是一个用于预测深度图的子模块。- 它接受输入特征图,相机内参矩阵等信息,并返回深度图。
- 深度图是在该模块中预测的,并且经过 softmax 处理。
Voxel 特征聚合:
- 从不同视角的深度图生成体素特征,这是通过采样视锥体积并将视锥体积中的深度信息投影到3D体素网格中实现的。
- 选择了不同的体素聚合方式,包括”mean”和”sum”,以聚合多个视角的信息。
配置和参数:
- 一些初始化参数,如体素大小、坐标、数量等,被存储在模块的缓冲区中,以便后续使用。
- 还有一些配置参数,如深度范围和体素网格大小等。
推理模式和训练模式:
- 模块支持两种模式,即推理模式和训练模式。
- 在推理模式中,模块可以接受缩放后的像素大小(
scaled_pixel_size),以适应不同的尺度。 - 在训练模式中,模块接受相机内参矩阵、相机到世界坐标的变换矩阵等信息,用于生成体素网格。
这个模块的关键思想是从多个视角的深度图生成3D体素网格,然后通过合适的聚合方式将这些体素特征合并在一起。这对于许多3D场景理解任务,如点云分割、物体检测和语义分割,都是有用的。
VoxFormer
代码链接如下:VoxFormer: a Cutting-edge Baseline for 3D Semantic Occupancy Prediction, CVPR 2023
一种基于 Transformer 的语义场景完成框架,可以仅从 2D 图像输出完整的 3D 体积语义。我们的框架采用两阶段设计,从深度估计中一组稀疏的可见和占用体素查询开始,然后是从稀疏体素生成密集 3D 体素的致密化阶段。这种设计的一个关键思想是,2D 图像上的视觉特征仅对应于可见的场景结构,而不对应于被遮挡或空白的空间。因此,从可见结构的特征化和预测开始更为可靠。一旦我们获得了稀疏查询集,我们就应用屏蔽自动编码器设计,通过自注意力将信息传播到所有体素。
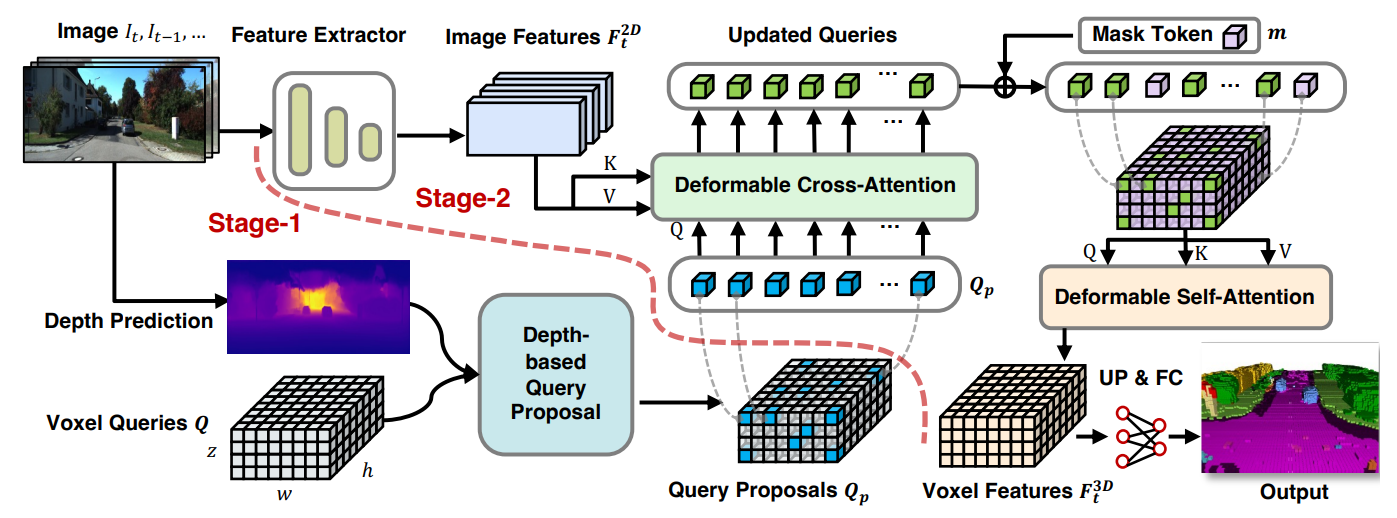
VoxFormer的总体框架如上图所示。给定 RGB 图像,由 ResNet50 提取 2D 特征,并由现成的深度预测器估计深度。校正后的估计深度启用了与类别无关的查询建议阶段:将选择位于占用位置的查询来与图像特征进行可变形交叉注意。之后,将添加掩模标记以通过可变形自注意力来完成体素特征。精炼后的体素特征将被上采样并投影到输出空间以进行每体素语义分割。请注意,我们的框架支持单个或多个图像的输入。
VoxFormer由类不可知的查询建议(阶段-1)和类特定的语义分割(阶段-2)组成,其中阶段-1提出了一组稀疏的占用体素,阶段-2完成了从阶段-1给出的建议开始的场景表示。具体而言,阶段1具有轻量级的基于2D CNN的查询建议网络,该网络使用图像深度来重建场景几何结构。然后,它从整个视场上预定义的可学习体素查询中提出了一组稀疏的体素。
代码分析
第一阶段的查询建议网络(QPN),根据深度决定要查询哪些体素:被占用的体素值得仔细关注,而空的体素可以从组中分离出来。给出二维RGB观测,首先基于深度估计得到场景的2.5D表示。然后,通过占用率预测获得三维查询位置,从而纠正图像深度不准确的问题。
代码qpn.py,基于mmdet3d
以下是对配置文件的更详细分析:
_gamma_和_alpha_:这些参数可能是用于模型的超参数调整,但配置文件中没有提供它们的具体用途。通常,_gamma_和_alpha_可能会在训练过程中被动态地调整以提高模型性能。_nsweep_:指定了数据集中采样的扫描次数,这可能与数据集的采样策略和数据增强有关。在一些场景下,多次扫描可以提供更多的信息,例如在激光雷达数据中。_depthmodel_:这个参数指定了深度模型的名称或配置,定义了一个名为 MSNet3D 的三维立体匹配网络模型。这个模型主要用于深度估计和立体匹配任务。point_cloud_range和voxel_size:定义了点云的范围和体素的大小。这些参数用于将点云数据转化为体素表示,以便于模型的处理。point_cloud_range指定了点云数据的范围,voxel_size指定了体素的大小。