Efficient LiDAR Point Cloud Oversegmentation Network
摘要
点云过分割是一项具有挑战性的任务,因为它需要产生具有感知意义的点云分区(即超点)。现有的大多数过分割方法都不能有效地从大规模LiDAR点云中生成超点,这是因为过程复杂且效率低下。本文提出了一种简单而高效的端到端LiDAR过分割网络,该网络通过基于低级点嵌入的分组来分割LiDAR点云中的超点。具体地说,
- 我们首先从构建的局部邻域中学习点的相似性,通过局部区分损失来获得低级点嵌入。
- 然后,为了从稀疏的LiDAR点云中生成齐次超点,我们提出了一种同时考虑点嵌入相似性和点在三维空间中的欧几里德距离的LiDAR点分组算法。
- 最后,我们设计了一个超点求精模块,用于准确地将硬边界点分配到相应的超点。
在两个大规模室外数据集SemancKITTI和nuScenes上的广泛结果表明,我们的方法在LiDAR过分割方面取得了新的进展。值得注意的是,我们的方法的推理时间比其他方法快100倍。此外,我们将学习到的超点应用到LiDAR语义分割任务中,结果表明,使用超点可以显著提高基线网络的LiDAR语义分割。
介绍
在现代自动驾驶汽车中,3D LiDAR传感器可以获取周围物体及其表面特征的精确距离测量,以用于大规模户外场景理解。近年来,LiDAR语义分割[21]得到了广泛的研究,出现了各种方法并取得了令人印象深刻的结果。然而,激光雷达过分割在三维计算机视觉中很少被研究。与LiDAR语义分割不同,LiDAR过分割输出有感知意义的点云细分。得到的超点是一组点,这些点在对象的局部区域中在语义和几何上是同质的。超点表示法能够自适应、灵活地表示物体的局部几何结构。因此,研究激光雷达过分割对于基于激光雷达点云的应用是非常有意义的。然而,激光雷达点云的稀疏性、噪声和不规则性给激光雷达过分割带来了巨大的挑战。
早期的点云过分割方法通常是基于优化的方法。
- Lin等人的研究。[17]将超点分割问题归结为子集选择问题,提出了一种利用点云局部信息通过最小化能量函数来分割超点的启发式算法。
- Guinard等人。[8]将点云过分割问题描述为一个结构化优化问题,并使用手工创建的局部描述符通过贪婪的图割算法生成几何简单的超点[14]。然而,由于LiDAR点云稀疏,计算的手工创建的特征的区分性较差,因此生成的超点无法在相似对象之间产生清晰的边界。
- Landrieu等人。[13]引入了一种深度网络来提取点嵌入,用来代替[14]中的手工特征来分割超点。由于它是一个两阶段的方法,超点分割的处理过程复杂且耗时。
- 最近,Huy等人提出了一个新的观点。[11]提出了一种端到端的超点网络,该网络迭代地学习点-超点关联映射以聚类超点。然而,它需要后处理来滤除噪声点。总之,由于程序复杂和效率低下,上述方法不能有效地从大规模LiDAR点云生成超点。
在本文中,我们提出了一种简单而高效的LiDAR过分割网络SuperLiDAR,它直接从LiDAR点云输出超点,而不需要任何额外的处理过程。超点分割的核心思想是基于低级点嵌入对点进行分组。具体地说,为了学习低级点嵌入,
- 我们首先将其描述为一个由点云上定义的局部邻域构造的深度度量学习问题。引入局部判别损失,将3D点嵌入到同一物体的局部邻域内,从而保证了点的嵌入是相似的。
