Learning Superpoint Graph Cut for 3D Instance Segmentation (未完待续)
摘要
由于点云中目标的复杂局部几何结构,3D实例分割是一项具有挑战性的任务。在本文中,我们提出了一种基于学习的超点图割方法,它显式地学习点云的局部几何结构,用于3D实例分割。具体地说,
- 我们首先将原始点云过分割成超点,并构造超点图。
- 然后,我们提出了一个边分数预测网络来预测超点图的边分数,其中通过交叉图注意力在坐标和特征空间中学习到的相邻节点的相似性向量被用来回归边分数。通过迫使同一实例的两个相邻节点在坐标和特征空间中靠近实例中心,我们提出了一种几何感知的边缘损失(Geometry-Aware Edge Loss)来训练边缘得分预测网络。
- 最后,我们开发了一个超点图割网络,该网络利用学习到的边分数和预测的节点语义类别来生成实例,其中提出了双边图注意力来提取坐标空间和特征空间上的区分特征来预测语义标签和实例分数。在ScanNet v2和S3DIS这两个具有挑战性的数据集上的大量实验表明,该方法在3D实例分割上达到了最新的性能。
1.引言
近年来,随着激光雷达、Kinect摄像机等三维传感器的发展,各种三维计算机视觉任务受到越来越多的关注。3D场景分割是3D场景理解中的一项基本任务,在自动驾驶汽车、虚拟现实、机器人导航等领域有着广泛的应用。尽管近年来3D实例分割的进展令人鼓舞,但==由于复杂几何结构的3D场景中3D点的不规则性和上下文不确定性==,分割仍然是一项具有挑战性的任务。
许多人致力于3D实例分割,并取得了令人满意的性能。这些方法主要可以分为两类:基于检测的方法[44,45]和基于聚类的方法[40,18]。
- 在基于检测的方法中,3D-Bonet[44]首先检测3D包围盒,然后使用掩码预测网络预测目标掩码以用于3D实例分割。然而,对于具有复杂几何结构的目标,基于检测的方法[45]无法获得准确的3D边界框,从而降低了实例分割的性能。
- 基于聚类的方法SGPN[40]基于语义分割对三维点进行聚类生成实例。与SGPN不同的是,酱等人。[18]提出了一种基于双重坐标空间(包括原始坐标空间和移动坐标空间)中的语义预测来聚类点的偏移量分支。此外,一些后续方法利用树结构[25]、层次聚集[3]和软语义分割[37]来提高3D实例分割的性能。然而,这些基于聚类的方法大多依赖于中心偏移量和语义来分割实例,不能有效地捕捉点云的几何上下文信息。因此,点云中具有复杂几何结构的目标往往限制了实例分割的性能。
在本文中,我们提出了一种基于学习的超点图切割方法,该方法显式地学习点云的局部几何结构来分割3D实例。具体地说, ==我们构造超点图来学习超点的几何上下文相似性,并将实例分割转化为边的二进制分类==。
我们的方法包括一个用于预测边缘分数的边缘分数预测网络和一个用于生成实例的超点图割网络。
- 在我们的方法中,我们将原始点云过分割成超点,并通过链接坐标空间中k个最近的超点来构造超点图。
- 在边分数预测网络中,我们首先对两个相邻节点的局部邻域进行交叉图注意力,以提取局部几何特征来衡量节点的相似性。
- 然后,基于从坐标空间和特征空间学习到的相似性向量,采用边缘分数分支来预测边缘分数。
