BEV感知总结
参考论文和好用的工具箱:
Delving into the Devils of Bird’s-eye-view Perception: A Review, Evaluation and Recipe(深入研究鸟瞰感知的魔咒:综述、评估和秘诀)
BEV 感知论文和工具箱
(2021) Tesla AI Day. Online
自动驾驶中的BEV感知与建图小记
CaDDN论文+源码解读
GitNet: 基于几何先验的转换用于BEV分割
Monocular 3D Object Detection with Depth from Motion (DfM)
理解DD3D目标检测
CenterPoint:Center-based 3D Object Detection and Tracking (Based: KITTI)
SPVCNN:使用稀疏点体素卷积搜索高效 3D 架构
Multi-Level Fusion (CVPR 2018):解耦单目3D任务的早期尝试
UVTR:Unifying Voxel-based Representation with Transformer for 3D Object Detection
PointPainting: Sequential Fusion for 3D Object Detection(3D物体检测的顺序融合)
PointAugmenting: Cross-Modal Augmentation for 3D Object Detection总结
MVFuseNet : Improving End-to-End Object Detection and Motion Forecasting through Multi-View Fusion of LiDAR Data
学习笔记之BEV模型学习小结
自动驾驶中的BEV感知与建图小记
在感知任务的鸟瞰(BEV)中学习强大的表征是一种趋势,并引起了工业界和学术界的广泛关注。大多数自动驾驶算法的常规方法在前视或透视角中执行检测、分割、跟踪等。随着传感器配置变得越来越复杂,集成来自不同传感器的多源信息并在统一的视角中表示特征变得至关重要。BEV感知继承了几个优点,因为在BEV中表示周围场景是直观和融合友好的;并且在BEV中表示目标最适合于后续模块,如在规划和/或控制中。
BEV感知的核心问题在于:
- (A)如何通过从透视角到BEV的视角转换来重建丢失的3D信息;
- (B)如何在BEV网格中获取注释的真值 ;
- (C)如何融合来自不同传感器和视角下的特征;
- (D)如何在不同场景下适应和泛化算法。
接下来回顾了关于Bev感知的最新工作,并对不同的解决方案进行了深入的分析。此外,还描述了业内几种BEV方法的系统设计。此外,还介绍了一整套实用指南,以提高Bev感知任务的性能,包括Camera、LiDAR和融合输入。最后,指出了该领域未来的研究方向。
引言
与2D视域中被广泛研究的前视角或透视角相比,Bev表示具有几个固有的优点。
- 首先,它没有2D任务中常见的遮挡或缩放问题,识别有遮挡或交叉交通的车辆可以更好地解决。
- 此外,以BEV的形式表示目标或道路元素将有利于后续模块(例如规划、控制)的开发和部署。
概述
根据输入的数据,将Bev感知研究主要分为三个部分–BevCamera、Bev LiDAR和Bev融合。图1描绘了Bev感知的总体情况。具体而言,
- Bev Camera指的是从周围多个Camera中检测或分割3D目标的纯视觉或以视觉为中心的算法;
- Bev LiDAR描述了从点云输入进行检测或分割的任务;
- Bev Fusion描述了来自Camera、LiDAR、GNSS、里程计、HD-Map、CAN-Bus等多个传感器输入的融合机制。
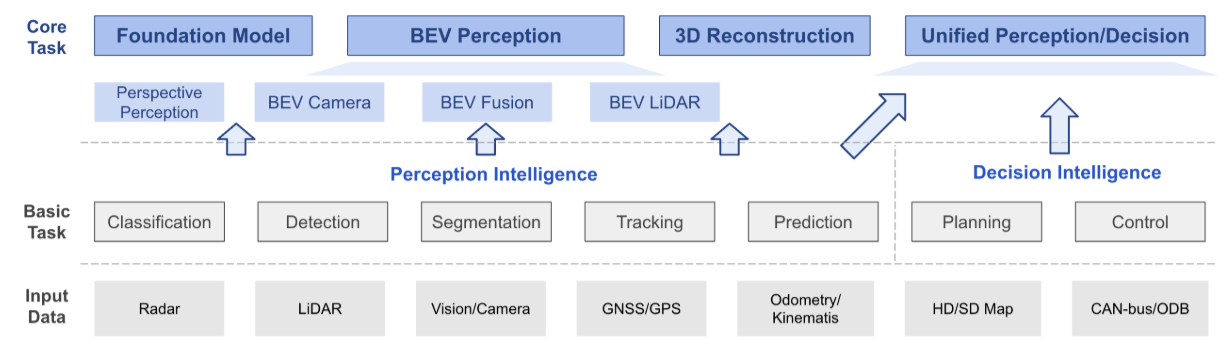