- 在获得低级点嵌入后,我们提出了一种LiDAR点分组算法,该算法通过广度优先搜索(BFS)对点进行分组以生成超点。利用点嵌入的相似性和三维点坐标的欧几里德距离,应用BFS算法生成紧致超点。
- 最后,我们提出了一个超点求精模块,该模块学习硬边界点与其k-最近邻候选超点之间的亲和力。通过将硬边界点与对应的相似度最高的超点进行赋值,可以得到高质量的超点。
值得注意的是,我们的LiDAR过分割网络可以灵活地与下游任务集成,例如语义分割。为了评估学习的超点的有效性,我们引入了一个简单的多尺度超点聚合模型来进行LiDAR语义分割。为了验证该方法的有效性,我们在语义KITTI和nuScenes这两个大规模基准上进行了实验。激光雷达过分割实验表明,该方法不仅达到了最好的性能,而且比其他方法快100倍。此外,LiDAR语义分割实验表明,使用超点可以显著提高基线网络的性能。
本文的主要贡献如下:
- 提出了一种高效的LiDAR过分割网络,用于学习大规模LiDAR点云的超点分割。
- 我们的方法在获得最先进的LiDAR过分割性能的同时,比现有的过分割方法快100倍。
- 我们证明了所提出的LiDAR过分割网络可以端到端的方式集成到LiDAR语义分割网络中,进一步提高了LiDAR语义分割的性能。
相关工作
点云过分割
现有的点云过分割方法大致可以分为两类:基于优化的方法和基于深度学习的方法。
- 基于优化的方法通常使用手工创建的描述符来提取点特征以用于超点分割。
- Papon等人。[21]是3D数据过分割领域的先驱。提出的体素云连通性分割方法利用颜色和深度信息以及三维几何关系将RGB-D数据分割成超点。
- Lin等人的研究。[17]将超点分割问题描述为一个子集选择问题。基于手工生成的点云局部信息,通过直接最小化能量函数来分割超点。
- Guinard等人。[8]将点云过分割问题视为一个结构化优化问题。他们使用贪婪的图割算法[14]来产生几何简单的超点,其中手工制作的局部描述符(如线性度、平面度、散射度和垂直度)被用来描述每个点的局部几何体。然而,当周围环境的点云中存在具有复杂局部几何结构的物体时,手工构造的特征通常不能提供区分特征来生成高质量的超点,特别是在稀疏的LiDAR点云中。
- 基于深度学习的方法利用深度网络来提取区分点特征,以提高过分割性能。
- Guinard等人。[13]将点云过分割作为深度度量学习问题。提出了一种基于图结构的对比度损失来学习辨识点特征。通过使用学习的特征来代替贪婪的图割算法[14]中使用的手工特征,它可以从点云生成比[8]更高质量的超点。然而,由于两阶段超点分割策略,它不能被端到端训练。
- 最近,Huy等人提出了一个新的观点。[11]提出了一种端到端的超点网络,通过迭代学习点-超点关联图来聚类超点。尽管如此,聚集的超点在超点边界附近可能会有很多噪声,特别是在稀疏的LiDAR点云中。因此,需要对图像进行后处理来滤除噪声,增加了应用的复杂性和时间成本。
现有的点云过分割方法受到复杂处理过程的限制,不能灵活地应用于下游任务。因此,有必要设计一种高效的、具有可扩展性和灵活性的点云过分割
激光雷达语义分割