- 此外,我们还提出了一种几何感知的边缘损失来训练边缘得分预测网络,该方法迫使同一实例的相邻节点在坐标空间和特征空间中都靠近实例中心。
- 在超点图割网络中,我们使用学习到的边分数结合节点的语义类别来切割边,以形成object proposals。
- proposals是通过在超点图上应用广度优先搜索算法来聚合同一连通分量中的节点而得到的。
- 在每个proposals中,我们应用双边图注意力来聚合局部几何特征,以提取可区分的特征来预测类别和数十个proposals。
- 此外,我们采用掩码学习分支来过滤proposals中的低置信度超点以生成实例。
综上所述,我们提出了一种边缘分数预测网络,该网络学习相邻节点的局部几何特征来生成边缘分数。
- 为了训练它,我们提出了一种几何感知的边缘损失,以同时在坐标空间和特征空间保持实例的紧凑性。
- 提出了一种超点图割网络,该网络通过在坐标和特征空间中利用双边图注意力来提取可区分的实例特征来生成准确的实例。在ScanNet v2[7]和S3DIS[1]数据集上的大量实验表明,该方法在3D实例分割上达到了最新的性能。在ScanNet v2的在线测试集上,我们的方法在MAP方面达到了55.2%的性能,比目前最好的结果高出4.6%[25]。对于S3DIS,我们的方法在MAP方面比当前最好的结果[37]要好2%以上。
2.相关工作
3D语义分割
从不规则的三维点云中提取特征是3D语义分割的关键。
- qi等人[30]首先提出了PointNet,通过多层感知器网络从点集学习逐点特征进行语义分割。在此之后,人们提出了许多改进语义分割性能的努力[24,34,46,15,47,4,2]。早期的基于点的方法[36,43,31,14]设计了各种局部特征聚合策略来提取可区分的逐点特征用于语义分割。
- 受成功的2D卷积网络的启发,基于视图的方法[23,35,17,19]将点云投影到多个规则的2D视图中,在其中应用规则的2D卷积来提取特征。
- 除了基于视点的方法外,基于体积的方法[27,39,10,6]首先将点云体素化为规则的3D网格,然后应用3D卷积来提取点云的局部特征。
- 为了捕捉点云的局部几何结构,基于图的方法[42,22,38,5,16]在点云上构造图形,并利用图的卷积来聚集局部几何信息进行语义分割。
3D实例分割
3D实例分割是一项更具挑战性的任务,它进一步需要识别每个实例。目前的方法大致可以分为两类:基于检测的方法和基于聚类的方法。
- 基于检测的方法[45,13,26]首先检测点云中每个目标的3D包围盒,然后在每个包围盒上应用掩码预测网络来预测3D实例分割中的目标掩码。在[44]中,提出了一种称为3D-BoNet的3D实例分割框架,该框架直接回归所有实例的3D边界框,并预测每个实例的点级掩码。Yi等人的研究成果。[45]提出了一种生成式形状proposal网络,该网络通过从场景中的噪声观测重建形状来生成proposal,用于3D实例分割。此外,使用几何体和RGB输入,[13]开发了联合2D-3D特征学习网络,该网络结合2D和3D特征以回归3D目标边界框并预测实例masks。
