BEVDet在服务器上环境搭建以及运行记录
流程
创建conda虚拟环境:
conda create --name BEVDet python=3.8 -y在虚拟环境里安装torch:
conda install pytorch==1.10.0 torchvision==0.11.0 cudatoolkit=11.3 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/linux-64/安装mmcv-full:
pip install mmcv-full==1.5.3 -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10.0/index.html -i https://pypi.tuna.tsinghua.edu.cn/simple安装mmdet:
pip install mmdet==2.25.1 mmsegmentation==0.25.0 -i https://pypi.tuna.tsinghua.edu.cn/simple安装其他:
pip install pycuda \ lyft_dataset_sdk \ networkx==2.2 \ numba==0.53.0 \ numpy==1.23.5 \ nuscenes-devkit \ yapf==0.40.1\ setuptools==59.5.0\ plyfile \ scikit-image \ tensorboard \ trimesh==2.35.39 -i https://pypi.tuna.tsinghua.edu.cn/simple最后安装整个项目:
pip install -e .多机训练:
CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4
CUDA_VISIBLE_DEVICES=7 PORT=29510 ./tools/dist_train.sh configs/bevdet/bevdet-r50.py 1 报错 TypeError: FormatCode() got an unexpected keyword argument ‘verify’
原因:yapf版本过高
由0.40.2 切换成 0.40.1问题解决
pip install yapf==0.40.1
警告’Creating a tensor from a list of numpy.ndarrays is extremely slow’
总结
