BEVDet系列
BEVDet系列源码解读
BEVDet网络结构
BEVDet4D 强大而不失优雅的三维目标检测范式
BEVDet4D讲解
BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection
BEVDet4D首次尝试访问时间域中的丰富信息。它只是通过保留先前帧中的中间BEV特征来扩展朴素的BEVDet。然后通过空间对齐操作和拼接操作将保留的特征与当前帧中对应的特征进行融合。除此之外,论文保持了框架的大部分其他细节不变。这样,论文只在推理过程中投入了可以忽略的额外计算预算,同时使范例能够通过查询和比较两个候选特征来访问时间线索。虽然构建BEVDet4D的框架很简单,但构建其健壮的性能并不是一件容易的事情。BEVDet4D的空间对齐操作和学习目标应精心设计,以配合优雅的框架,从而简化速度预测任务,并获得优异的泛化性能。
BEVFormer的速度精度是通过融合多个相邻帧(即总共4帧)的特征来实现的,这类似于大多数基于LiDAR的方法[2,46],其中包含来自多次扫描的点。这与拟议的BEVDet4D有根本的不同,BEVDet4D只使用两个相邻的帧,并在更优雅的图案中实现了更高的速度精度。
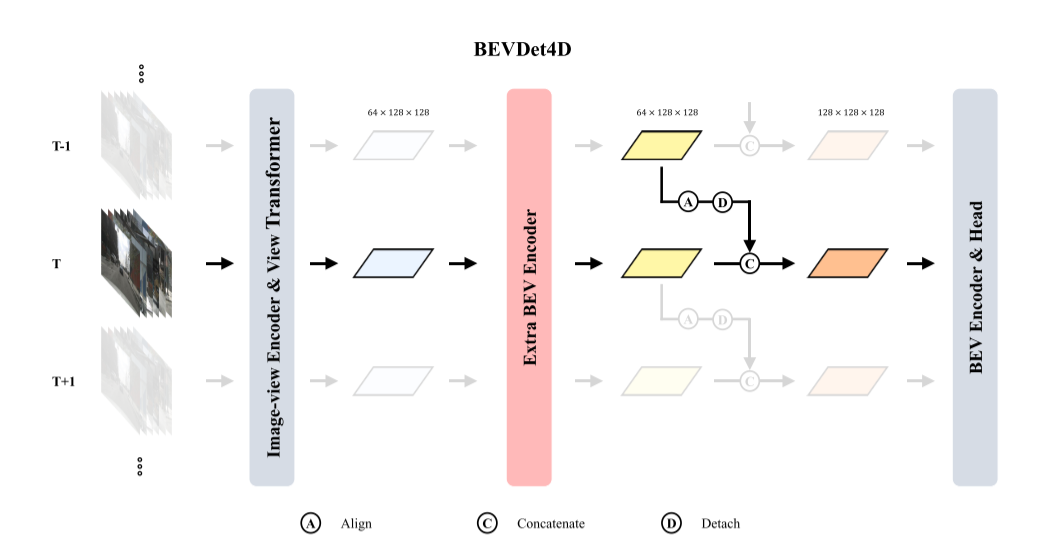
如上图所示,BEVDet4D的总体框架建立在BEVDet基线之上,该基线由四种模块组成:图像-视图编码器、视图转换器、BEV编码器和特定于任务的头部(an image-view encoder, a view transformer, a BEV encoder, and a task-specific head)。
网络架构图
为了利用时间线索,BEVDet4D通过保留由前一帧中的视图转换器生成的==BEV特征==来扩展基线。然后将保留的特征与当前帧中的特征合并。在此之前,将进行对齐操作以简化学习目标。论文应用一个简单的串联操作来合并这些特征,以验证BEVDet4D范例。更复杂的融合策略在本文中没有被开发出来。