如图1所示,对基本感知算法(分类、检测、分割、跟踪等)进行分组和分类。将自动驾驶任务分为三个层次,其中Bev感知的概念位于中间。基于传感器输入层、基础任务和产品场景的不同组合,某一种BEV感知算法可以相应地指示。
- 例如,M2BEV和BEVFormer属于来自多个Camera的BEVCamera轨迹,以执行包括3D目标检测和BEV地图分割在内的多个任务。
- BEVFusion在Bev空间设计了一种融合策略,可以同时从Camera和LiDAR输入执行3D检测和跟踪。
- 特斯拉发布了其系统pipeline,用于在L2高速公路导航和智能召唤中检测矢量空间(BEV)中的目标和车道线。
BEV感知的动机研究
意义重大
众所周知,仅摄像解决方案和LiDAR解决方案之间存在巨大的性能差距。例如,截至2022年8月提交,一流的纯Camera和LiDAR方法在nuScenes数据集上的差距超过20%,在Waymo基准上的差距超过30%。这自然促使调查只有Camera的解决方案是否可以超越或与LiDAR方法平起平坐。
- 从学术角度来看,设计基于Camera的pipeline以使其优于LiDAR的本质是更好地理解从2D外观输入到3D几何图形输出的视角转换过程。如何将Camera特征转换为几何表示,就像在点云中所做的那样,给学术界留下了一个有意义的影响。
- 在工业方面,将一套LiDAR设备安装到SDV(Software Defined Vehicles,软件定义汽车)中的成本很高;OEM(原始设备制造商,如福特、宝马等)更喜欢廉价且准确的软件算法部署。将仅有Camera的算法改进到LiDAR自然就属于这个目标,因为Camera的成本通常是LiDAR的十分之一。
- 此外,基于摄像头的pipeline可以识别远距离目标和基于颜色的道路元素(例如红绿灯),而这两者都是LiDAR方法所不能做到的。
- 基于Lidar的方法,BEV是最好的方案之一;不过最近的研究也表示,对于对Camera的输入,BEV仍有很大的进步空间。无论是Camera还是Lidar的数据都能够很好的映射到BEV空间,而且也能够更好的以一种统一的方式进行数据融合。
空间(努力方向)
- 一个问题,Bev感知背后的主旨是从Camera和LiDAR输入中学习稳健和可泛化的特征表示。这在LiDAR分支中很容易,因为输入(点云)具有这样的3D属性。在Camera分支中,从单目或多视设置中学习3D空间信息是困难的。看到有一些尝试通过姿势估计[EPro-PnP]或时间运动[Dfm]来学习更好的2D-3D对应,但Bev感知背后的核心问题需要对原始传感器输入的==深度估计进行实质性的创新==。
- 另一个关键问题是如何在pipeline的早期或中期进行特征融合。大多数传感器融合算法将该问题视为简单的目标级融合或沿着通道的朴素特征拼接。如何==从多通道输入中对齐和集成特征==起着至关重要的作用,从而留下了广泛的创新空间。
准备工作
由于Bev感知同时需要Camera和LiDAR,因此高质量的注释以及2D和3D目标之间的准确对齐是此类基准的两个关键评估。
- 虽然Kitti[11]是全面的,在早期的自动驾驶研究中吸引了很多关注,但大规模和多样化的基准测试,如**Waymo[8]、nuScenes[7]、ArgoVerse[12]**,为验证Bev感知想法提供了坚实的平台。这些新提出的基准通常具有高质量的标签;场景多样性和数据量也在很大程度上扩大了。
- 至于算法方面,近年来见证了普通视觉的巨大发展,其中**Transformer[14]、VIT[15,16]、Masked Auto-encoders(MAE)[17]和CLIP[18]**等方法比传统方法获得了令人印象深刻的收益。相信,这些工作将有益于并激励BEV感知研究的伟大。