img_norm_cfg:定义了图像的归一化配置,包括均值、标准差和是否将图像转化为RGB格式。这些配置通常用于对图像进行预处理,以便输入到深度学习模型中。class_names:包含目标类别的列表,用于指定模型需要检测或分类的物体类别。在这个配置中,包含了诸如’car’、’truck’、’pedestrian’等物体类别。input_modality:定义了数据输入模态,包括激光雷达、摄像机、雷达、地图和外部信息。这些模态可以用于训练和测试模型,根据任务需要选择合适的输入模态。model:指定了要训练的深度学习模型的配置。这个模型被命名为LMSCNet_SS,并包括类别数、输入维度等信息。train_cfg:包含了训练配置,如点云的网格大小、体素大小、分配器配置等。这些配置参数影响了训练过程中的数据处理和损失计算。dataset_type和data_root:定义了数据集的类型和根目录,这将用于加载训练、验证和测试数据。test_pipeline:定义了测试数据的预处理管道,这里加载了多视角图像。预处理管道用于对输入数据进行处理以供模型使用。data:包含了数据集的设置,包括训练、验证和测试数据的类型、数据根目录、预处理根目录等。数据采样器也在这里配置。optimizer和optimizer_config:定义了优化器的类型、学习率、权重衰减等参数。AdamW优化器用于模型的权重更新。lr_config:指定了学习率的调整策略,包括余弦退火、预热等。这些策略用于在训练过程中调整学习率。total_epochs:指定了总的训练轮数,模型将在这些轮数内进行训练。evaluation:定义了评估的间隔和评估的管道,用于在训练过程中定期评估模型的性能。runner:指定了训练器的类型和最大训练轮数,以及其他训练参数。log_config:包含了日志的配置,包括日志的记录间隔和日志类型。这些日志用于跟踪训练过程中的性能。checkpoint_config:定义了模型检查点的保存间隔,即模型在训练过程中的保存频率。
分析一下_depthmodel_指定的MSNet3D和model指定的LMSCNet_SS模型
首先逐步分析代码MSNet3D的关键部分:
hourglass3D类:这是一个用于定义三维卷积层的类,由多个 MobileV2_Residual_3D 模块组成。MobileV2_Residual_3D 模块用于构建深度神经网络的基本构建块。这个类定义了前向传播方法,通过堆叠卷积和反卷积层来构建一个”U”形网络。MSNet3D类:这是主要的网络模型,包含了特征提取、特征匹配、立体匹配和深度估计等部分。它包括以下关键组件:feature_extraction:特征提取模块。dres0和dres1:用于处理立体匹配代价体积的 MobileV2_Residual_3D 模块。encoder_decoder1、encoder_decoder2和encoder_decoder3:使用hourglass3D模块实现的编码器-解码器结构。classif0、classif1、classif2和classif3:用于执行立体匹配和深度估计的模块。
在前向传播方法中,通过输入左视图和右视图的图像数据
L和R,首先提取特征,然后构建立体匹配代价体积。接下来,对代价体积进行多尺度编码器-解码器处理,最终产生深度估计。
再好好分析一下LMSCNet_SS这个模型的主要组件和架构摘要:
这个模型在
mmdet3d框架中注册为自定义检测器。它继承自
MVXTwoStageDetector,这是mmdet3d框架中用于3D物体检测的基础类。模型包括多个组件,包括编码器、解码器和分割头。它以3D占用网格数据作为输入,用于预测语义标签。
编码器通过多个2D卷积层处理输入数据,将特征图下采样到较小的尺寸。
解码器由一系列反卷积层组成,将特征图上采样到所需的输出比例。
分割头进一步处理特征图,以生成语义分割预测。
训练时计算损失,其中包括二元交叉熵损失(BCE)和其他特定于语义分割的损失。
forward方法用于处理训练和测试模式,训练时返回损失,测试时返回预测。代码包括用于存储的二进制数据的打包和解包函数。