此外,视图转换器生成的特征是稀疏的,对于后续模块来说过于粗糙,无法利用时间线索。因此,在时间融合之前,采用==额外的BEV编码器==来调整候选特征。实际上,额外的BEV编码器由两个朴素的残差单元[13]组成,其通道号设置为与输入特征相同。
简化速度学习任务
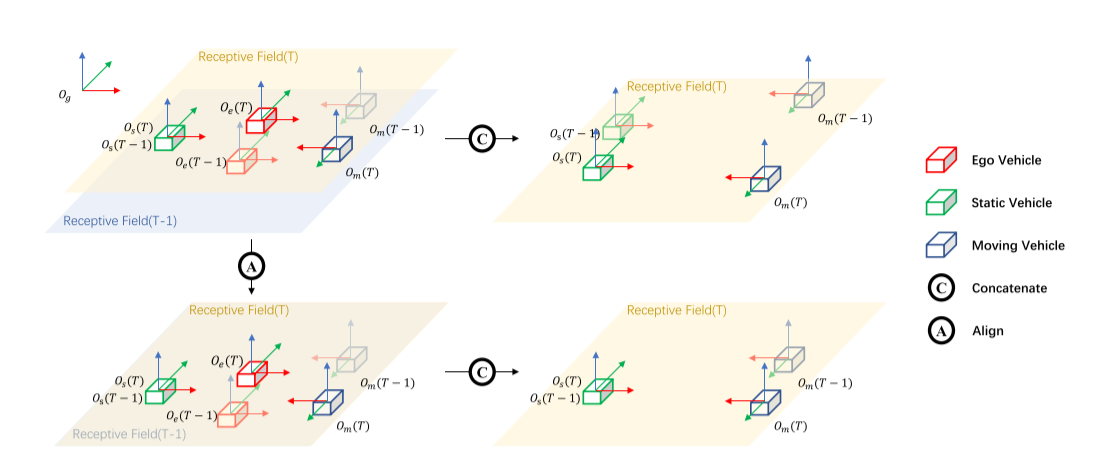
由于有多帧信息,不再直接预测目标速度,而是预测目标在两个连续帧中的位移。即将速度预测简化为移除了时间因素的,通过两个BEV特征间的差异来衡量的位置偏移预测。
此外,BEVDet4D使得位移与ego自身的运动无关进一步简化学习任务(因为ego车辆自身的运动会使目标运动复杂化)。因为ego的运动会使得在global坐标系中static的物体在ego坐标系中变为动态物体。由于BEV特征的感受野是围绕ego对称的,同样,ego运动会使连续两帧对应的BEV特征的global坐标系下的感受野变化。
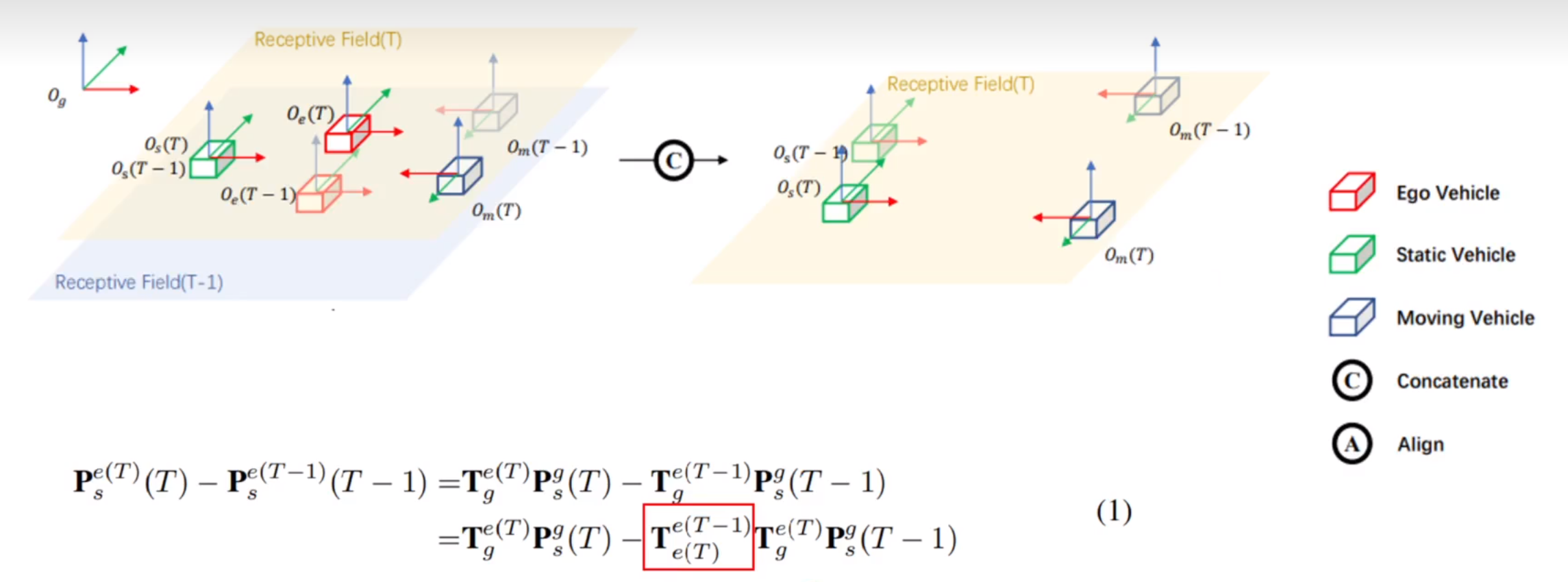
上图可以看到,如果直接concat两帧特征,则最后得到的两个特征的位移和ego运动相关(红色方框),因此需要先将上一帧乘以(红色方框)的逆来消除自车(ego)运动的影响。如下图所示
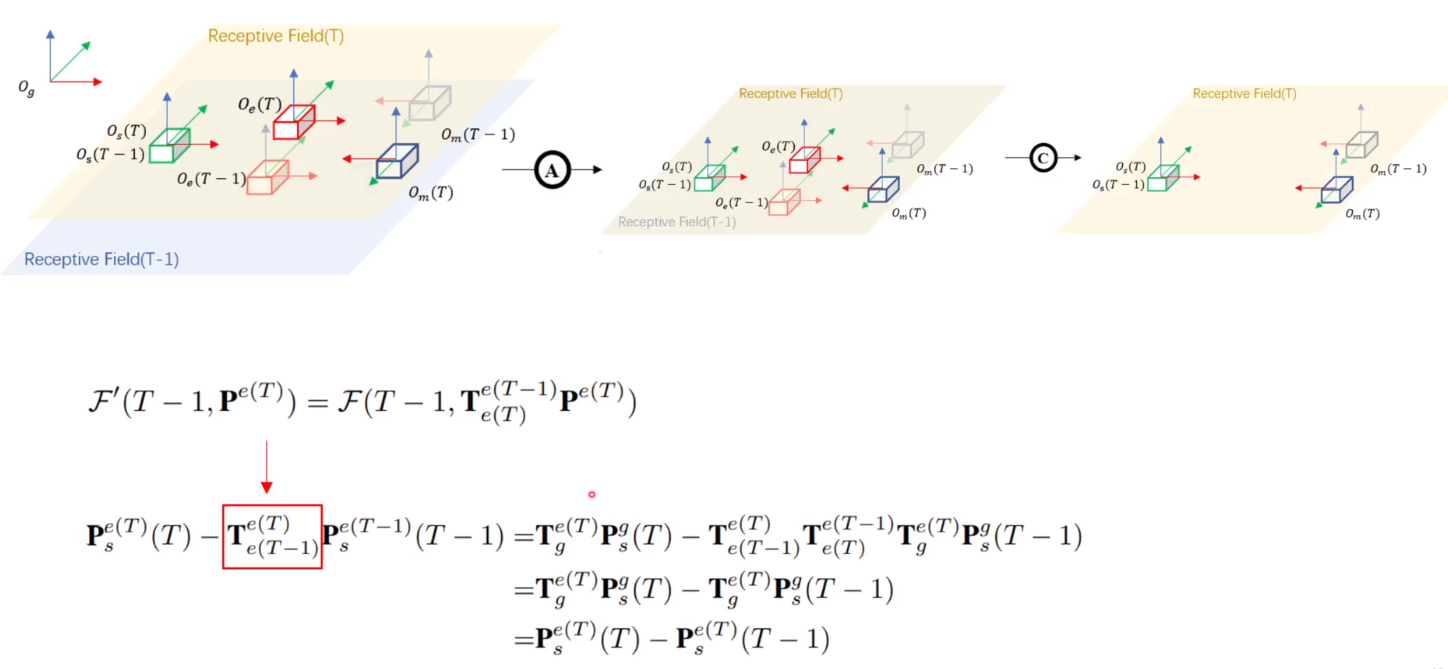
学习目标设为在ego坐标系下当前帧物体的运动,与ego运动无关。
鲁棒性实验

如何建立BEVDet4D的鲁棒性能。即在view-transformer中通过调整伪点云来实现空间对齐操作。结果如上表所示,主要测试了以下几种空间对齐的方案。
- 方案A,即直接将当前帧的特征与先前帧拼接。模型性能大幅降低,尤其是在速度和位移预测方面。推测可能是由于ego运动导致静态和动态目标更复杂导致,因此需要移除ego运动。
- 方案B,只进行平移对齐操作。模型可以利用位置对齐的候选特征来更好的感知静态目标,同时移除了ego运动简化了速度预测。此时,位移误差已经低于baseline,但速度误差仍高于baseline,这可能是由于相邻帧时间间隔不一致导致位移分布与速度分布相差较远。