基于以上三个方面的讨论,得出结论:BEV感知研究具有巨大的潜在影响,值得学术界和产业界长期大力关注。
3D感知中的背景
接下来将回顾执行感知任务的传统方法,包括基于单目Camera的3D目标检测、基于LiDAR的3D目标检测和分割以及传感器融合策略。还介绍了3D感知中的主要数据集,如Kitti数据集[11]、nuScenes数据集[7]和Waymo Open数据集[8]。
任务定义及相关工作
基于单目Camera的3D目标检测。
- 基于单目Camera的方法将RGB图像作为输入,并尝试预测每个目标的3D位置和类别。
- 单目3D检测的主 要挑战是RGB图像缺乏深度信息,因此这类方法需要对深度进行预测。由于从单幅图像估计深度是一个不适定的问题,通常基于单目Camera的方法的性能低于基于LiDAR的方法。
激光雷达检测与分割。
- 激光雷达使用3D空间中的一组点来描述周围环境,
- 这些点捕获了目标的几何信息。尽管缺乏颜色和纹理信息,感知范围有限,但由于深度先验,基于LiDAR的方法比基于Camera的方法有很大的优势。
传感器融合。
- 现代自动驾驶汽车配备了不同的传感器,如摄像头、激光雷达和雷达。每种传感器都有优缺点。Camera数据包含密集的颜色和纹理信息,但无法捕获深度信息。激光雷达提供了准确的深度和结构信息,但存在范围有限和稀疏性的问题。雷达比LiDAR更稀疏,但感知范围更长,可以捕获运动物体的信息。
- 理想情况下,传感器融合将推动感知系统的性能上限,然而如何融合来自不同模式的数据仍然是一个具有挑战性的问题。
数据集和指标
接下来介绍一些流行的自动驾驶数据集和常用的评估指标。表1总结了现行BEV感知基准的主要统计数据。通常,一个数据集由各种场景组成,每个场景在不同的数据集中具有不同的长度。总持续时间从几十分钟到数百小时不等。
对于Bev感知任务,3D包围框标注和3D分割标注是必不可少的,高清地图配置已成为主流趋势。它们中的大多数都可以在不同的任务中采用。达成共识,即需要具有多个模态和各种注释的传感器。发布更多类型的数据[7、12、24、25、33、39],如IMU/GPS和CAN-BUS。与Kaggle和EvalAI排行榜类似,公布了每个数据集的提交总数,以表明某个数据集的受欢迎程度。
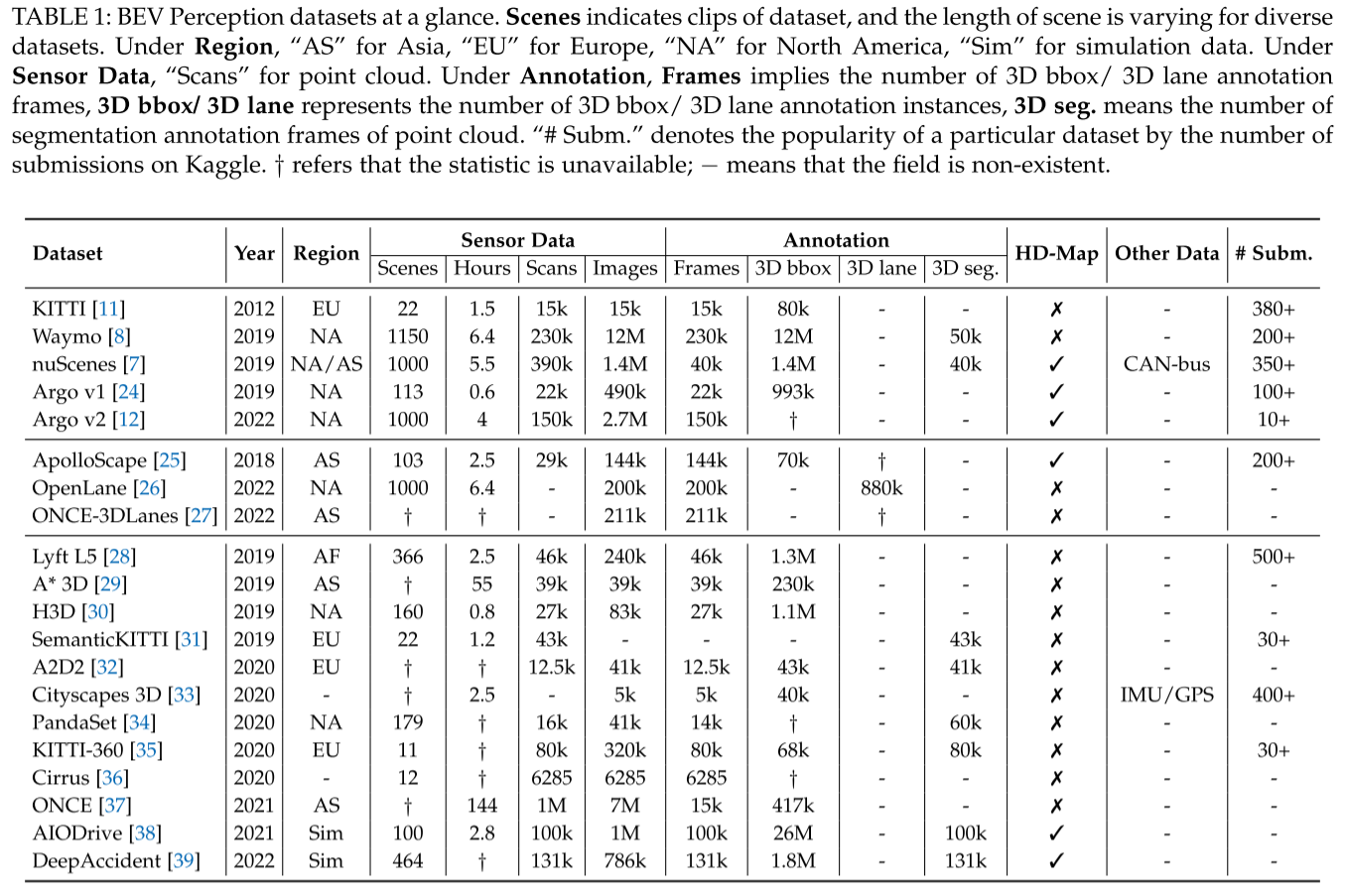
数据集
Kitti数据集。
- KITTI是2012年提出的一个开创性的自动驾驶数据集。它拥有7481张训练图像和7518张测试图像,用于3D目标检测任务。它也有从Velodyne激光扫描仪捕捉到的相应的点云。测试集分为3个部分:简单、中等和困难,主要根据边界框大小和遮挡级别。目标检测评价分为两类:三维目标检测评价和鸟瞰评价。Kitti是第一个针对多个自动驾驶任务的全面数据集,它吸引了社区的大量关注。
Waymo数据集。
- Waymo Open DataSet v1.3分别在训练、验证和测试集中包含798、202和80个视频序列。每个序列有5个LiDAR和5个左、左、前、右、右、侧5个视角,图像分辨率为1920×1280像素或1920×886像素。Waymo规模庞大,形式多样。它随着数据集版本的不断更新而不断发展。每年,Waymo公开赛都会定义新的任务,并鼓励社区努力解决这些问题。
NuScenes数据集。
- NuScenes数据集是一个包含两个城市1000个驾驶场景的大规模自动驾驶数据集。850个场景用于培训/验证,150个场景用于测试。每一场戏都有20多秒长。它有40K个关键帧和整个传感器套件,包括6个摄像头,1个激光雷达和5个雷达。摄像机图像分辨率为1600×900。同时,发布了相应的HD-Map和CanBus数据,以探索多个输入的辅助。由于NuScenes提供了多样化的多传感器设置,因此它在学术文献中越来越受欢迎;数据规模没有Waymo的大,这使得在这个基准上快速验证想法变得高效。
