弱监督下的BEV检测和占据预测(部分汇总)
Weakly Supervised Class-agnostic Motion Prediction for Autonomous Driving
了解动态环境中的运动行为对于自动驾驶至关重要,这使得激光雷达点云中与类别无关的运动预测受到越来越多的关注。室外场景通常可以分解为运动前景和静态背景,这使得我们能够将运动理解与场景解析联系起来。
基于这一观察结果,我们研究了一种新的弱监督运动预测范式,其中完全或部分(1%,0.1%)注释的前景/背景二值掩模用于监督,而不是使用昂贵的运动注释。为此,我们提出了一种两阶段弱监督方法,
- 其中在第一阶段用不完全二值掩码训练的分割模型将通过提前估计可能的运动前景来促进第二阶段运动预测网络的自监督学习。
- 此外,对于稳健的自监督运动学习,我们通过利用多帧信息并显式地抑制潜在的离群点来设计一致性感知的切角距离损失。
综合实验表明,在完全或部分二值掩码作为监督的情况下,我们的弱监督模型比自监督模型有较大幅度的提高,性能与一些监督模型相当。
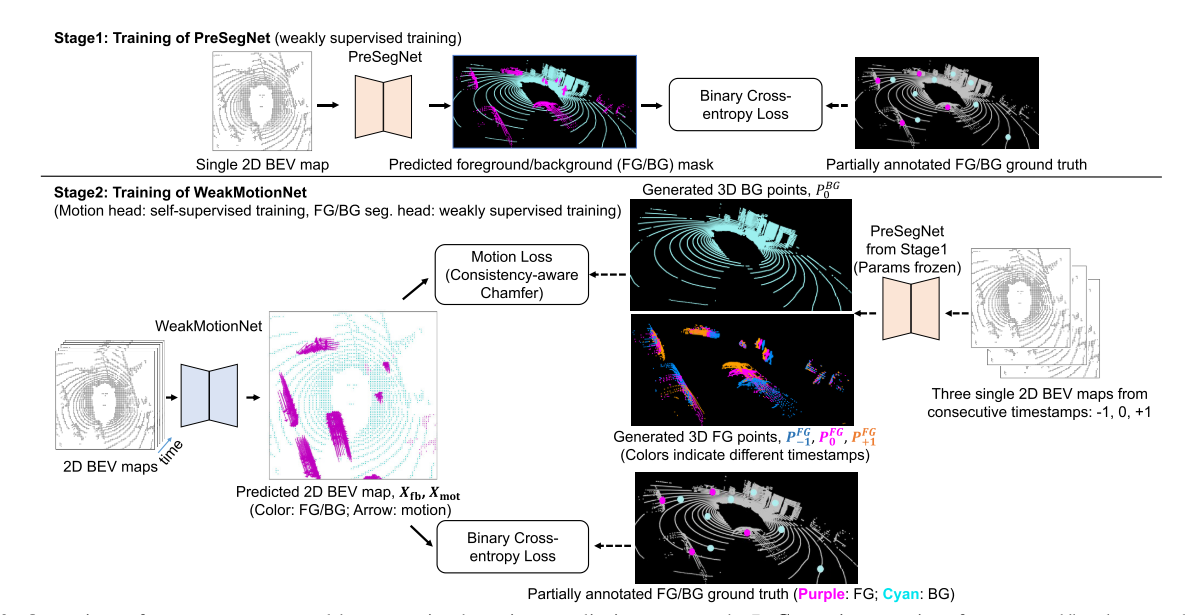
上图是两阶段弱监督运动预测方法概述。在阶段1中,我们使用部分注释的掩码训练前景/背景(FG/BG)分割网络PreSegNet。在阶段2中,我们训练了一个运动预测网络WeakMotionNet,它以一系列同步的Bev图作为输入,预测每个细胞的FG/BG类别Xfb和未来的运动位移Xmot。在没有运动数据的情况下,我们从Stage1训练的PreSegNet生成FG/BG点,并使用一致性感知切角损失来以自监督的方式训练WeakMotionNet的运动预测头部。