- 方案C,进一步移除时间因素,让模型直接预测两帧间目标的位移。简化了学习目标,使训练更鲁棒。大幅降低速度预测误差。
- 方案D,在拼接两个候选特征前引入一个额外的BEV编码器。轻微地增加了大约2.8%的计算成本,推理速度基本保持不变,但是使得模型在C上有了更全面的提升。
- 方案E,在D的基础上通过调节速度预测损失的权重,进一步降低了速度误差。
- 方案F,在对齐操作时考虑ego位姿的旋转方差。进一步降低速度误差,表明更精确的对齐操作能够提高速度预测精度。
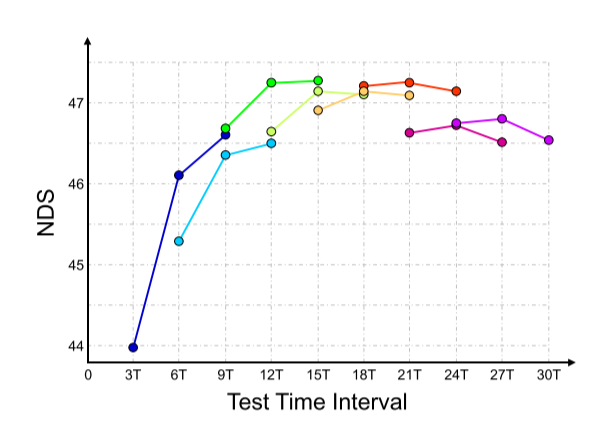
- 方案G,探索当前帧与参考帧之间最优的时间间隔。采用12Hz的数据,两帧时间间隔为T≈0.083s,训练时选择三个不同的时间间隔,并通过在测试比较它们来判断调整方向,这样可以避免超参搜索时的训练干扰。结果见下图,组价间隔为15T,设置为本文默认的测试时间间隔。训练时在[3T,27T]中随机采样来进行数据增强。这种方法进一步降低了速度误差。
代码分析
以下是对BEVDet4D模型代码的详细介绍:
@DETECTORS.register_module()
class BEVDet4D(BEVDet):
...这是一个注册了BEVDet4D类的检测器模块。BEVDet4D继承自BEVDet,表示BEVDet4D是BEVDet的一种变体。
def __init__(self,
pre_process=None,
align_after_view_transfromation=False,
num_adj=1,
with_prev=True,
**kwargs):
super(BEVDet4D, self).__init__(**kwargs)
...初始化方法接受多个参数,包括预处理网络的配置(pre_process),是否在视图变换后对齐BEV特征(align_after_view_transformation),相邻帧的数量(num_adj),以及其他超参数。此外,它调用了父类(BEVDet)的初始化方法。