评估指标
Let-3D-APL
- 在仅有摄像头的3D检测中,使用LET-3D-APL(Longitudinal Error Tolerant 3D Average Precision with Longitudinal Affinity Weight,具有纵向亲和权重的纵向误差容错 3D 平均精度)代替3D-AP作为度量。与基于并集的3D交集(IOU)相比,LET-3D-APL允许预测包围框在给定容差范围内的纵向定位误差。LET-3D-APL通过使用定位亲和力来衡量精度来惩罚纵向定位误差。LET-3D-APL的定义在数学上定义为:
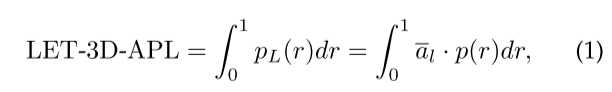
其中,PL(R)表示纵向亲和度加权精确值,p(r)表示调用r时的精确值,乘数al是被视为Tp(真正)的所有匹配预测的平均纵向亲和度。mAP
- 在二维目标检测中,平均平均精度(MAP)类似于著名的AP度量,但匹配策略被从IOU替换为BEV平面上的2D中心距离。AP在不同的距离阈值下计算:0.5米、1米、2米和4米。MAP是通过在上述阈值中对AP求平均来计算的。
NDS
- NuScenes检测分数(NDS)是几个度量的组合:MAP、Mate(平均平移误差)、MASE(平均比例误差)、MAOE(平均方向误差)、MAVE(平均速度误差)和MAAE(平均属性误差)。通过使用上述指标的加权和来计算NDS。MAP的权重为5,其余的权重为1。在第一步中,TPerror被转换为TPcore,NDS定义:

BEV感知方法
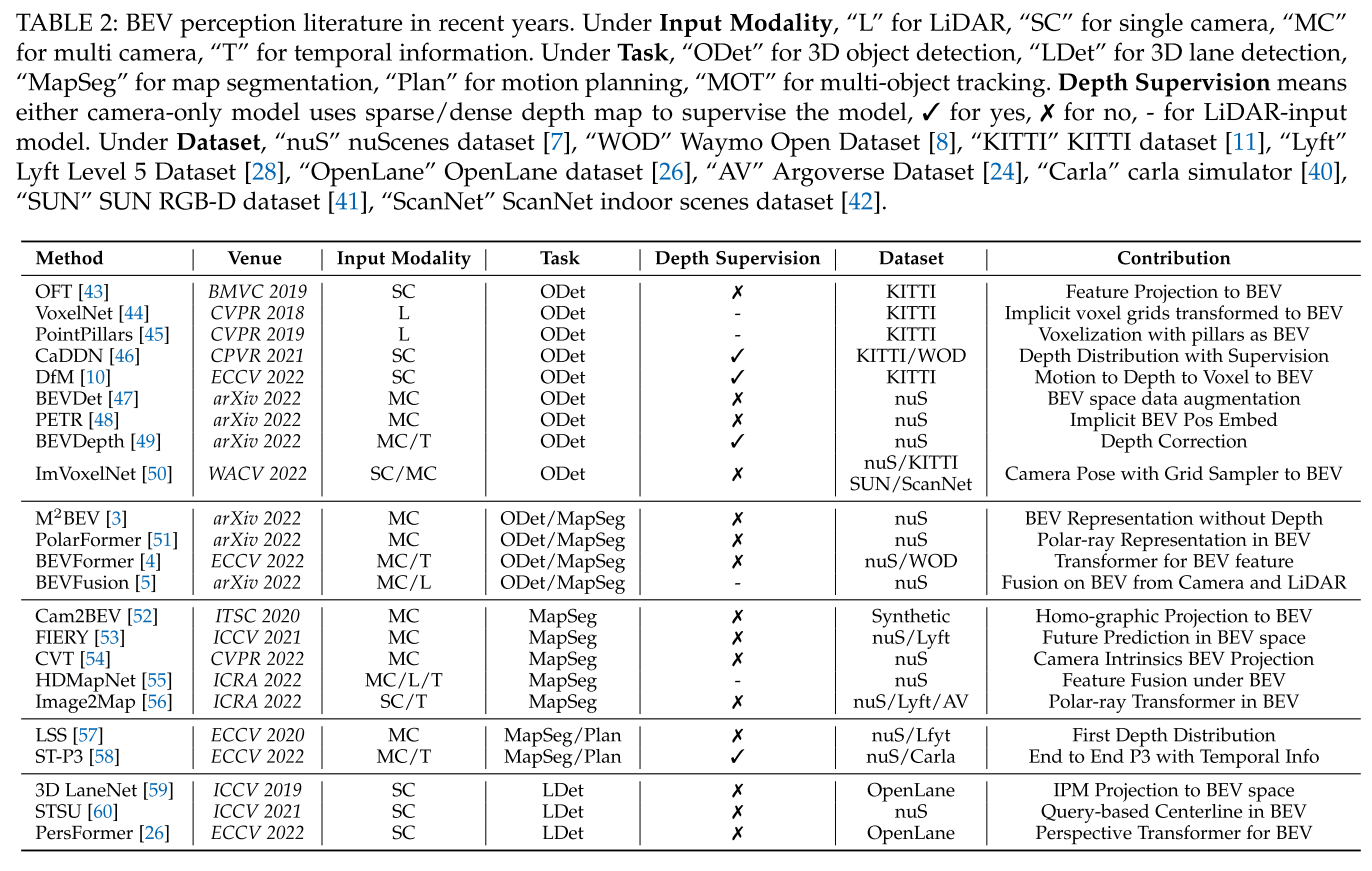
主要从学术界和工业界对BEV认知的不同角度进行了详细的描述。根据输入方式的不同将BEV区分为三种设置,BEV Camera(仅摄像头3D感知)、Bev LiDAR和Bev Fusion,并总结了BEV感知的工业设计。
表2总结了基于输入数据和任务类型的BEV知觉文献分类。表3描述了多年来流行排行榜上3D目标检测和分割的性能收益。
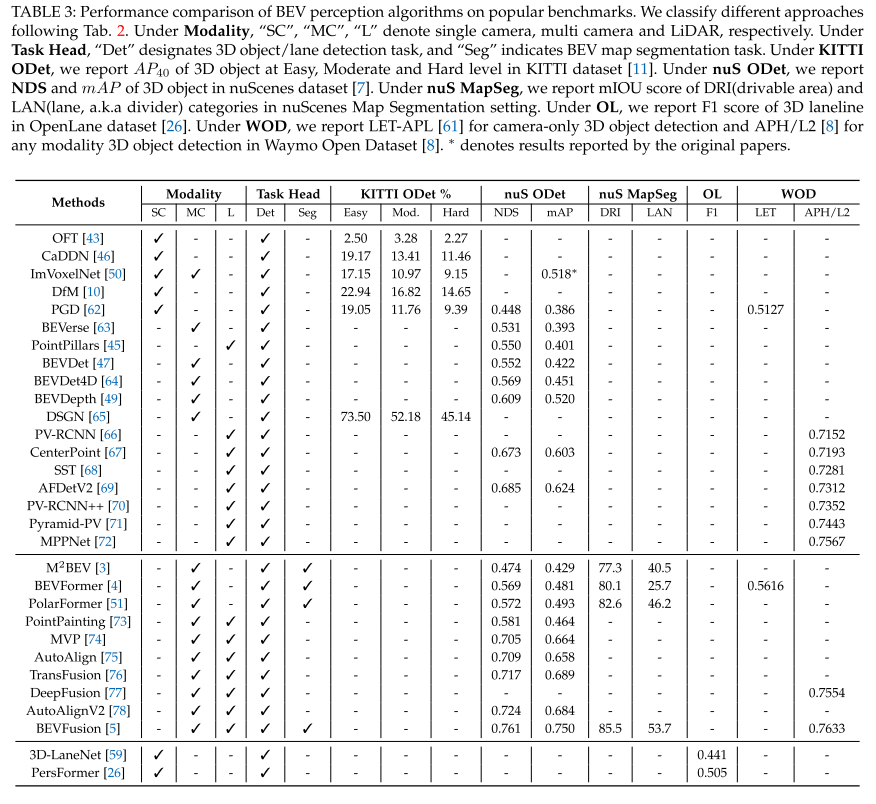
BEV Camera
通用pipeline
如图2所示,一般的只有Camera的3D感知系统可以分为三个部分:2D特征提取模块、视角转换模块(可选)和3D解码器。
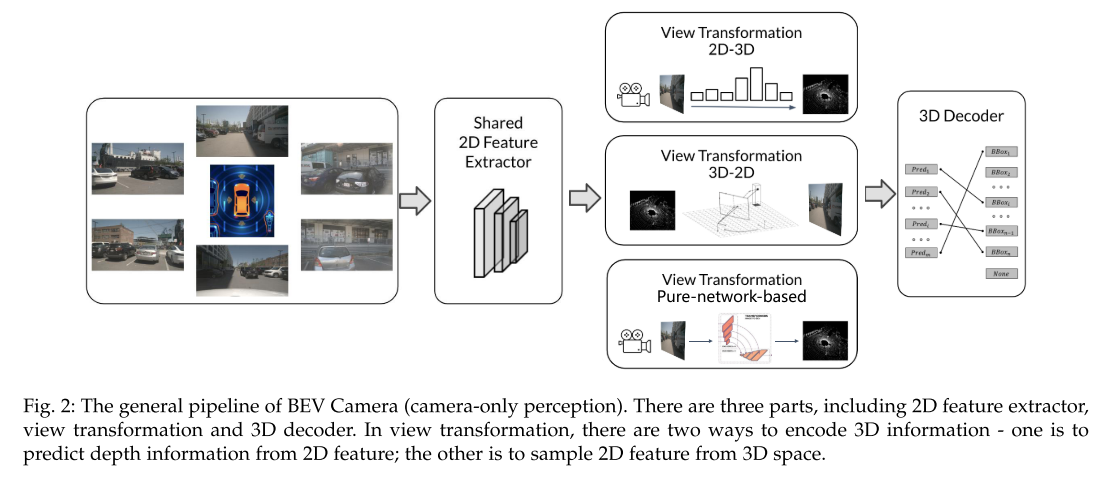
- 特征提取
- 在2D特征提取中,2D感知中存在着大量的经验,可以在3D感知中考虑,以骨干预训练的形式。
- 视角转换模块
- 与2D感知系统有很大的不同。注意,并不是所有的3D感知方法都具有视角转换模块,并且一些方法直接根据2D空间中的特征来检测3D空间中的目标,如FCOS3D这样的单目3D检测其是直接从2D特征中预测3D信息。
- 3D解码器
- 接收2D/3D空间中的要素,并输出3D边界框、Bev地图分割、3D车道关键点等3D感知结果。
- 大多数3D解码器来自基于LiDAR的方法[Voxelnet,SECOND],其在Voxel空间/Bev空间执行检测,但仍有一些Camera3D解码器利用2D空间[FCOS3D,SMOKE,DETR3D]的特征并直接回归3D目标的定位。
View Transformation(视角转换模块)
在仅有Camera的3D感知中,视角转换模块是关键,因为它是构建3D数据和编码3D先验假设。最近的研究[M2BEV,BEVFormer,Mono3D,PersFormer,BEVDet,PETR,BEVDepth,Polarformer,3d-lanenet]集中于增强这一模块。将视角转换技术分为三大主流。