使用
auto_fp16装饰器可以自动应用混合精度训练。
第2阶段基于一种新颖的稀疏到密集类MAE架构,如图(a)所示。它首先通过允许所提出的体素关注图像观察来加强其特征化。接下来,未提出的体素将与可学习的掩码标记相关联,并且将通过自注意来处理全套体素,以完成每体素语义分割的场景表示。
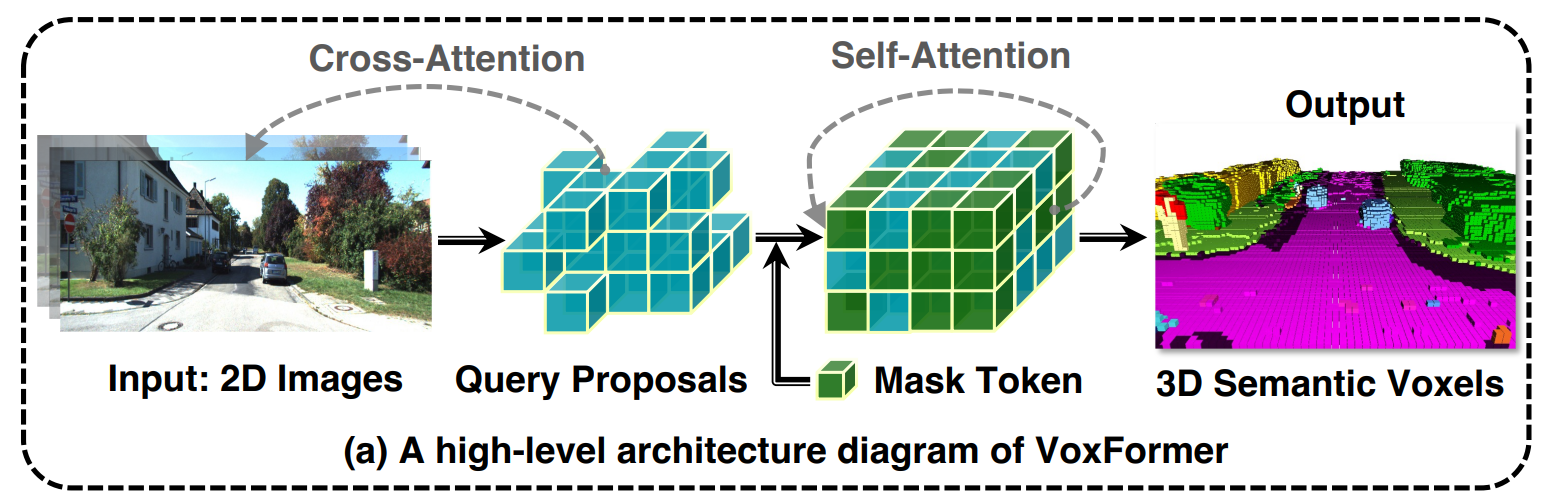
请注意,这里提供了两个版本的VoxFormer,一个只以当前图像作为输入(VoxFormer- S),另一个以当前图像和前4个图像作为输入(VoxFormer- T)。
VoxFormer-S是一个用于3D物体检测的模型,该模型使用多通道LiDAR数据和图像数据进行训练。以下是对这个配置文件的主要部分进行的详细分析:
work_dir定义了模型训练期间的工作目录,训练日志和模型检查点将在此目录中保存。在这里,工作目录被设置为’result/voxformer-S’。_base_包含了其他配置文件的路径,这些文件会被合并到当前配置中。在这里,使用了默认的运行时配置文件’default_runtime.py’。plugin和plugin_dir是用于配置MMDet3D插件的选项。plugin设置为True,表示启用插件,而plugin_dir指定了插件的目录。_num_layers_cross_和_num_points_cross_分别定义了交叉变换器(cross_transformer)中的层数和点数。这些参数用于模型的 Transformer 层设置。_dim_定义了模型的嵌入维度。在这里,它被设置为128。_pos_dim_定义了位置编码的维度,通常是嵌入维度的一半。这里的值由_dim_除以2计算。_ffn_dim_定义了Feedforward网络的维度,通常是嵌入维度的两倍。在这里,它被设置为256。_num_levels_定义了输出级别的数量。这里设置为1,表示只有一个输出级别。_labels_tag_和_num_cams_用于配置数据集标签和相机的数量。这些参数是与数据集相关的配置。point_cloud_range和voxel_size分别定义了点云范围和体素大小。这些参数也是与数据集相关的配置。_sem_scal_loss_和_geo_scal_loss_用于配置语义分割损失和几何损失的选项。这些参数控制是否启用语义分割损失和几何损失。_depthmodel_是深度模型的选择。它在数据集中用于深度估计。_nsweep_定义了查询建议网络的扫描次数。这是一个与数据集和模型训练相关的参数。model部分定义了VoxFormer模型的结构,包括图像骨干网络、特征金字塔网络、以及交叉和自注意力变换器。模型结构的配置包括不同的组件和层,用于处理图像和点云数据。dataset_type和data部分配置了数据集的类型、数据根目录以及训练、验证和测试数据集的设置。这些设置与数据集的加载和处理相关。optimizer、optimizer_config和lr_config用于配置优化器、学习率衰减策略以及其他优化选项。这些设置用于模型训练的优化配置。total_epochs定义了总的训练周期数。在这里,设置为20个周期。evaluation部分配置了评估的间隔。这指定了多少个周期后进行一次模型评估。runner部分定义了训练过程的运行器。这包括如何管理训练循环以及模型的保存和加载。log_config部分配置了训练日志的记录方式。在这里,设置了文本记录和Tensorboard记录。checkpoint_config用于配置模型检查点的保存间隔。在这里,设置为None,表示没有指定检查点的保存间隔。
VoxFormer- T一个用于3D物体检测的模型,结合了LiDAR点云数据和图像数据。以下是对这个配置文件的主要部分进行的详细分析:
work_dir定义了模型训练期间的工作目录,训练日志和模型检查点将在此目录中保存。在这里,工作目录被设置为’result/voxformer-T’。_base_包含了其他配置文件的路径,这些文件会被合并到当前配置中。在这里,使用了默认的运行时配置文件’default_runtime.py’。plugin和plugin_dir是用于配置MMDet3D插件的选项。plugin设置为True,表示启用插件,而plugin_dir指定了插件的目录。_num_layers_cross_和_num_points_cross_分别定义了交叉变换器(cross_transformer)中的层数和点数。这些参数用于模型的 Transformer 层设置。_num_layers_self_和_num_points_self_分别定义了自注意力变换器(self_transformer)中的层数和点数。这些参数也用于模型的 Transformer 层设置。_dim_定义了模型的嵌入维度。在这里,它被设置为128。_pos_dim_定义了位置编码的维度,通常是嵌入维度的一半。这里的值由_dim_除以2计算。_ffn_dim_定义了Feedforward网络的维度,通常是嵌入维度的两倍。在这里,它被设置为256。_num_levels_定义了输出级别的数量。这里设置为1,表示只有一个输出级别。_labels_tag_和_num_cams_用于配置数据集标签和相机的数量。这些参数是与数据集相关的配置。_temporal_定义了用于数据集的时间轴信息。在这里,使用了一个包含-12、-9、-6和-3的列表,这表示了不同时间步长的输入数据。point_cloud_range和voxel_size分别定义了点云范围和体素大小。这些参数也是与数据集相关的配置。_sem_scal_loss_和_geo_scal_loss_用于配置语义分割损失和几何损失的选项。这些参数控制是否启用语义分割损失和几何损失。_depthmodel_是深度模型的选择。它在数据集中用于深度估计。_nsweep_定义了查询建议网络的扫描次数。这是一个与数据集和模型训练相关的参数。model部分定义了VoxFormer-T模型的结构,包括图像骨干网络、特征金字塔网络、以及交叉和自注意力变换器。模型结构的配置包括不同的组件和层,用于处理图像和点云数据。dataset_type和data部分配置了数据集的类型、数据根目录以及训练、验证和测试数据集的设置。这些设置与数据集的加载和处理相关。optimizer、optimizer_config和lr_config用于配置优化器、学习率衰减策略以及其他优化选项。这些设置用于模型训练的优化配置。total_epochs定义了总的训练周期数。在这里,设置为20个周期。evaluation部分配置了评估的间隔。这指定了多少个周期后进行一次模型评估。runner部分定义了训练过程的运行器。这包括如何管理训练循环以及模型的保存和加载。log_config部分配置了训练日志的记录方式。在这里,设置了文本记录和Tensorboard记录。checkpoint_config用于配置模型检查点的保存间隔。在这里,设置为None,表示没有指定检查点的保存间隔。
这两份代码之间的主要区别:
时间轴差异:
voxformer-S.py使用了一个空的时间轴,_temporal_参数为空列表。voxformer-T.py使用了包含多个时间步长的时间轴,_temporal_参数设置为包含了[-12, -9, -6, -3]的列表。
相机数量差异:
voxformer-S.py中的_num_cams_参数设置为1,表示只使用单个相机。voxformer-T.py中的_num_cams_参数设置为5,表示使用5个相机。
输出级别的数量:
- 两者中的
model部分都设置了num_outs参数_num_levels_,但两者都将其设置为1,表示只有一个输出级别。
- 两者中的
**OccFormer: Dual-path Transformer for Vision-based 3D Semantic Occupancy Prediction, ICCV 2023
voxformer-S.py和voxformer-T.py都配置了相同的数据集类型dataset_type,数据根目录data_root,以及训练、验证和测试数据集的相关设置。