激光雷达语义分割[30,40,9,6,27,34,42,24,26,10]已经出现了基于不同点云表示的各种方法。
- 为了利用传统的2D分割方案,将LiDAR点云投影到图像平面中的基于投影的方法,获得渲染图像[16]、快照[2]、切线图像[28]、距离图像[32,33]和鸟瞰图像[18]。虽然基于投影的方法是激光雷达分割的有效方法,但由于空间压缩,不可避免地会丢失空间几何信息。
- 为了直接利用3D几何信息,基于点的方法[22]通常使用多层感知器网络来处理3D LiDAR点,使用不同设计的局部描述符,包括最大汇集函数[23,31]、自适应加权[29,41]和非局部加权[38,4]。尽管与基于投影的方法相比,基于点的方法具有更高的性能,但由于大规模LiDAR点云中复杂的局部聚集操作和大量的点,因此基于点的方法通常是耗时的。
- 目前,最先进的技术是基于体素的方法,它们使用==稀疏卷积[19]==来处理大规模LiDAR点云。与传统的三维卷积算法相比,该算法只对非空体素进行卷积运算,大大降低了计算成本和内存消耗。
- 基于SparseConv,不同的方法使用网络结构搜索[25]、多尺度特征聚集[5]、柱面分割和非对称3D卷积网络[43]、距离-点体素融合网络[35]和多模式网络[37]来提高分割性能。虽然基于体素的方法已经取得了令人印象深刻的结果,但体素的质量对其分辨率是敏感的。
- 体素大小越大,质量越低。这促使我们探索激光雷达点云的超点表示。
方法
激光雷达过分割网络
低级点嵌入
对于LiDAR过分割,我们使用点云的低级嵌入来分割超点。如图1所示,我们将其描述为一个由点云上定义的局部邻域构造的深度度量学习问题。
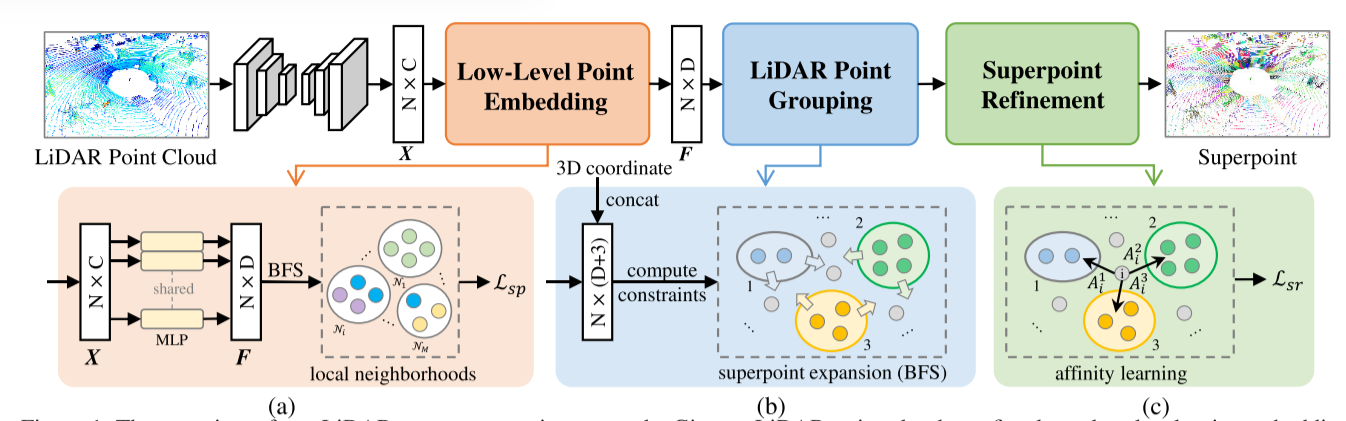
具体地说,给定LiDAR点云P={pi}Ni=1,我们遵循[37]并使用稀疏3D网络来获得特征地图X∈RN×C,其中N是邻域的数量。我们使用MLP将X映射到低维嵌入F∈RN×D中,通过计算点与其周围点之间的欧几里德距离来构造每个点的局部邻域,表示为N={Ni}Ni=1。每个局部邻域Ni是一组三维点,包含位于第i个局部邻域中的点。
在构造了LiDAR点云的局部邻域后,提出了一种局部判别损失LSP算法,将点特征映射到具有相似局部几何结构的低维嵌入空间。对于第i个局部邻域Ni,我们可以根据点标签,即基本真实语义标签(图1(A)中不同颜色的圆圈)来识别不同的语义部分。在有限范围内构造的局部邻域中,具有相同语义标签的点可视为具有相似的几何结构。局部区分性损失LSP由两个项组成:
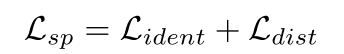
其中,相同项Lident将嵌入的点拉向相应语义部分的平均嵌入,而距离项Ldist将嵌入的点推离其他语义部分。具体表述如下:
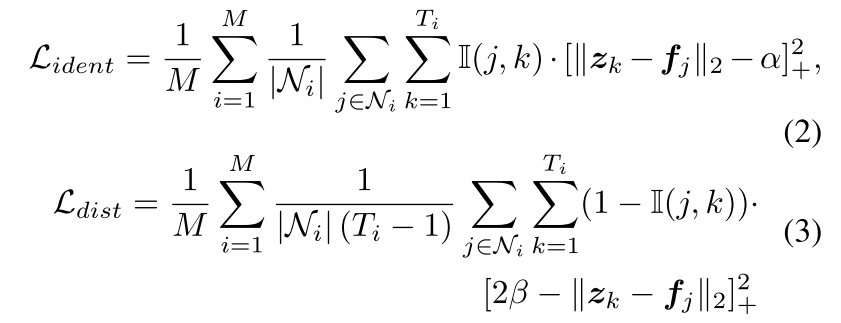
其中i(j,k)是指标函数。如果点j属于第k个语义部分,则i(j,k)等于1,否则等于0。Ti是第i个局部邻域Ni中语义部分的个数。此外,Fj∈Rd表示第i点的点嵌入,Zk∈Rd表示包含第i点的对应语义部分的平均值点嵌入。在实验中,阈值α和β分别被设置为0.01和0.2.