- 第一种方法称为“2D-3D方法”,从2D图像特征开始,通过深度估计将2D特征“提升”到3D空间。
- 第二种是3D-2D方法,它起源于3D空间,通过3D到2D的投影映射将2D特征编码到3D空间。前两个流显式建模几何变换关系。
- 第三种方法被称为“纯网络方法”,它利用神经网络隐式地获取几何变换。图3给出了执行视角转换的概要路线图,下面将对其进行详细分析。
![图3:视角转换的分类。在2D-3D方法中,基于LSS的方法[BEVFusion,CaDDN,BEVDet,BEVDepth,LSS,BEVDet4d,BEVFusion2]根据2D特征预测每个像素的深度分布。在3D-2D方法的基础上,基于单应矩阵的方法[BEVFormer,PersFormer,GitNet]假定稀疏的3D样本点,并通过摄像机参数将其投影到2D平面上。基于纯网络的方法[94,Fishing net,NEAT,97,98]采用MLP或变换来隐式建模从3D空间到2D平面的投影。](/pic/BEV8.png)
2D-3D方法
- 首先由LSS提出,它预测2D特征上的网格深度分布,然后基于深度将2D特征提升到Voxel空间,并执行类似于基于LiDAR的方法的下游任务。这一过程可以表述为:
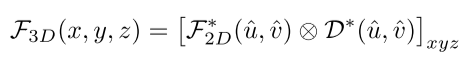
- 伪LiDAR方法[Pseudo-lidar,Pseudo-lidar++]从预先训练的深度估计模型中提取深度信息,并且提升过程发生在2D特征提取之前。
- 在LSS之后,还有另一项工作遵循了与面元分布相同的思想,即CaDDN(Categorical depth distribution network for monocular 3d object detection)。CADDN使用类似的网络来预测分类深度分布,将Voxel空间特征压缩到BEV空间,并在最后执行3D检测。
- LSS和CaDDN的主要区别在于,CaDDN使用深度真值信息来指导其分类深度分布预测,从而具有从2D空间提取3D信息的优越的深度网络。后续工作,例如**BEVDet及其时间版本BEVDet4D、BEVDepth、BEVFusion和其他[Dsgn,DD3D,LIGA-Stereo]**。
3D-2D方法
- 逆透视映射(IPM)有条件地提出了从3D空间到2D空间的投影,假设3D空间中的对应点位于水平面上。这样的变换矩阵可以从Camera的内部和外部参数数学推导出来。一系列的工作是应用IPM将元素从透视角转换为鸟瞰图,无论是前处理还是后处理。在视角转换方面,OFT-Net首次提出了从3D到2D的特征投影方法。OFT-Net形成一个均匀分布的3DVoxel特征网格,通过聚集来自相应投影区域的图像特征来填充Voxel。然后,通过对Voxel特征进行垂直求和来获得正交Bev特征地图。
- 最近,受特斯拉感知系统技术路线图的启发,3D-2D几何投影和神经网络的组合流行起来[BEVFormer,PersFormer,DETR3D,GitNet]。请注意,变压器体系结构中的交叉注意机制在概念上满足了这种几何投影的需要,如以下所示:
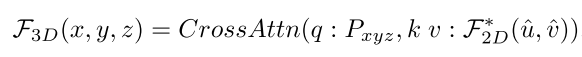
- 其中q、k、v表示查询、键和值,Pxyz是Voxel空间中的预定义锚点,利用Camera参数将Pxyz投影到图像平面,以实现模型的快速收敛。为了获得稳健的检测结果,BEVFormer[4]利用Transformer中的交叉注意机制来增强3D-2D视角转换的建模。其他人Imvoxelnet和MVFCOS3D++减轻了网格取样器的压力,以有效地加速这一过程。尽管如此,这些方法在很大程度上依赖于Camera参数的精确度,这些参数很容易受到长时间驾驶的波动的影响。
基于纯网络的方法