总的来说,主要的区别在于时间轴配置、相机数量以及数据集的数据加载。voxformer-S.py 使用了一个静态的时间轴和单个相机,而 voxformer-T.py 使用了多个时间步长和多个相机。这些差异可能是用于处理不同类型数据集或任务的配置。要选择合适的配置,需要考虑你的数据集和任务的特定需求。
OccFormer
代码链接:OccFormer: Dual-path Transformer for Vision-based 3D Semantic Occupancy Prediction, ICCV 2023
自动驾驶的视觉感知经历了从鸟瞰图(BEV)表示到 3D 语义占用的转变。与BEV平面相比,3D语义占用进一步提供了沿垂直方向的结构信息。本文提出了 OccFormer,一种双路径transformer网络,可有效处理 3D 体积以进行语义占用预测。OccFormer 实现了对相机生成的 3D 体素特征的远程、动态且高效的编码。它是通过将繁重的 3D 处理分解为沿水平面的局部和全局transformer路径而获得的。对于占用解码器,我们通过提出保留池和类引导采样来适应 3D 语义占用的普通 Mask2Former,这显着减轻了稀疏性和类不平衡。实验结果表明,OccFormer 显着优于 SemanticKITTI 数据集上的语义场景完成和 nuScenes 数据集上的 LiDAR 语义分割的现有方法。
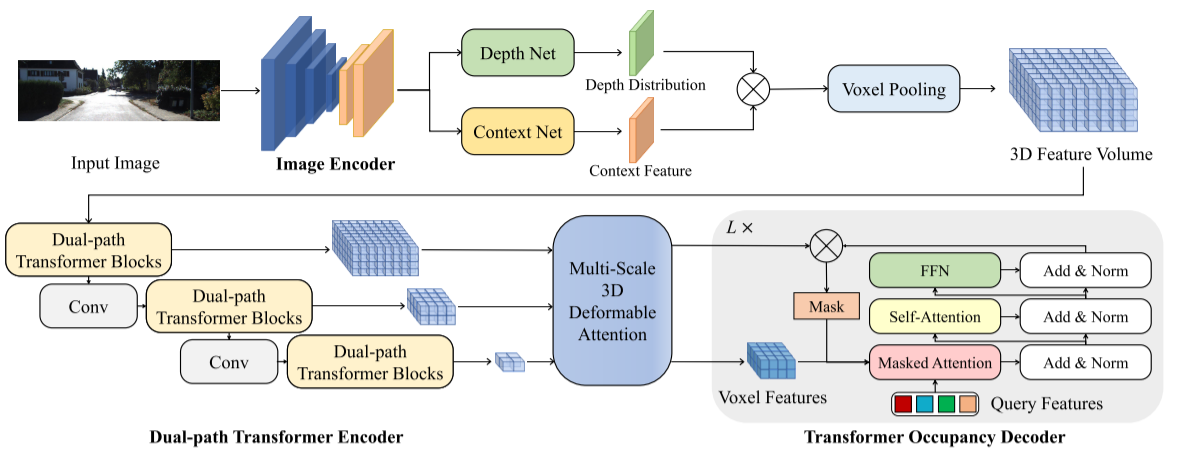
该Pipeline由用于提取多尺度2D特征的图像编码器、用于将2D特征提升到3D体积的图像到3D变换以及用于获得3D语义特征并预测3D语义占用的基于变换器的编码器-解码器组成。
代码分析
occformer_kitti.py这段代码是关于 OccFormer 模型的kitti数据集的配置,以下是对主要部分的详细分析:
基础配置:
_base_参数包括两个配置文件,一个是custom_nus-3d.py,另一个是default_runtime.py。sync_bn和plugin分别设置为True,启用了同步批处理规范化(Batch Normalization)和插件(plugin)功能。
数据设置:
class_names定义了类别的名称,包括一些物体类别(如汽车、自行车等)和一些特殊类别(如未标记、道路、人等),总共有20个类别。point_cloud_range指定了点云的范围。occ_size定义了3D体素的尺寸。lss_downsample指定了生成3D体素(Local Semantic Segmentation, LSS)时的下采样比率。voxel_size是通过计算point_cloud_range和occ_size得出的体素大小。
模型配置:
model部分配置了OccFormer模型的架构,包括以下组件:img_backbone使用自定义的EfficientNet骨干网络。img_neck使用SECONDFPN的颈部结构。img_view_transformer使用ViewTransformerLiftSplatShootVoxel进行图像到点云的转换。img_bev_encoder_backbone使用OccupancyEncoder进行BEV编码。img_bev_encoder_neck使用多层Transformer解码器。pts_bbox_head配置了Mask2FormerOccHead头部,用于形状转换、损失计算等。
数据集配置:
- 数据集类型
dataset_type设置为CustomSemanticKITTILssDataset。 data部分配置了数据加载和处理的设置,包括训练、验证和测试数据集。
- 数据集类型
优化器和学习率策略:
optimizer部分配置了AdamW优化器,包括学习率、权重衰减等设置。lr_config配置了学习率策略,采用阶段性的学习率衰减策略。
检查点和日志配置:
checkpoint_config配置了检查点的保存策略。runner部分定义了运行的类型和最大训练轮数。evaluation部分配置了模型的评估策略。