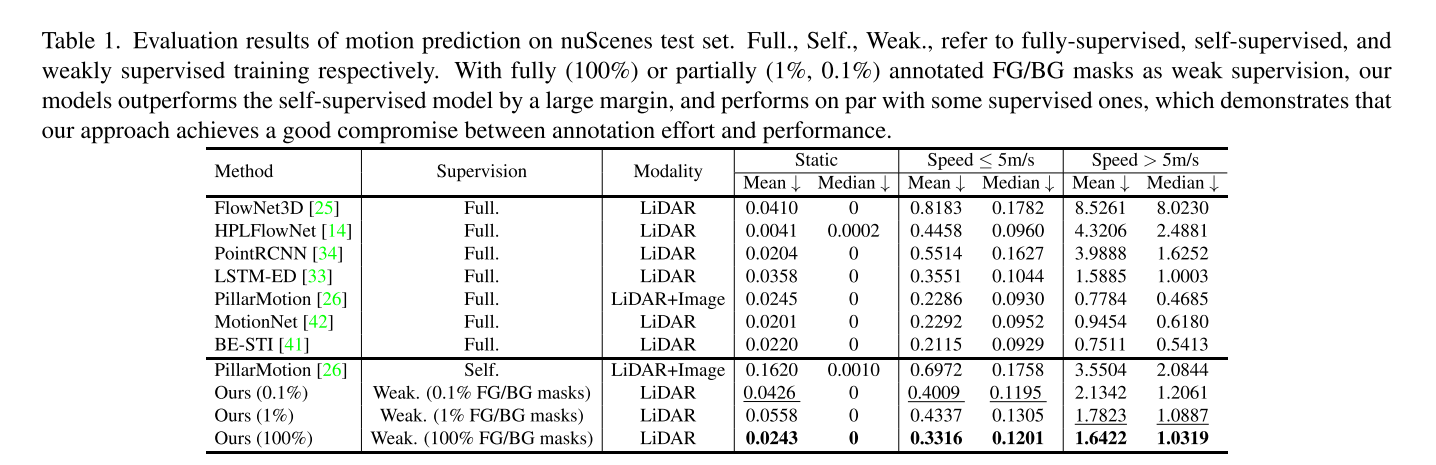
在表1中,我们将我们的弱监督方法与各种基于nuScenes的SOTA运动预测方法进行了比较。PillarMotion是最好的自我监督方法,它利用现成的光流估计网络和额外的2D图像进行训练。在不使用图像或光流的任何知识的情况下,我们的模型通过1%或0.1%的注释FG/BG面具训练,在所有评估指标上都比自我监督的PillarMotion高出约35%。比较我们的弱监督模型和全监督模型,我们观察到我们的模型在慢速和快速组上都比FlowNet3D[25]、HPLFlowNet[14]和PointRCNN[34]表现得更好。特别是,在快速组上,我们的模型比完全监督的场景流模型FlowNet3D和HPLFlowNet分别高出约70%和50%。比较表明,弱监督方法在标注工作量和性能之间取得了很好的折衷,缩小了与完全监督方法的差距。
Weakly Supervised 3D Object Detection from Point Clouds
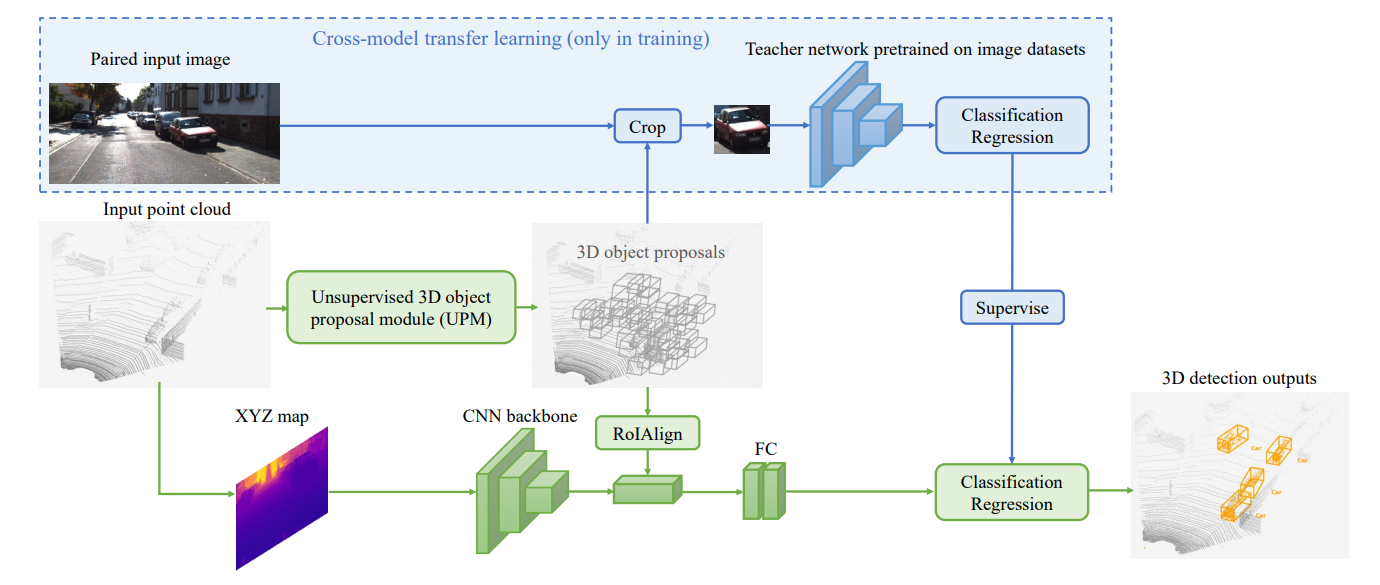
第一个关键组件是无监督的三维对象建议模块(UPM),它基于归一化的点云密度选择三维锚点,生成潜在的3D框