(1) 对于不含numpy.ndarrays的list而言,list->tensor明显快于list->numpy.ndarrays->tensor (1.7s<2.5s);
(2) 对于含有numpy.ndarrays的list而言,list->numpy.ndarrays->tensor明显快于list->tensor (18.8s<41.2s).
报错: AttributeError: module ‘distutils’ has no attribute ‘version’.
解决: setuptools版本问题”,版本过高导致的问题;setuptools版本
第一步: pip uninstall setuptools【使用pip,不能使用 conda uninstall setuptools ; 【不能使用conda的命令,原因是,conda在卸载的时候,会自动分析与其相关的库,然后全部删除,如果y的话,整个环境都需要重新配置。
第二步: pip或者conda install setuptools==59.5.0【现在最新的版本已经到了68了,之前的老版本只是部分保留,找不到的版本不行
Ubuntu安装ninja
Ninja是一个比Make更快速的小型构建系统。其github地址为:https://ninja-build.org/
pip3 install ninja
BEVDet系列源码解读
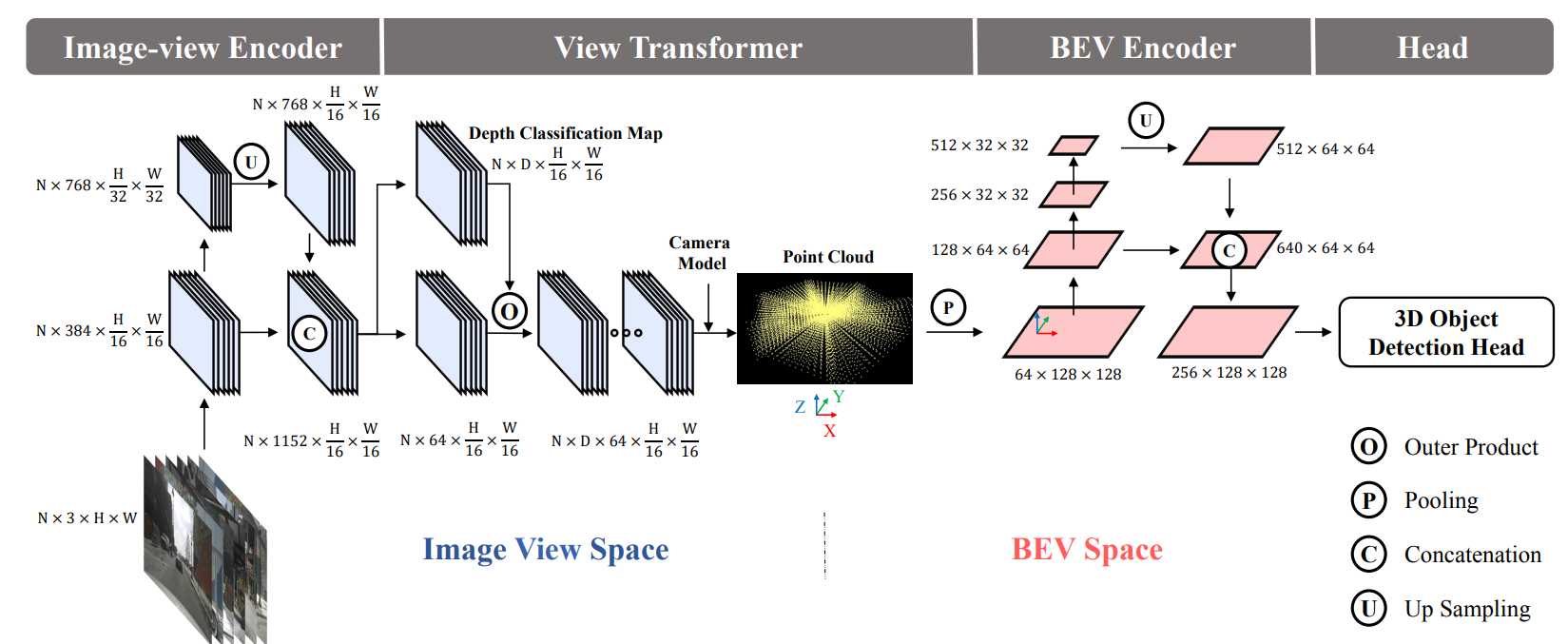
BEVDet方法:关键是其中的第二步View Transformer将图像特征转化为BEV特征的过程并使用cuda实现了高效的voxel_pooling_v2在后处理中也提出了scale-NMS可以针对不同尺度的物体进行缩放然后进行过滤。
nuScenes使用介绍以及BEVDet进行训练
在mini-v1.0训练测试
mini-v1.0里面有三类物体(C.V.、Trailer、Barrier)不包含,其他物体数量也比较少,所以最后的性能上会比较低。
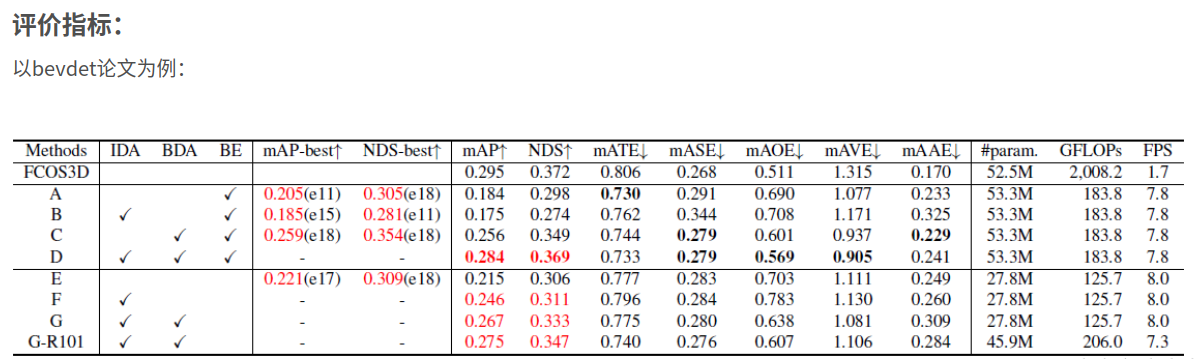
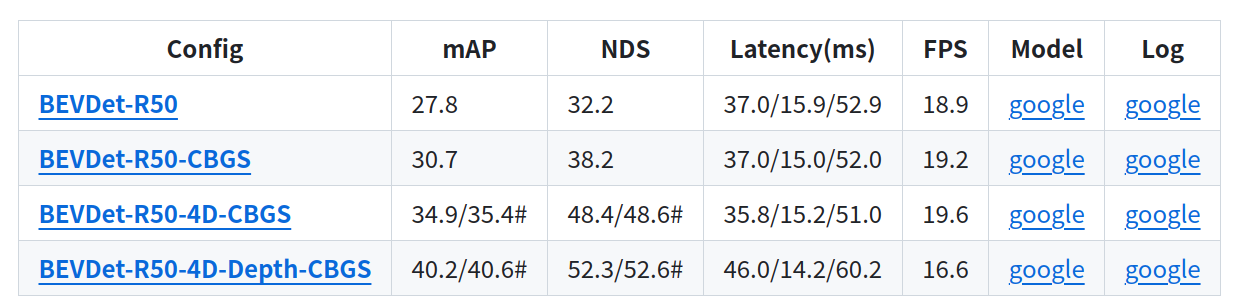
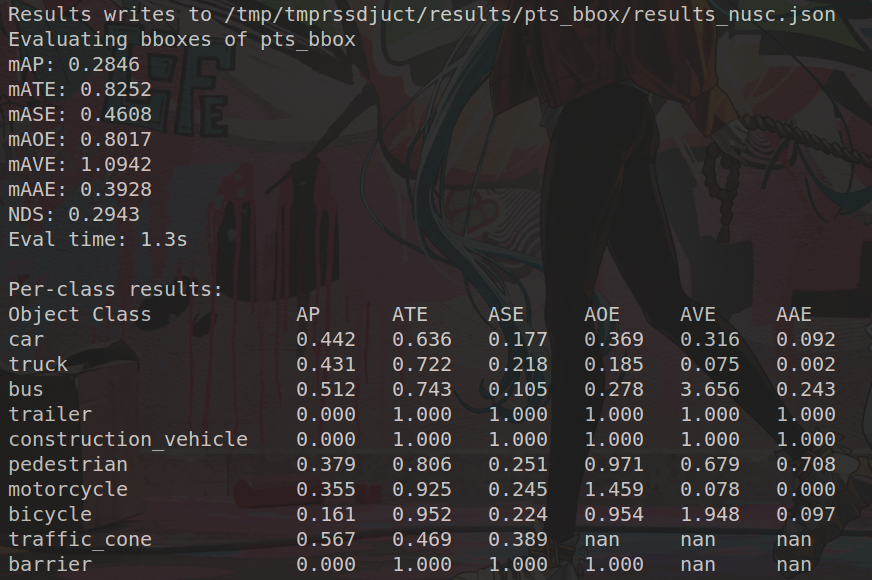
相关检测参数指标
mAP:
在评测时依旧使用目标检测中常用的的AP,不过AP的阈值匹配不使用IoU来计算,而使用在地平面上的2D中心距离d来计算。这样解耦了物体的尺寸和方向对AP计算的影响。d设置为{0.5,1,2,4}米。在计算AP时,去除了低于0.1的recall和precision并用0来代替这些区域。不同类以及不同难度D用来计算mAP:
mATE:
Average Translation Error,平均平移误差(ATE) 是二维欧几里德中心距离(单位为米).
mASE:
Average Scale Error, 平均尺度误差(ASE) 是1 - IoU, 其中IoU 是角度对齐后的三维交并比
mAOE:
Average Orientation Error.平均角度误差(AOE) 是预测值和真实值之间最小的偏航角差。(所有的类别角度偏差都在360∘度内, 除了障碍物这个类别的角度偏差在180∘ 内)
mAVE:
Average Velocity Error.平均速度误差(AVE) 是二维速度差的L2 范数(m/s)。
mAAE:
Average Attribute Error,平均属性错误(AAE) 被定义为1−acc, 其中acc 为类别分类准确度。

可以看出每个参数的性能指标
BEVDet中nuscenes数据集处理
处理前的结构
mmdetection3d
├── mmdet3d
├── tools
├── configs
├── data
│ ├── nuscenes
│ │ ├── maps
│ │ ├── samples
│ │ ├── sweeps
│ │ ├── v1.0-test
| | ├── v1.0-trainval处理使用命令
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes处理后的结构
mmdetection3d
├── mmdet3d
├── tools
├── configs
├── data
│ ├── nuscenes
│ │ ├── maps
│ │ ├── samples
│ │ ├── sweeps
│ │ ├── v1.0-test
| | ├── v1.0-trainval
│ │ ├── nuscenes_database
│ │ ├── nuscenes_infos_train.pkl
│ │ ├── nuscenes_infos_val.pkl
│ │ ├── nuscenes_infos_test.pkl
│ │ ├── nuscenes_dbinfos_train.pkl
│ │ ├── nuscenes_infos_train_mono3d.coco.json
│ │ ├── nuscenes_infos_val_mono3d.coco.json
│ │ ├── nuscenes_infos_test_mono3d.coco.json