总结,这段代码配置了 OccFormer 模型,包括图像和点云的处理、模型架构、数据加载、优化器、学习率策略和训练设置等。这个模型用于语义分割任务,能够将点云数据映射到3D体素空间,然后使用Transformer结构进行处理,最终输出语义分割结果。这是一个复杂的3D视觉模型,适用于点云数据的语义分割任务。
occformer_nusc_r50_256x704.py这段代码是关于 OccFormer 模型的nuScenes数据集的配置,以下是对主要部分的详细分析:
基础配置:
_base_参数包括两个配置文件:custom_nus-3d.py和default_runtime.py。sync_bn和plugin分别设置为True,启用了同步批处理规范化(Batch Normalization)和插件(plugin)功能。plugin_dir指定插件的目录路径。img_norm_cfg包含了图像的标准化配置,包括均值、标准差和是否转换为RGB格式。
类别和点云范围:
class_names包含了物体类别的名称,共17个类别。num_class表示类别的总数。point_cloud_range定义了点云的范围。occ_size指定了3D体素的尺寸。lss_downsample是用于生成3D体素(Local Semantic Segmentation, LSS)时的下采样比率。voxel_size是通过计算point_cloud_range和occ_size得出的体素大小。
数据配置:
data_config包含了数据加载和处理的设置,包括相机信息、输入图像大小、数据增强参数等。grid_config包含了3D卷积网格的配置,定义了xyz范围和体素大小等信息。
模型配置:
model部分配置了OccupancyFormer模型,包括以下组件:img_backbone使用了ResNet-50骨干网络。img_neck使用SECONDFPN的颈部结构。img_view_transformer用于将图像信息转换为3D体素。img_bev_encoder_backbone使用OccupancyEncoder进行BEV编码。img_bev_encoder_neck使用多层Transformer解码器。pts_bbox_head配置了Mask2FormerNuscOccHead头部,用于形状转换、损失计算等。
数据集配置:
dataset_type设置为CustomNuScenesOccLSSDataset,指定了数据集类型。data_root指定了数据集的根目录。train_pipeline和test_pipeline分别配置了训练和测试数据的处理流程。
优化器和学习率策略:
optimizer部分配置了AdamW优化器,包括学习率、权重衰减等设置。optimizer_config包含了梯度剪切的设置。lr_config配置了学习率策略,采用阶段性的学习率衰减策略。
检查点和日志配置:
checkpoint_config配置了检查点的保存策略。runner部分定义了运行的类型和最大训练轮数。evaluation部分配置了模型评估的策略,包括评估间隔、评估指标等。
这两段代码是针对不同的任务和数据集的配置文件,它们的主要区别在于以下几个方面:
任务和数据集:
- 第一个代码段是针对SemanticKITTI数据集的,主要用于3D语义分割任务。
- 第二个代码段是为了处理NuScenes数据集的,用于3D物体检测和语义分割任务。
类别和数据范围:
- 第一个代码段中的
class_names包含了SemanticKITTI数据集的类别,而第二个代码段的class_names包含了NuScenes数据集的类别,因此它们的类别列表是不同的。 point_cloud_range和occ_size也在两个代码段中有所不同,因为它们对应不同数据集的点云范围和3D体素尺寸。
- 第一个代码段中的
数据处理和数据加载:
- 两个代码段中的数据加载和处理流程是不同的。第一个代码段包含了用于加载SemanticKITTI数据的处理流程,而第二个代码段包含了用于加载NuScenes数据的处理流程。
模型配置:
- 模型配置在两个代码段中也存在差异。虽然它们都使用了Transformer结构,但底层的图像骨干网络、特征提取过程、解码器结构等都可能有所不同。
数据路径和检查点路径:
- 数据路径和检查点路径在两个配置中也不同。它们指定了数据集的根目录和用于预训练模型的检查点文件。
总的来说,这两段代码主要区别在于它们的应用领域、数据集和任务的不同。第一个代码段适用于SemanticKITTI数据集的3D语义分割任务,而第二个代码段则适用于NuScenes数据集的3D物体检测和语义分割任务。每个配置都经过仔细调整,以满足其特定的数据和任务需求。
TPVFormer
代码链接: TPVFormer: An academic alternative to Tesla’s Occupancy Network, CVPR2023
以视觉为中心的自动驾驶感知的现代方法广泛采用鸟瞰图(BEV)表示来描述 3D 场景。尽管它比体素表示效率更高,但它很难用单个平面描述场景的细粒度 3D 结构。为了解决这个问题,我们提出了一种三透视图(TPV)表示法,它与 BEV 一起提供了两个额外的垂直平面。我们通过对三个平面上的投影特征求和来对 3D 空间中的每个点进行建模。为了将图像特征提升到3D TPV空间,我们进一步提出了一种基于transformer的TPV编码器(TPVFormer)以有效地获得TPV特征。我们采用注意力机制来聚合每个 TPV 平面中每个查询对应的图像特征。实验表明,我们用稀疏监督训练的模型可以有效地预测所有体素的语义占用率。我们首次证明,在 nuScenes 上的 LiDAR 分割任务中,仅使用相机输入就可以实现与基于 LiDAR 的方法相当的性能。
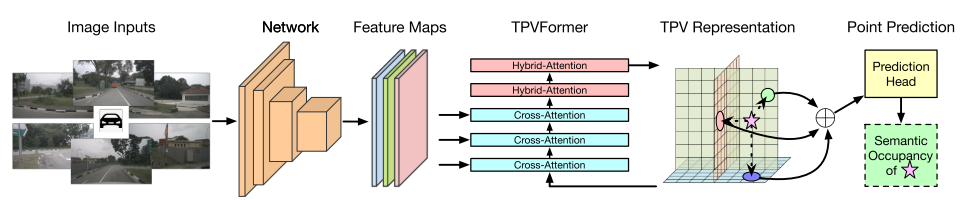
三维语义占用预测TPVFormer框架。我们采用一个图像骨干网来提取多摄像机图像的多尺度特征。然后通过交叉注意自适应提升二维特征到TPV空间,并利用交叉视图混合注意实现TPV平面之间的交互。为了预测三维空间中一个点的语义占用情况,我们在三个TPV平面上的投影特征的总和上应用一个轻量级预测头。
代码分析
这里我们只看TPVFormer 进行 3D 语义占用预测任务代码tpv04_occupancy.py
这段代码是一个配置文件,用于定义一个名为 “TPVFormer” 的模型,它的主要组成部分和参数如下:
基础配置:
_base_中包含了用于数据集、优化器和学习率策略的配置文件路径。
数据集参数:
dataset_params包含了数据集相关的参数,如数据版本、标签映射、数据空间的范围等。
模型类型:
TPVFormer是所使用的模型类型。
TPV Aggregator:
tpv_aggregator部分定义了一个名为 “TPVAggregator” 的模块,用于聚合TPV(Top-View Pillar)特征。- 这个模块包括了输入和输出维度、TPV空间的尺寸、类别数等参数。
图像骨干网络:
img_backbone定义了一个ResNet类型的图像骨干网络,用于从输入图像中提取特征。- 这个网络的参数包括网络深度、输出特征层级、冻结的阶段、Batch Normalization等。
图像颈部(FPN):
img_neck定义了一个FPN类型的颈部网络,用于生成不同层级的特征金字塔。- 这个网络将图像骨干网络的输出特征进行特征金字塔处理。
TPV Head:
tpv_head定义了模型的头部,用于处理TPV特征。- 这个部分包括了TPV空间的参数、特征维度、位置编码等。
- 它还包含了一个编码器,用于处理TPV特征。编码器中包括了多层的TPVFormerLayer,每一层包括了自注意力、跨视图注意力等组件。
这里我们主要看一下使用的TPVFormer模型的代码以及为 TPVAggregator的模块,用于聚合TPV(Top-View Pillar)特征
下面是对 TPVFormer 模型的代码的分析:
TPVFormer 继承了