- 基于聚类的方法通常使用点相似性[40]、语义地图[11,20]或几何移位[18,3,25,33]来将3D点聚类成对象实例。文献[40]中提出了一种相似度分组proposal网络,通过学习逐点相似度来聚类点以生成实例。[29]提出了一种多任务学习框架,该框架同时学习3D点的语义类别和高维嵌入,以将点聚类为对象实例。在[41]中,引入了一个分割框架来学习语义感知的逐点实例嵌入,用于关联分割点云实例和语义。Hanet al.[11]提出了一种占用率感知的方法来预测每个实例的占用体素数。PointGroup[18]通过使用预测的逐点中心偏移向量和逐点语义标签来聚类点。后续方法[3]采用分层聚集策略进行3D实例分割,首先进行点聚集,将点聚类成初步集合,然后再进行集合聚集,将集合聚类成实例。最近,Vu等人。[37]提出了一种软分组策略,通过将每个点与多个类别相关联来缓解语义预测错误的问题,从而在3D实例分割中获得显著的性能提升。此外,文献[25]还提出了一种语义超点树网络,称为SSTNet,用于分割实例中的点云。该算法首先对语义特征相似的超点进行分组,构建一棵二叉树,然后通过树的遍历和分裂生成实例。为了提高网络的效率,将动态卷积网络与小型变压器网络相结合,提出了一种轻量级的3D实例分割方法[12]。
3.方法
基于学习的超点图割方法的概述如图1所示。基于超点图,边分数预测网络(SEC。3.1)从坐标和特征空间中提取边缘嵌入,用于预测边缘得分。之后,超点图割网络(SEC.3.2)通过学习区分实例特征来预测类别和实例分数,从而生成准确的对象实例。最后,在SEC3.3中,我们描述了如何从点云中训练我们的方法和推理实例。
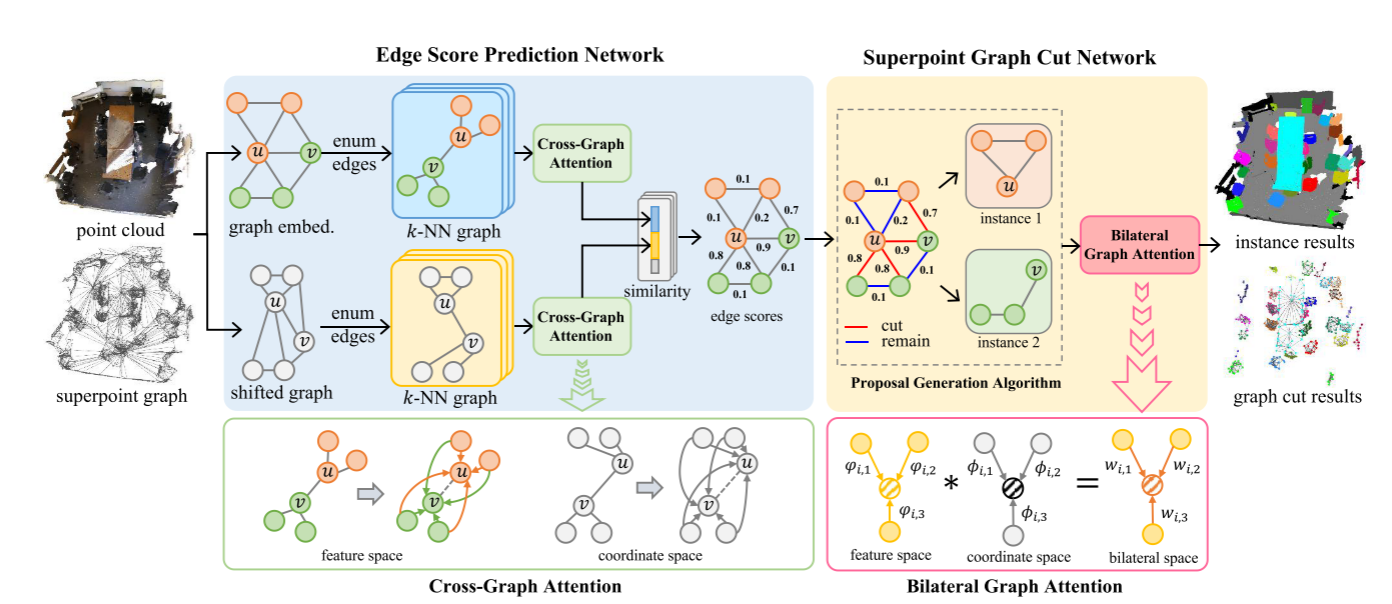
3.1.边缘得分预测网络
给定一个原始点云,我们将其过分割成超点,并构造超点图G=(V,E),其中V表示超点的节点集,E表示边集。由于超点表示比点表示更粗糙,直接从超点表示学习特征不能有效地捕捉点云的局部几何结构。
- 因此,我们在点云上应用子流形稀疏卷积[10]来提取点级特征,并使用点级特征通过平均汇集来初始化超点级特征。
- 之后,我们应用边缘条件卷积[32]来提取超点特征,记为F∈R|V|×C,其中C是特征维度。
3.1.1.边缘特征嵌入(Edge Feature Embedding)
一旦我们获得超点特征,边缘得分预测网络就学习边缘嵌入(edge embeddings)来预测分割实例的边缘得分。给定相邻节点(u,v)∈E,期望学习边嵌入可以有效地识别节点u和v是否属于同一实例。为了解决这个问题,我们将交叉图注意力应用于双空间(坐标空间和特征空间)中的超点图,以学习超点相似性。学习到的节点u和v的相似度向量被用来形成用于预测边缘得分的边缘嵌入。
在坐标空间中边缘嵌入。
为了刻画节点u和v的相似性,
- 我们首先将它们移向坐标空间中对应的实例质心。这里,多层感知器(MLP)网络对F进行编码以产生|V|偏移向量O={o1,.。。,o|V|}∈R|V|×3。给出原始超点坐标X={x1,.。。,x|V|}∈R|V|×3,移位的超点坐标Xˆ={ˆx1,.。。,ˆx|V|}由Xˆ=X+O得到,这样就增加了属于不同实例的节点之间的几何距离,从而增强了对超点的区分。