第二个组件是一个跨模态转移学习模块,通过利用在图像数据集上预先训练的教师模型,它将信息,包括对象分类和旋转回归,从图像数据集转移到基于点云的三维物体检测器中,对建议进行分类和改进,以产生最终的预测 (能不能从Kitti到waymo?)
其中激光雷达扫描仪并不需要提供输入点云,而输入点云也可以从单目图像或一对立体图像中获得。假设每一帧的点云在训练集中都有一个成对的图像,但在只需要点云的测试时并不需要这一点
Weakly Supervised 3D Object Detection from Lidar Point Cloud
弱监督的3D点云目标检测,训练数据是少量的弱标签(BEV目标中心点)+少量的kitti-groundtruth,效果能与全监督性能相近,甚至更好。基于此,还做了一个自动标注器。
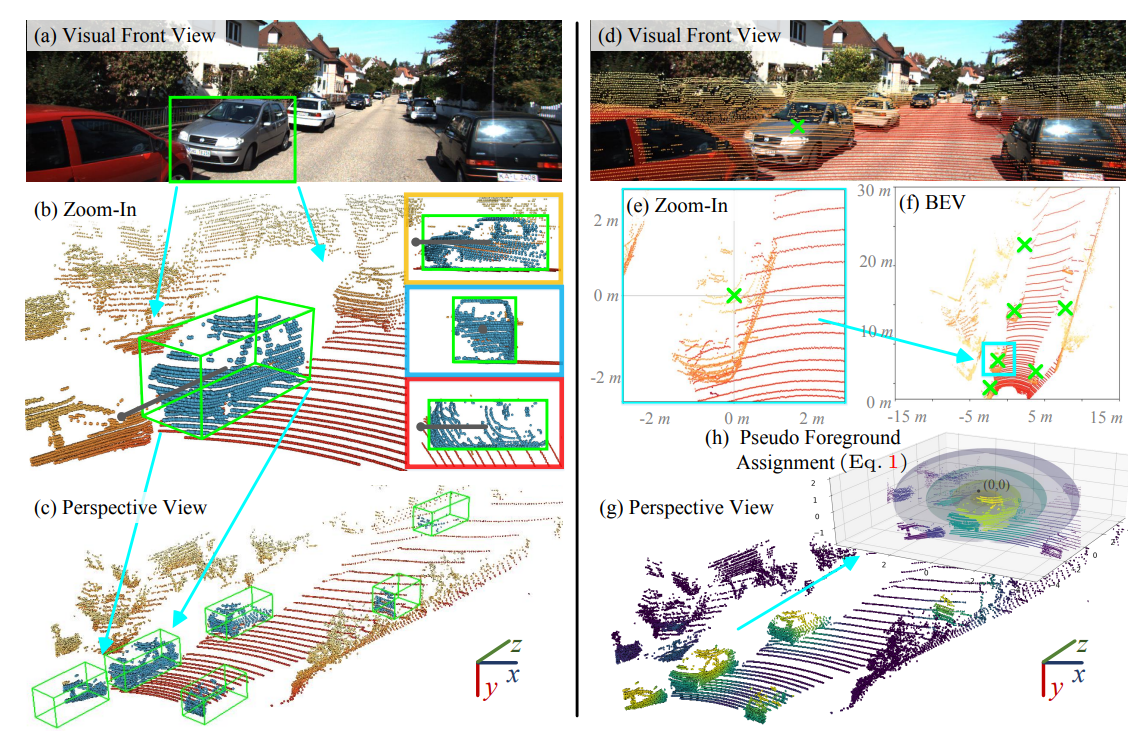
原先的标注过程:标注者首先借助相机图像中的视觉内容在三维场景中查找对象,然后标注一个粗糙的立方体和方向箭头,最后,最佳标注(上图(c))通过逐步调整正交视图中投影的二维框获得。尽管标注的结果质量很高,但是过程耗时又耗力。
作者的弱监督数据只包含带对象中心注释的BEV map,这可以很容易地获得。
具体来说,标注者首先粗略地点击相机前视图上的目标,然后放大BEV map,并显示初始点击周围的区域,以获得更准确的标注点。由于这个注释过程没有引用任何三维视图,所以它非常简单和快速;大多数注释只用通过点击两次按钮即可完成。这个标注包含的信息很弱,没有y轴中的高度和长方体的大小信息。
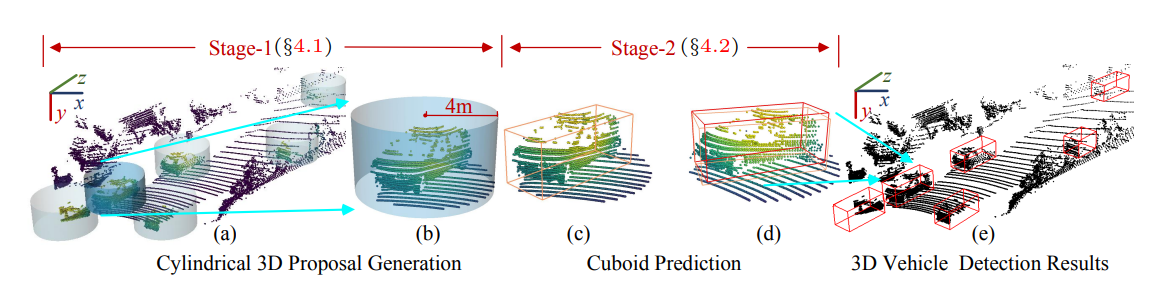
整体结构如图所示。由两个阶段组成。第一阶段由圆柱形三维提案生成结果,第二阶段进行立方体预测。最后产生结果。
FGR: Frustum-Aware Geometric Reasoning for Weakly Supervised 3D Vehicle Detection
WeakM3D: Towards Weakly Supervised Monocular 3D Object Detection
单目 3D 物体检测是 3D 场景理解中最具挑战性的任务之一。由于单目图像的不适定性质,现有的单目 3D 检测方法高度依赖于 LiDAR 点云上手动注释的 3D 框标签的训练。这个注释过程非常费力且昂贵。为了摆脱对 3D 框标签的依赖,在本文中,我们探索了弱监督的单目 3D 检测。具体来说,
- 我们首先检测图像上的 2D 框。
- 然后,我们采用生成的2D框来选择相应的RoI LiDAR点作为弱监督。
- 最终,我们采用网络来预测 3D 框,它可以与相关的 RoI LiDAR 点紧密对齐。
该网络是通过最小化我们新提出的 3D 框估计和相应的 RoI LiDAR 点之间的 3D 对齐损失来学习的。我们将说明上述学习问题的潜在挑战,并通过在我们的方法中引入几种有效的设计来解决这些挑战。