- 无论是2D方法还是3D-2D方法,这两种方法都引入了几何投影中包含的遗传感应偏差。相反,一些方法倾向于利用神经网络来隐式表示Camera投影关系。许多BEV地图分割工作[Hdmapnet,Translating images into maps,CVT]使用多层感知器或Transformer[Attention is all you need]体系结构来隐式地建模3D-2D投影。VPN引入了视角关系模块–多层感知器(MLP),用于通过处理来自所有视角的输入来产生地图-视角特征,从而实现了跨多个视角的共享特征表示的获取。HDMapNet采用MLP架构来执行特征地图的视角转换。BEVSegFormer构建密集的BEV查询,通过MLP从查询特征中直接预测其二维投影点,然后使用可变形注意力更新查询嵌入。CVT将图像特征与基于摄像机内外参数的摄像机感知位置嵌入相结合,并引入了交叉视角注意模块来产生地图视角表示。某些方法不显式构建BEV特征。PETR将源自摄像机参数的3D位置嵌入集成到2D多视角特征中。这一集成使稀疏查询能够通过普通的交叉关注直接与3D位置感知图像功能交互。
关于BEV和透视方法的讨论
在纯相机3D感知的最初阶段,主要关注的是如何从透视图(也称为2D空间)预测3D对象的定位。这是因为2D感知在那个阶段发展得很好[Faster R-CNN,Fast R-CNN,Mask R-CNN,FCOS],如何使2D检测器具有感知3D场景的能力成为主流方法[Probabilistic and geometric depth: Detecting objects in perspective,FCOS3D,SMOCK,Multi-Level Fusion based 3D Object Detection from Monocular Images]。后来,一些研究涉及到Bev表示,因为在这种观点下,很容易解决3D空间中相同大小的目标由于距离Camera的距离而在图像平面上具有非常不同的大小的问题。这一系列工作要么预测深度信息,要么利用3D先验假设来补偿Camera输入中3D信息的损失
虽然最近基于BEV的方法席卷了3D感知界,但值得注意的是,这种成功主要得益于三个方面。
- 第一个原因是流行的nuScenes数据集[7],它具有多摄像机设置,非常适合在BEV下应用多视角特征聚合。
- 第二个原因是,大多数纯Camera的Bev感知方法都从基于LiDAR的方法[Voxelnet,Pointpillars,CenterPoint,SPVCNN,SECOND,PointNet,PointNet++]中获得了很多帮助,表现在检测头的形式和相应的损耗设计上。
- 第三个原因是单目方法[FCOS3D,SMOKE,Multi-level fusion based 3d object detection from monocular images]的长期发展使基于BEV的方法蓬勃发展,这是处理透视视角中特征表示形式的一个很好的起点。核心问题是如何从2D图像中重建丢失的3D信息。为此,基于BEV的方法和透视方法是解决同一问题的两种不同方式,它们并不相互排斥。
BEV LiDAR
通用pipeline
图4描绘了Bev LiDAR感知的一般pipeline。
- 提取的点云特征被转换为BEV特征地图。常见的检测头产生3D预测结果。
- 在特征提取部分,主要有两个分支将点云数据转换为BEV表示。根据pipeline的顺序,将这两个选项分别称为pre-BEV and post-BEV,以表明骨干网络的输入是来自3D表示还是来自BEV表示。
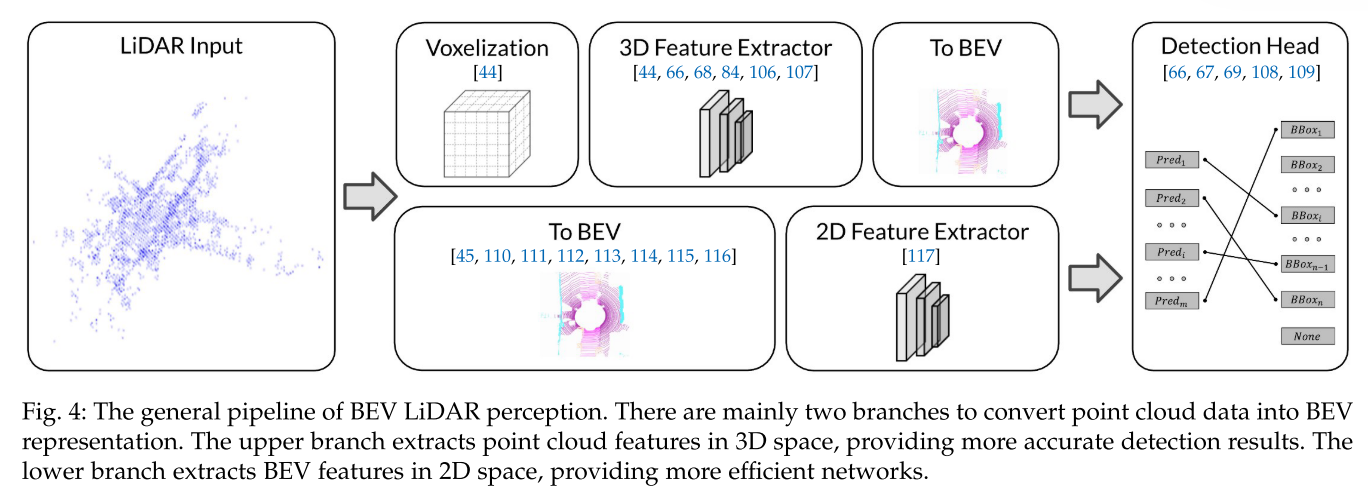
Pre-BEV特征提取
- 除了基于点的方法对原始点云进行处理外,基于Voxel的方法将点Voxel化为离散的网格,通过离散化连续的三维坐标来提供更高效的表示。基于离散Voxel表示,3D卷积或3D稀疏卷积可用于提取点云特征。