BaseModule,这是一个基础的模型类,它是 mmcv(MMLab Computer Vision)和 mmseg(MMSegmentation)框架中的模型定义类。__init__函数初始化 TPVFormer 模型,接受多个参数:use_grid_mask: 控制是否使用 Grid Mask 数据增强。img_backbone: 图像骨干网络,用于提取图像特征。img_neck: 图像颈部网络,可选的,用于进一步处理图像特征。tpv_head: TPVFormer 头部网络,用于执行语义分割任务。pretrained: 预训练模型的配置。tpv_aggregator: 用于聚合 TPV 特征的头部网络。
在
__init__函数中,根据传入的参数初始化 TPVFormer 模型的各个组件,包括图像骨干网络、图像颈部网络、TPVFormer 头部网络以及 TPV 聚合器。如果提供了预训练模型,则将其配置传递给图像骨干网络。TPVFormer 模型支持使用 Grid Mask 数据增强。Grid Mask 是一种数据增强方法,可以随机遮挡输入图像的一部分,从而增加模型的鲁棒性。
extract_img_feat函数用于提取图像特征,接受图像数据img作为输入。在函数内部,它首先对输入的图像进行形状变换,然后应用 Grid Mask 数据增强(如果启用),接着通过图像骨干网络提取图像特征,最后通过图像颈部网络进行进一步处理。forward函数是 TPVFormer 模型的前向传播函数。它接受图像数据img和其他输入参数,调用extract_img_feat函数提取图像特征,然后将这些特征传递给 TPVFormer 头部网络tpv_head执行语义分割任务。最后,模型将输出结果传递给 TPV 聚合器tpv_aggregator进行进一步处理。
总之,TPVFormer 是一个用于图像语义分割任务的模型,它包括图像骨干网络、图像颈部网络以及 TPVFormer 头部网络,可以处理输入的图像数据和点云数据,通过 TPV 聚合器聚合特征,以生成最终的语义分割结果。模型还支持 Grid Mask 数据增强以提高模型的鲁棒性。
下面是对 TPVAggregator 模块的代码的分析:
TPVAggregator 继承了
BaseModule,这是 mmseg(MMSegmentation)框架中的头部模块类。__init__函数初始化 TPVAggregator 模块,接受多个参数:tpv_h,tpv_w,tpv_z: TPV 的高度、宽度和深度。nbr_classes: 类别数,即目标类别的数量。in_dims,hidden_dims,out_dims: 输入、隐藏和输出维度。scale_h,scale_w,scale_z: 高度、宽度和深度的缩放因子。use_checkpoint: 是否使用 PyTorch 的 checkpoint 功能。
TPVAggregator 模块包括一个简单的神经网络,其中包含线性层(Linear)和 Softplus 激活函数用于从输入特征中提取特征,然后通过线性分类层进行目标分类。
forward函数用于执行前向传播操作,接受 TPV 特征列表tpv_list和点云数据points(可选)。在函数内部,首先对 TPV 特征进行形状变换和插值操作,以匹配点云数据的尺寸和位置。然后,如果提供了点云数据,将点云数据映射到 TPV 特征上,执行点云与 TPV 特征的融合。最后,将融合后的特征传递给线性层和分类器进行分类,并返回分类结果。如果未提供点云数据,则仅将 TPV 特征进行插值和融合,并执行分类。最终的分类结果以形状
(batch_size, num_classes, scale_w * tpv_w, scale_h * tpv_h, scale_z * tpv_z)返回。
总之,TPVAggregator 模块用于聚合 TPV 特征和点云数据,以执行语义分割任务。它包含线性层和分类器,用于将输入特征映射到目标类别的概率分布。这个模块的设计旨在结合点云数据和 TPV 特征,以提高语义分割的性能。