激光雷达点分组
为了提高激光雷达超点分割的推理速度,提出了一种简单而高效的激光雷达点分组算法。如图1所示,其关键思想是通过应用广度优先搜索(BFS)算法,基于学习的低级点嵌入对点进行分组。
具体地说,为了在3D空间中生成齐次紧致的超点,我们同时考虑了嵌入空间和3D坐标空间。
- 在给定LiDAR点云的情况下,我们首先随机选择一个种子点作为BFS起点,该起点尚未分配给超点。
- 然后,根据起始点执行BFS算法,对周围的点进行分组,形成一个超点。程序如图1(B)所示。在BFS过程中,如果一个点可以被分配到相应的超点,那么它应该满足两个约束。
- 对于一个约束,点嵌入之间的欧几里德距离应该小于阈值β,该阈值被认为是用来将点嵌入推开的余量如等式(3)。
- 对于另一个约束,点之间的欧几里德距离应该小于阈值γ,该阈值用于保持超点在3D坐标空间中的紧致性。
- 注意,在BFS期间,如果超点大小(即,超点内的点数)大于最大大小Nmax,则当前的超点增长过程将被终止。
- 在BFS之后,如果生成的超点大小小于最小大小Nmin,则会丢弃该超点。LiDAR点分组算法重复BFS过程,从LiDAR点云生成新的超点,直到它不能满足生成条件。具体步骤如算法1所示。

在超点生成中,也可以采用基于聚类的算法,但它们会在超点上引入噪声点。为了消除噪声点,需要进行后处理,这会带来额外的时间成本。相比之下,BFS算法可以在O(N)的时间复杂度下生成没有噪声点的良好超点,其中N是LiDAR点数。请注意,**我们不是在稀疏的3D空间中执行BFS,而是将稀疏的LiDAR点云转换为密集的距离图像(dense range image)**。由于距离图像中邻接点的边缘是相邻像素网格的边缘,这可以大大节省边缘遍历的时间,因此对深度图像进行边界过滤可以有效地减少三维空间的边界过滤时间。因此,BFS的复杂度约为O(N)。
超点精化
在LiDAR点分组中,我们丢弃了生成的不符合超点最小尺寸的超点,因此一些LiDAR点仍然没有分配给任何超点。处理这些未指定的LiDAR点的简单方法是将点指定给坐标空间中最近的超点中心。但是,未指定的点大多是边界点。因此,很难根据距离将边界点准确地分配到相应的超点。为了保持超点分割的效率,我们提出了一种简单而有效的超点细化模块,通过学习该点与其K-近邻超点之间的亲和力来准确地将该点分配到相应的超点,如图1所示。
具体地说,给定一个未分配的LiDAR点i,我们首先根据该点与超点之间的欧几里德距离在3D坐标空间中找到K-近邻超点(Ki)。点i和超点j∈ki之间的亲和力定义为:
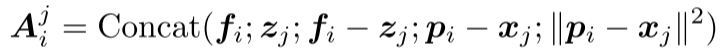
其中,连接(·)表示连接操作。矢量fi−zj和pi−xj分别捕捉嵌入空间和坐标空间中的点和超点之间的差异。请注意,zj∈Rd和xj∈R3是超点的嵌入和坐标。它们是通过平均点坐标和嵌入而获得的。这样,我们就可以得到该点与其K-最近超点之间的亲和力矩阵Ai∈Rk×(4d+1)。之后,我们映射亲和度矩阵以获得亲和度分数,其定义为:
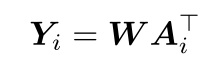
其中W∈R1×(4d+1)是要学习的权重。最后,我们将softmax函数应用于亲和度得分YI∈RK,以获得亲和度概率。通过将点i分配给概率最高的超点,我们可以从LiDAR点云生成高质量的超点。请注意,第i点的基本事实是具有相同语义标签的最近超点。在训练期间,它由交叉熵损失监督,由LSR表示(见图1(C))。
基于超点的LiDAR图像分割
为了显示LiDAR过分割网络的可扩展性和灵活性,我们将学习到的超点应用到LiDAR语义分割任务中。具体地说,我们提出了一个简单的多尺度超点聚合模块,并将其与我们的LiDAR过度分割网络相集成,形成了一个端到端的LiDAR语义分割框架,如图2所示。
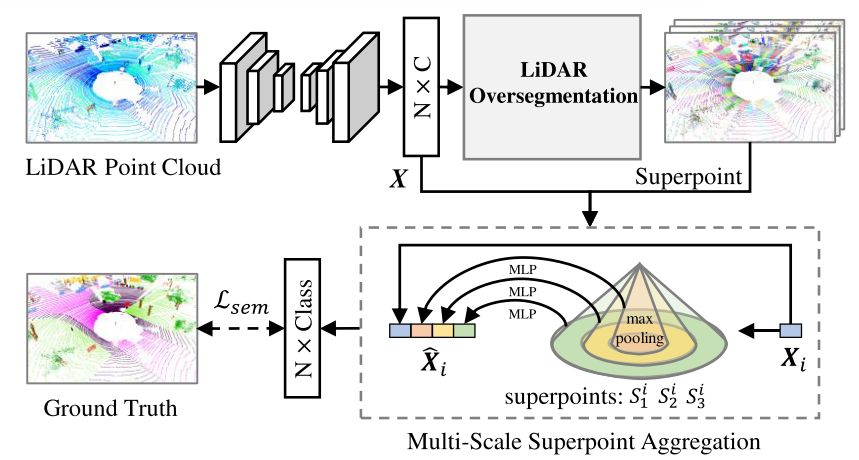
多尺度超点聚集
在LiDAR过分割网络中,稀疏卷积[19]用于提取点的局部特征。然而,基于体素的表示方法不能很好地刻画点云的局部几何结构,从而产生粗特征图X∈RN×C。基于粗略的点特征,我们设计了一个简单的多尺度超点聚集模块,通过融合多尺度局部特征来增强点特征。具体地说,在超点生成过程中,
- 我们首先通过调整超点的最小和最大尺寸来获得多尺度超点。对于第i个点,我们可以得到相应的L尺度的超点,用Si1,Si2,.SiL表示。
- 然后,我们对相应超点内的点特征采用最大合并函数来聚集超点特征(图2中的三个圆锥)。
- 在此之后,超点特征由一系列层组成的MLP独立处理,包括线性、RELU[20]和批归一化[12]。由此产生的超点特征由Ei 1,Ei 2,EiL。最后,融合L尺度的超点特征,聚集点云的多尺度几何信息。生成的第i个点的新特征写为:
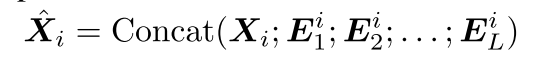
与基于体素表示的粗点特征xi∈RC相比,新的点特征Xˆi∈RC∗(L+1)能够通过多尺度超点精细地刻画点的局部几何结构。在融合后的点特征的基础上,采用分类头来预测点标签。
本质上,超点提供了一个自适应邻域,该邻域是沿点云曲面的几何结构生成的。因此,与基于体素的邻域、基于球查询的邻域和基于k-NN的邻域相比,自适应邻域能够提取更具区分性的局部特征,从而提高了性能。
损失函数由于所提出的LiDAR语义分割框架是一个端到端的网络,因此可以通过联合损失函数直接进行优化。为了训练它,将联合损失函数定义为:
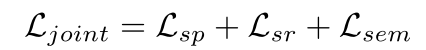
其中,LSP是公式1中定义的训练超点的局部区分性损失。LSR和LSEM分别是超点求精和语义分割的交叉熵损失。
实验
数据集和指标
在本文中,对于LiDAR过分割和语义分割,我们使用了两个大规模的室外数据集,即SemancKITTI[1]和nuScenes[3]。数据集和评估指标的详细信息如下:
- SemancKITTI是一款拥有20个语义类别的大型自动驾驶汽车户外标杆。它包含由64波束LiDAR传感器收集的22个序列,其中序列00到10用于训练集(序列08用作验证集),序列11到22用于在线隐藏测试集。序列00至10具有用于每次扫描的密集语义注释。
- NuScenes包含由32光束LiDAR传感器收集的1000个场景。总共有1000个场景被分为训练(750)、验证(150)和测试(150)集。训练集和验证集被标注了17个语义类别,而测试集的标签被保存以用于在线盲测。
- 评估指标为了评估超点的质量,我们使用Oracle整体准确度(OOA)、边界查全率(BR)和边界精度(BP)作为[13]中定义的评估指标。OOA分析使用超点来衡量语义分割的理论上界,而BR和BP则衡量超点边界的质量。
- 为了平衡BR和BP,我们报告F1分数,其公式为F1=2BP·BR/(BR+BP)。
- 为了评估LiDAR语义分割的性能,我们使用了均值交集对并集(MIoU)。
网络结构
我们使用与[2DPASS,37]中相同的稀疏3D网络作为我们的LiDAR过分割网络的主干。
- 在激光雷达点分组算法中,将边界条件下距离约束的阈值γ设置为1.5。
- 在超点求精模块中,超参数K被设置为5。
- 在多尺度超点聚合模块中,我们使用了三种尺度的超点,它们由不同的超点大小阈值控制。
激光雷达过分割
对于LiDAR过分割,我们将所提出的SuperLiDAR与SPG[15]、SSP[13]和SPNet[11]进行了比较。请注意,SPG使用手工制作的特征,而SSP和SPNet使用深度特征进行超点分割。我们运行官方代码从激光雷达点云生成超点。超点评估结果是分别在语义KITTI和nuScenes数据集的验证集上计算的。
SemantiKITTI的结果。
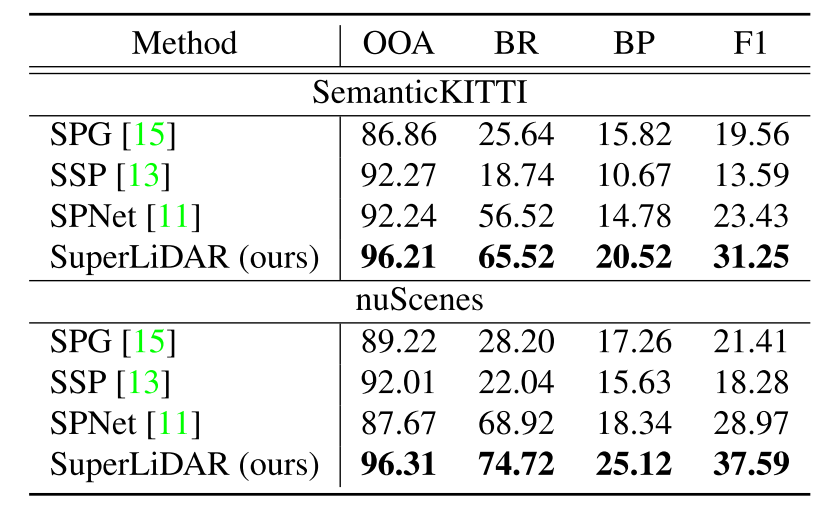
表1给出了基于语义KITTI数据集的超点分割的定量结果。为了进行公平的比较,不同方法生成的超点的数量保持相似(约1000个超点)。可以看出,我们的方法在四个指标上取得了最好的结果。
- 特别是,我们的SuperLiDAR在OOA方面比其他方法高出约4%,这代表了语义分割性能的理论上限。因此,这意味着我们的方法能够以更高的精度生成高质量的超点。
- 此外,我们的方法具有较高的BR和BP,这表明我们的方法可以在稀疏的LiDAR点云中生成边界清晰的超点。
- 由于稀疏的LiDAR点云,SPG[15]的手工制作特征的区分性较差,导致性能较差。
- 虽然SSP[13]使用了深度特征,但它通过基于优化的方法[14]生成超点,这限制了稀疏LiDAR点云的性能。
- 在稀疏点云中,基于聚类的方法SPNet[11]生成的超点很可能包含噪声,从而影响性能。
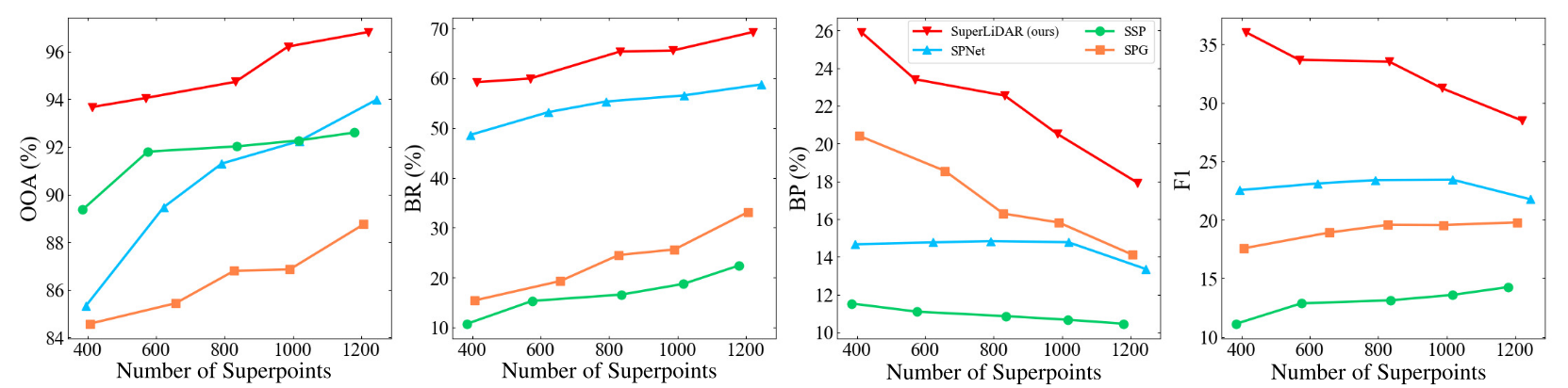
- 在图3中,我们展示了不同方法在不同超点数目下的性能曲线。可以观察到,我们的方法的曲线在四个度量方面都高于其他方法。超点越多,超点越小,反之亦然。结果表明,该方法可以生成不同大小的高质量超点。