- 相关方法。
- VoxelNet堆叠多个Voxel特征编码(VFE)层,以将Voxel中的点云分布编码为Voxel特征。
- SECOND在处理Voxel表示时引入了稀疏卷积,大大降低了训练和推理速度。
- CenterPoint是一款功能强大的基于中心的无锚3D检测器。PV-RCNN结合了点和Voxel分支来学习更具区分性的点云特征。
- PV-RCNN结合了点和Voxel分支来学习更具区分性的点云特征。
- SA-SSD设计了一种辅助网络,将骨干网络中的Voxel特征转换回点级表示,以显式地利用三维点云的结构信息,减少下采样的损失。
- Voxel R-CNN采用三维卷积主干提取点云特征。然后在BEV上应用2D网络来提供object proposals,这些object proposals通过提取的特征进行细化。它获得了与基于点的方法相当的性能。
- Object DGCNN将3D目标检测任务建模为BEV中动态图上的消息传递。在将点云转换为BEV特征地图后,预测查询点迭代地从关键点采集BEV特征。
- Votr引入了局部注意、扩展注意和快速Voxel查询,以实现对大背景信息的多个Voxel的注意机制。
- SST将提取的Voxel特征视为Query,然后在非重叠区域应用稀疏区域注意和区域摆动,以避免对基于Voxel的网络进行下采样。
- AFDetV2通过引入KeyPoint辅助监控和多任务头部,形成了单级无锚点网络。
Post-BEV特征提取
由于3D空间中的Voxel稀疏且不规则,应用3D卷积的效率很低。对于工业应用,可能不支持诸如3D卷积之类的运算符;需要合适且高效的3D检测网络。
- MV3D是第一种将点云数据转换为BEV表示的方法。在将点离散到BEV网格中后,根据网格中的点获得高度、强度和密度特征来表示网格特征。由于Bev网格中的点很多,在此处理过程中,信息的损失是相当大的。
- 其他作品PIXOR、Hdnet、BirdNet、Rt3d、Yolo3d、Complex-YOLO遵循类似的模式,使用Bev网格中的统计数据来表示点云,例如最大高度和平均强度。
- PointPillars首先引入了柱的概念,柱是一种高度不受限制的特殊Voxel。它利用PointNet的简化版本来学习柱子中点的表示。然后,编码后的特征可以由标准2D卷积网络和检测头处理。虽然PointPillars的性能不如其他3D主干,但它及其变体具有很高的效率,因此适合工业应用。
总结讨论
将点云数据转换为任何形式的表示不可避免地会导致信息丢失。
- 在Bev前特征提取中,最先进的方法利用细粒度的Voxel,保留了点云数据中的大部分3D信息,从而有利于3D检测。作为权衡,它需要较高的内存消耗和计算成本。
- 在Bev后特征提取中,将点云数据直接转换为BEV表示,避免了在3D空间中的复杂操作。随着高度维度的压缩,不可避免地会产生巨大的信息损失。最有效的方法是使用统计方法来表示BEV特征图,但其结果较差。基于PointPillars的方法[45]平衡了性能和成本,成为工业应用的流行选择。如何处理性能和效率之间的权衡成为基于LiDAR的应用面临的重大挑战。
BEV Fusion
通用pipeline
逆透视映射(IPM)提出了利用摄像机内部和外部矩阵的几何约束将像素映射到Bev平面上的方法。尽管它由于平地假设而不准确,但它提供了在BEV中统一图像和点云的可能性。Lift-Splat-Shots(LSS)是第一个预测图像特征深度分布的方法,它引入神经网络来学习Camera到激光雷达的不适定变换问题。其他工作[BEVFormer,UVTR]发展了不同的方法来进行视角转换。给定从透视角到BEV的视角转换方法,