- 然后,基于移动后的坐标空间,对于节点u,利用其k个最近的超点(即Nu)来构造局部k-NN图Gu。同样,我们可以得到节点v的图GV。
- 接着,我们对Gu和Gv进行交叉图注意力,通过学习的特征向量来表征节点的相似性,如图1所示。以节点u为例,交叉图注意力的权重α定义为:
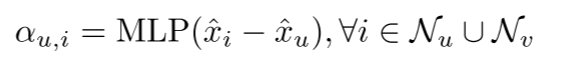
- 其中ˆxi和ˆXu是移动后的坐标。请注意,我列举了两个图中的所有2*k个邻neighbors。因此,最终输出特征向量可表示为:
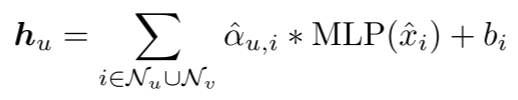
- 其中ˆαu,i是权重αu,i在Softmax之后,bi是可学习的偏差。学习的特征向量hu∈RC可以通过自适应地学习两个图上的几何差异来表征几何相似性。同样,我们可以得到另一个节点v的特征向量hv。我们将特征向量hv和hv组合为嵌入在坐标空间中的边:eu,v=[hu,hv]。
特征空间中的边缘嵌入。
除了考虑坐标空间外,我们还考虑了特征空间来提取可区分的边缘嵌入。
- 首先,一个MLP网络对F进行编码以产生嵌入Z∈Rd的初始特征。通过将实例的特征嵌入相互推开,扩大了不同实例在特征空间中的距离。
- 给定一对结点(u,v)∈E,我们在特征空间中分别构造了k-NN图ˆGu和ˆGV。通过这种方式,可以预期每个图可以聚合同一实例中的超点。
- 然后,我们在ˆGU和ˆGV上执行交叉图注意力来刻画特征空间中节点的相似性。最后得到特征向量ˆhu∈Rc和ˆhv∈Rc。如果u和v属于同一实例,则它们在特征空间中共享相似的k-NN图,从而使得学习到的特征向量hˆu和ˆhv彼此相似。在这里,我们还结合特征向量来得到在特征空间中边缘嵌入:ˆeu,v=[ˆhu,ˆhv]。
边缘分数预测。
在获得坐标空间和特征空间中的边缘嵌入后,我们利用一个简单的MLP网络来生成边缘分数,其定义如下:
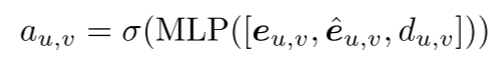
其中[·,···]表示串联运算,σ表示Sigmoid函数,du,v表示节点u和v在移位坐标空间中的几何距离。在实验中,如果边得分au,v>0.5,则意味着节点u和v之间的边应该从超点图中截断。我们使用二进制交叉熵损失Ledge来最小化边缘得分。
3.1.2.几何感知边缘损失(Geometry-Aware Edge Loss)
为了训练边分数预测网络,我们使用超点图的几何结构来形成几何感知边损失,如图2所示。
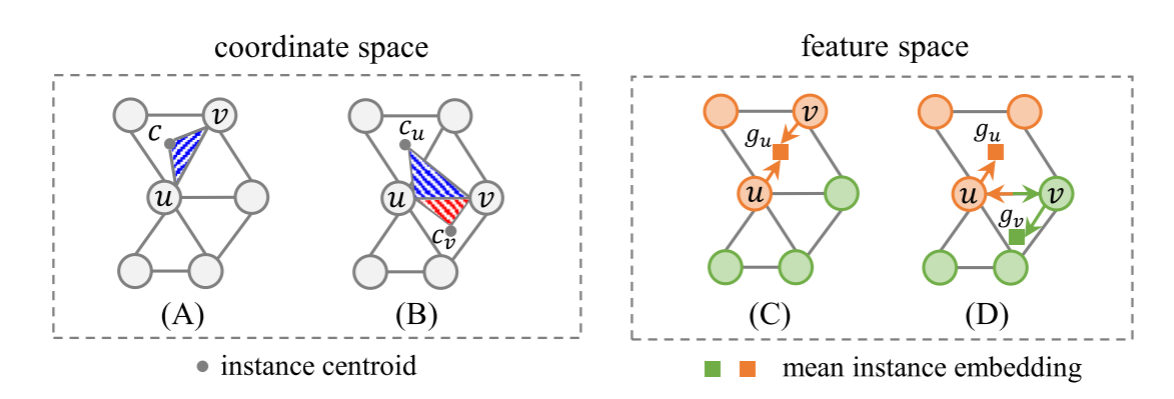
具体地说,给定节点u、v及其对应的实例质心cu和cv,我们通过最小化L2距离du、cu和dv、cv来向它们的实例质心绘制节点。此外,当(u,v)∈E属于同一实例时,期望它们可以通过最小化三角形UVC的面积来协作地移动到相同的实例质心c。如果(u,v)∈E属于不同的实例,但期望它们可以通过最小化三角形uvcu和uvcv的面积来协作地转移到它们自己的实例质心cu和cv。坐标空间中的面积约束写成:
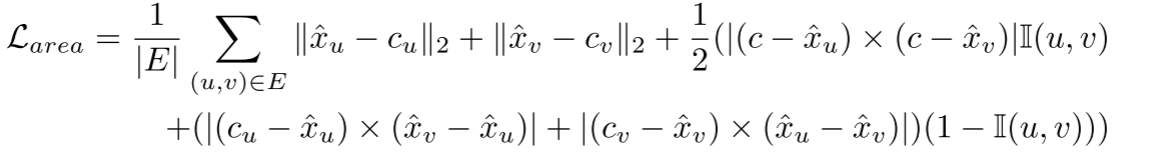