nuScenes的结果
nuScenes数据集上超点分割的定量结果显示在表1中.请注意,不同方法生成的超点数量保持相同(约400个超点)。与SemancKITT的64波束点云相比,nuScenes的32波束点云更加稀疏。从表中可以看出,我们的方法在所有四个指标上仍然取得了最好的结果。在nuScenes数据集上的实验结果进一步表明,该方法可以有效地生成稀疏LiDAR点云中的高质量超点。
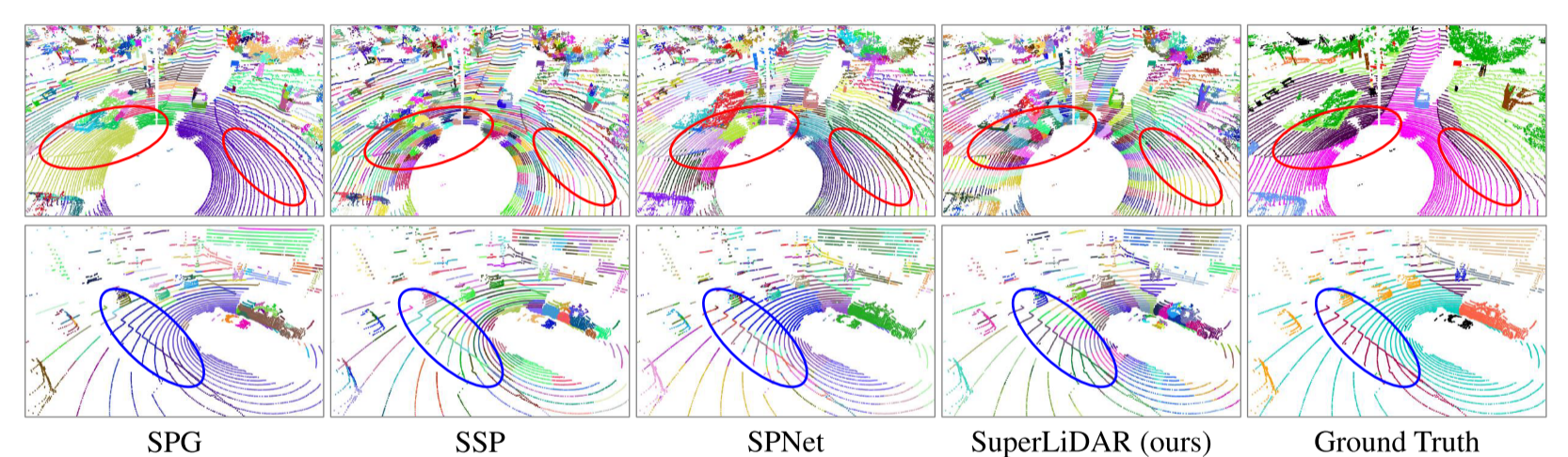
可视化结果
在图4中,我们展示了不同过分割方法的可视化结果。可以观察到,我们的SuperLiDAR生成的超点可以有效地区分道路和人行道。注意,道路和人行道几乎在同一水平面上,因此如果没有颜色信息,很难区分它们。尽管如此,我们的方法仍然能够学习区分点特征,利用局部区分性损失来分离它们。
时间代价
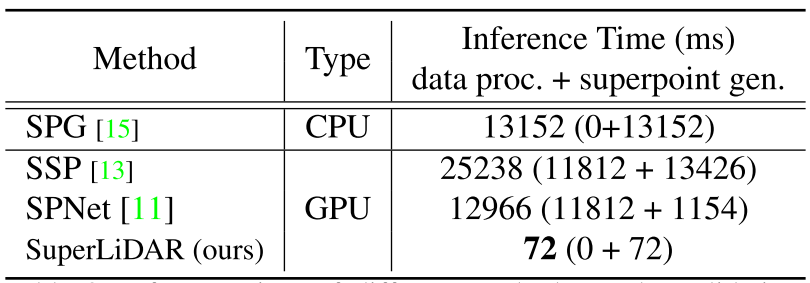
推理时间是超点分割的一个重要标准。
- 对于基于优化的方法SPG[15],我们使用单个Corei5 CPU来计算推理时间。
- 对于基于学习的方法SSP[13]、SPNet[11]和我们的SuperLiDAR,我们使用单个NVIDIA RTX 3090来运行基于PyTorch深度学习平台的代码。
表2报告了不同方法在语义KITTI验证数据集的每次扫描上计算的平均推理时间。可以看出,我们的方法的推理时间仅为72ms,比其他方法快100倍。虽然SSP和SPNET使用网络来提取点特征,但它们也将手工制作的点特征馈送到网络中,导致数据处理时间较长。请注意,SSP和SPNET的数据处理相同,因此它们的数据处理时间相同。由于SPG和SSP采用相同的基于优化的方法来生成超点,所以它们的超点生成时间较长。由于sPNET的超点生成采用迭代策略,因此比我们的方法耗时更多。
消融研究
在低级点嵌入学习中,我们在距离图像(range image)中而不是在3D空间中构造局部邻域,并在语义KITTI数据集上进行实验。表3展示了在三维空间中构建邻域的结果。可以观察到,建筑街区在3D空间中的表现(“Build nei.在3D空间中“)比在距离图像(”Default(SuperLiDAR)“)中差。与3D空间相比,距离像中的点更加均匀。由此得到的稠密邻域对应用局部区分损失学习好点嵌入是有益的。
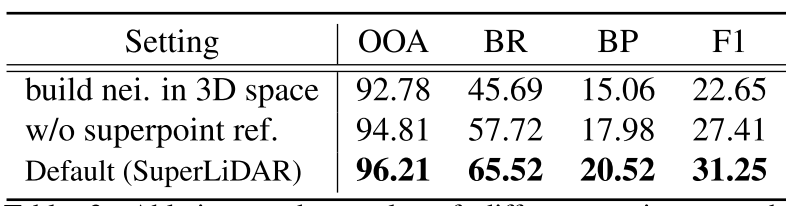
为了解决LiDAR点分组后未分配点的问题,提出了一种超点细化模块。为了验证其有效性,我们通过将点分配到坐标空间中最近的超点中心来替换超点求精模块。表3结果(“无超点参考”)低于使用超点细化模块(“Default(SuperLiDAR)”)。由于简单的距离准则,硬边界点不能有效地分配给相应的超点。通过自适应地学习点和超点之间的亲和力,我们可以更准确地将点分配到相应的超点。
为了解决LiDAR点分组后未分配点的问题,提出了一种超点细化模块。为了验证其有效性,我们通过将点分配到坐标空间中最近的超点中心来替换超点求精模块。在选项卡中。3、结果(“无超点参考”)低于使用超点细化模块(“Default(SuperLiDAR)”)。由于简单的距离准则,硬边界点不能有效地分配给相应的超点。通过自适应地学习点和超点之间的亲和力,我们可以更准确地将点分配到相应的超点。
LiDAR语义分割
对于LiDAR语义分割,我们在语义KITTI和nuScenes数据集上进行了实验,以验证学习超点的有效性。我们的LiDAR语义分割框架基于LiDAR过度分割网络,并使用多尺度超点聚合模块进行语义预测。我们使用LiDAR过分割网络的主干(即稀疏3D网络)作为基线。由于我们的基线是在[37]中使用的稀疏3D网络,因此我们直接将[37]的基线结果作为我们的方法在语义KITTI和nuScenes数据集上的基线结果。
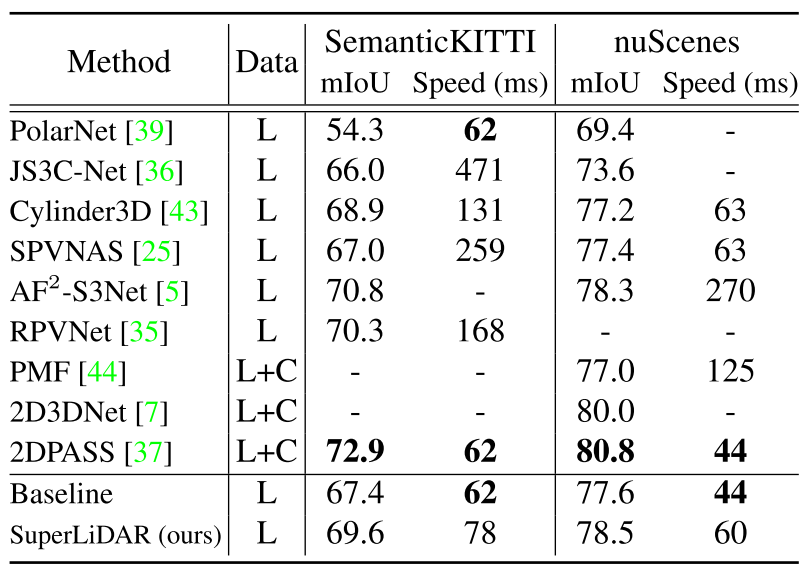
SemantiKITTI的结果。
表4给出了语义分割在语义KITTI在线测试集上的实验结果。可以观察到,我们的SuperLiDAR的MIU值比基线高出2%。此外,图5显示了基线和我们的方法的可视化结果(第一行)。实验结果表明,利用学习的超点来增强点云的局部几何信息,可以进一步提高语义分割的性能。由于采用了复杂的点-体素或距离-点-体素融合框架,RPVNet[35]和AF2-S3Net[5]的性能要高于我们的基于体素的方法。此外,2DPASS[37]是一种多模式方法,它使用2D图像和知识提取来实现更高的性能和更短的推理时间。由于采用了简单有效的多尺度超点聚合模型,在不增加太多时间开销的情况下,有效地提高了基线的性能。

NuScenes的结果。
表4给出了在nuScenes在线测试集上的语义分割结果。可以观察到,我们的SuperLiDAR的MIU值超过了基线约1%。此外,图5显示了基线和我们的方法的可视化结果(第二行)。由于nuScenes的点云比SemancKITTI的点云更稀疏,定量和可视化结果表明,学习的超点可以有效地提高分割性能。与仅使用LiDAR数据的方法相比,该方法可以在更短的推理时间内获得更高的性能。请注意,即使我们只使用LiDAR数据,我们的方法的性能也要好于使用LiDAR点云和相机图像的PMF[44]。此外,多模式方法2D3DNet[7]和2DPASS[37]采用复杂的多尺度融合网络以获得更高的性能。
结论
提出了一种高效的端到端LiDAR过分割网络,用于从LiDAR点云中分割超点。通过使用所提出的LiDAR点分组算法,我们的方法可以从稀疏的LiDAR点云中生成高质量的超点。值得注意的是,我们的方法在激光雷达过分割方面取得了新的进展,并且推理时间比现有方法快100倍。此外,在LiDAR语义分割上,通过使用超点,我们的方法可以显著提高两个大规模基准测试(即SemancKITTI和nuScenes)的基线结果。我们相信,提出的高效LiDAR过分割网络可以应用于更多的下游任务,如3D检测和跟踪。