图5展示了两种典型的BEV融合算法pipeline设计,适用于学术界和工业界。主要区别在于2D到3D的转换和融合模块。在透视变换pipeline(A)中,不同算法的结果首先被转换到3D空间,然后使用先验规则或手工规则进行融合。BEV感知pipeline(B)首先将PV特征转换为BEV,然后融合特征以获得最终预测,从而保留大多数原始信息并避免手工设计,在转换为BEV表示后,将来自不同传感器的特征映射进行融合。在BEV表示中也可以引入时间和自我运动信息。
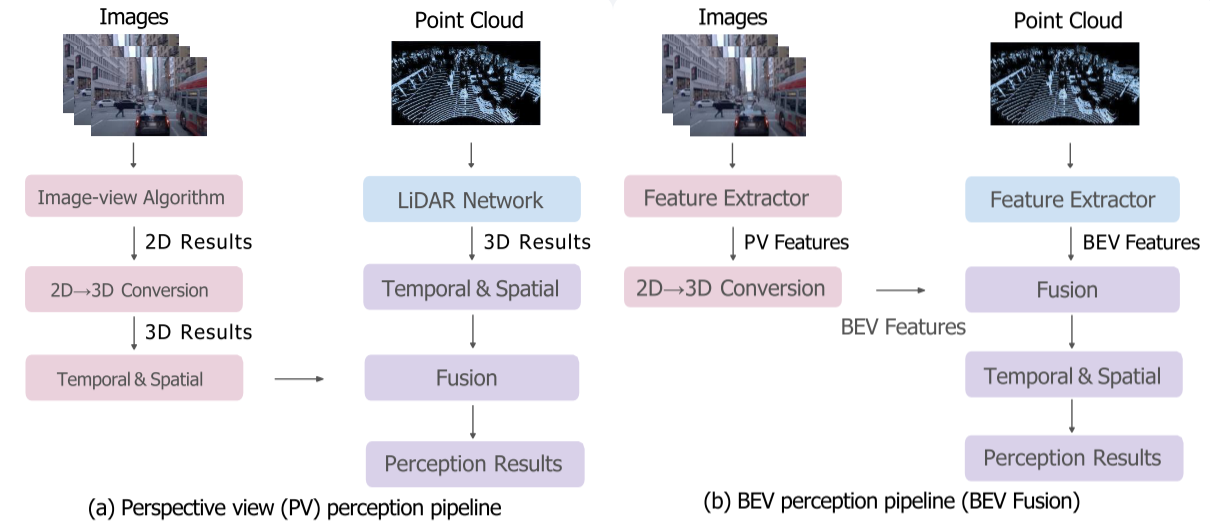
LiDAR-camera Fusion
- 两个同名的BEVFusion[BEVFusion: Multi-task multi-sensor fusion withunified bird’s-eye view representation,BEVFusion: A simple and robust lidar-camera fusion framework]从不同的方向探索了Bev中的融合。由于Camera到激光雷达的投影[PointPainting,PointAugmenting]抛弃了Camera特征的语义密度,前者BEVFusion设计了一种高效的Camera到Bev转换方法,该方法高效地将Camera特征投影到Bev中,然后使用卷积层将其与激光雷达Bev特征融合。后者BEVFusion将BEV融合作为保持感知系统稳定性的鲁棒性主题,它将摄像头和激光雷达功能编码到同一BEV中,以确保摄像头和激光雷达流的独立,这种设计使感知系统能够在传感器故障时保持稳定性。
- 除了BEVFusion之外,UVTR在没有高度压缩的特定于模式的Voxel空间中表示不同的输入模式,以避免语义歧义并实现进一步的交互。通过将每个视角的图像特征变换到为每个图像生成深度分布的预定义空间来构造图像Voxel空间。点Voxel空间是使用常见的3D卷积网络来构造的。然后在两个Voxel空间之间进行跨通道交互,以增强特定于通道的信息。
Temporal Fusion(时域融合)
- 时间信息在推断物体的运动状态和识别遮挡方面起着重要作用。BEV提供了连接不同时间戳中的场景表示的理想桥梁,因为BEV特征地图的中心位置持续到EGO CAR。
- MVFuseNet同时利用Bev和Range视角进行时间特征提取。其他文献FIERY、BEVerse、BEVDet4D使用自运动将先前的BEV特征与当前坐标对齐,然后融合当前BEV特征以获得时间特征。
- BEVDet4D使用空间对齐操作将先前的特征图与当前帧进行融合,然后连接多个特征图。
- BEVFormer和UniFormer采用了一种软方法来融合时间信息。注意力模块用于分别从先前的BEV特征图和先前的帧中融合时间信息。
- 关于自我汽车的运动,注意模块在不同时间戳的表示中的位置也被自我运动信息校正。
总结与讨论
由于图像在透视坐标系中,而点云在三维坐标系中,两种模式之间的空间对齐成为一个至关重要的问题。
- 虽然利用几何投影关系将点云数据投影到图像坐标上很容易,但点云数据的稀疏性使得提取信息丰富的特征变得困难。相反,由于透视角中缺乏深度信息,将透视角中的图像转换到3D空间将是一个不适定的问题。基于先验知识,前人的工作,如IPM和LSS,使得将透视角中的信息转换为BEV成为可能,为多传感器和时间融合提供了统一的表示。
- 在Bev空间融合激光雷达和Camera数据为3D检测任务提供了令人满意的性能。这种方法还保持了不同模式的独立性,这为构建更稳健的感知系统提供了机会。
- 对于时间融合,通过考虑自我运动信息,不同时间戳中的表示可以直接在BEV空间中融合。由于Bev坐标与3D坐标一致,通过监控控制和运动信息可以很容易地获得对自我运动的补偿。考虑到鲁棒性和一致性,BEV是多传感器和时间融合的理想表示。