self.align_after_view_transfromation = align_after_view_transfromation
self.num_frame = num_adj + 1
self.with_prev = with_prev这里设置了BEV特征是否在视图变换后对齐(align_after_view_transformation)、相邻帧的数量(num_adj)以及是否使用前一帧的特征(with_prev)。
@force_fp32()
def shift_feature(self, input, trans, rots, bda, bda_adj=None):
...shift_feature 方法用于将输入的特征进行位移,包括旋转、平移和BEV数据增强。
def prepare_bev_feat(self, img, rot, tran, intrin, post_rot, post_tran,
bda, mlp_input):
...prepare_bev_feat 方法准备BEV特征,包括图像编码、视图变换和预处理。
def extract_img_feat_sequential(self, inputs, feat_prev):
...extract_img_feat_sequential 方法提取顺序图像特征,包括对先前特征进行对齐和使用BEV编码器。
def prepare_inputs(self, inputs):
...prepare_inputs 方法准备输入数据,将输入图像和相关信息分割为每一帧的数据。
def extract_img_feat(self,
img,
img_metas,
pred_prev=False,
sequential=False,
**kwargs):
...extract_img_feat 方法是特征提取的主要入口,根据参数决定是提取顺序特征还是一般特征。
上述是对BEVDet4D模型代码的主要部分的详细介绍,包括初始化、特征提取等