其中i(u,v)是指示函数,如果u和v属于同一实例,则i(u,v)等于1,否则等于0。请注意,“×”表示用于计算三角形面积的矢量的外积。对于来自同一实例的节点u和v,u和v同时靠近公共实例质心。因此,它们在坐标空间中拉得很近,这有助于将u和v组合到同一实例中。对于来自不同实例的节点u和v,u和v分别接近对应的实例质心。因此,它们在坐标空间中被推开,这有助于将u和v分成两个不同的实例。
同样,我们期望同一实例中的节点通过约束其特征嵌入而在特征空间中是紧凑的。对于(u,v)∈E属于同一实例,我们将u和v的嵌入画向实例的平均嵌入,并将它们拉到彼此之间。对于(u,v)∈E属于不同的实例,我们将u和v的嵌入相互推开。此外,通过增加实例自身的平均嵌入距离,实例彼此推开。因此,特征空间中的约束写成:
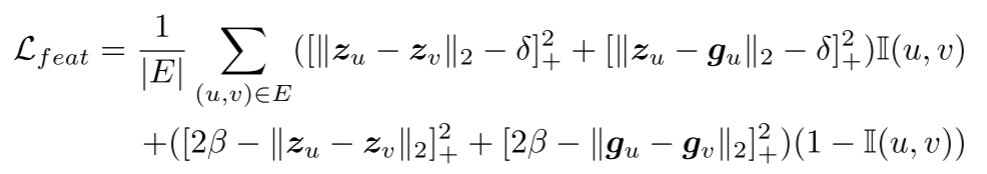
其中zu∈Rd和zv∈Rd是特征嵌入。注意,gu∈Rd和gv∈Rd分别指示u和v所属的实例的平均特征嵌入。阈值δ和β设置为0.1和1.5,以确保实例间距离大于实例内距离。最后,几何感知边缘损失被定义为:
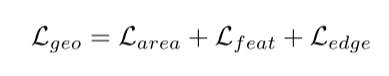
3.2.超点图割网络(Superpoint Graph Cut Network)
3.2.1.基于超点图割的proposal生成方法
给定边得分A={au,v}∈R|E|×1,我们提出了一种proposal生成算法,通过同时利用学习的边得分和预测的节点语义类别(即超点)来生成候选proposal。具体地说,
- 为了减少语义预测误差,我们遵循[37],采用soft阈值θ将节点与多个类别相关联。给定超点的语义分数S={s1,.。。,S|V||si∈RN,i=1,.。。,|V|},其中N是类的数目,如果si v>θ,则第v个超点可以与第i个类相关联。这样,对于第i类,我们可以对超点图上的一个超点子集Ci进行切片,其中第i类索引上的超点的语义得分高于θ。
- 然后,在超点图上,对于边(u,v)∈E,如果节点u∈Ci和v∈Ci,边(u,v)将被保留,否则边将被删除。换句话说,我们去掉了两个语义不同的超点节点之间的边。
- 接着,对于超点图上保留的边(u,v),我们利用边分数au,v来确定是否应该从超点图中切出边。在实验中,切割边缘的阈值设置为0.5。如果边得分高于0.5,则将从超点图中剪切该边。
- 最后,我们在超点图上应用广度优先搜索算法来聚集同一连通分支中的节点,以生成第i类的proposal。通过这种方式,我们可以通过迭代N个类来生成N个类的proposal。详细信息如算法1所示。

3.2.2.proposal嵌入中的双边图注意力
随着我们获得proposals I={I1,.。。从点云数据出发,通过在坐标空间和特征空间应用注意机制,我们提出了双边图注意来提取生成实例的proposal嵌入。具体地说,给定第i个proposal,我们首先通过平均移位的超点坐标来计算方proposal质心Ci。然后,我们采用相应超点的反距离加权平均来对proposals 质心的嵌入进行插补,其公式如下:



