Superpoint Transformer for 3D Scene Instance Segmentation(未完待续)
摘要
现有的大多数方法通过扩展用于3D对象检测或3D语义分割的模型来实现3D实例分割。然而,这些非直截了当的方法有两个缺点:
- 1)不精确的边界框或不令人满意的语义预测限制了整体3D实例分割框架的性能。
- 2)现有方法需要耗时的聚合中间步骤。
针对这些问题,本文提出了一种基于超点变换的端到端3D实例分割方法SPFormer。它将点云中的潜在特征分组为超点,并通过查询向量直接预测实例,而不依赖于对象检测或语义分割的结果。
- 该框架的关键是设计了一种带transformer的查询解码器,通过超点交叉注意机制捕获实例信息,并生成实例的超点掩码。
- 通过基于超点掩码的二分图匹配,SPFormer无需中间聚合步骤即可实现网络训练,加快了网络的运行速度。
- 在ScanNetv2和S3DIS基准测试程序上的大量实验验证了该方法的简明性和有效性。值得注意的是,在ScanNetv2隐藏测试集上,SPFormer在MAP方面比现有的方法高出4.3%,同时保持了快速的推理速度(每帧247ms)。
引言
3D场景理解被认为是许多应用的基本要素,包括增强/虚拟现实(Park等人)。2020)、自动驾驶(周等人2020)和机器人导航(谢等人2021年)。通常情况下,实例分割是三维场景理解中的一项具有挑战性的任务,其目的不仅是检测稀疏点云上的实例,而且为每个实例提供清晰的掩码。
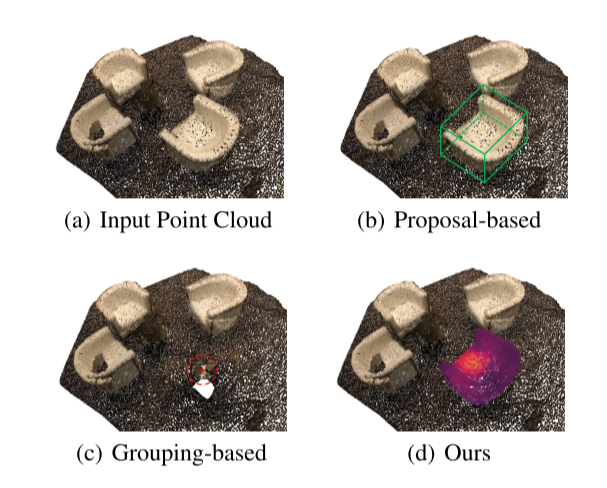
现有的最先进的方法可以分为基于proposal的方法(Yang等人)。2019年;刘等人。2020)和基于分组(酱等人2020年;Chen等人。2021年;梁等人。2021年;Vu等人。2022年)。
- 基于proposal的方法将3D实例分割视为一条自上而下的pipeline。它们首先生成区域proposals(即边界框),如图1(B)所示,然后预测proposes区域中的实例掩码。这些方法受到MASK-RCNN巨大成功的鼓舞(他等人)。2017)在2D实例分段字段上。然而,由于域间隙的原因,这些方法在点云上遇到了困难。在三维领域中,包围盒具有更多的自由度(DoF),增加了拟合的难度。此外,点通常只存在于物体表面的一部分,这导致无法检测到物体的几何中心。此外,低质量的区域proposal影响基于盒的二分图匹配(Yang等人。2019年),并进一步降低了模型的性能。
- 相反,基于分组的方法采用自下而上的pipeline。它们学习逐点语义标签和实例中心偏移量。然后,它们使用偏移点和语义预测来聚集成实例,如图1(C)所示。在过去的两年中,基于分组的方法在3D实例分割任务中取得了很大的改进(梁等人)。2021年;Vu等人。2022年)。但也存在一些不足:
- (1)基于分组的方法依赖于它们的语义分割结果,这可能导致错误的预测。将这些错误预测传播到后续处理会抑制网络性能。
- (2)这些方法需要一个中间的聚合步骤,增加了训练和推理时间。聚合步骤独立于网络训练,缺乏监督,需要额外的细化模块。
本文提出了一种基于超点变换的端到端两阶段3D实例分割方法SPFormer。SPFormer自下而上地将点云中的潜在特征分组到超点中,并通过查询向量将实例proposes作为自上而下的pipeline。
- 在自下而上的分组阶段,利用稀疏的三维U-net提取自下而上的逐点特征。提出了一种简单的超点池化层,用于将潜在的逐点特征分组为超点。超点(Landrieu和Simonovsky 2018)可以利用几何规则来表示均匀的邻接点。与以前的方法(梁等人)不同2021),我们的超点特征是潜在的,避免了通过非直截了当的语义和中心距离标签来监督特征。==我们将超点作为3D场景潜在的中层表示,并直接使用实例标签来训练整个网络。==
- 在自上而下的提proposal阶段,提出了一种新的带transformers的查询解码器。我们利用可学习的查询向量从潜在的超点特征中提出实例预测,作为自顶向下的pipeline。可学习查询向量通过超点交叉注意机制捕获实例信息。图1(D)示出了这样的过程,即椅子的部分越红,查询向量就越关注。利用携带实例信息和超点特征的查询向量,查询解码器直接生成实例类、得分和掩码预测。最后,通过基于超点掩码的二分图匹配,SPFormer可以实现端到端的训练,而不需要耗时的聚合步骤。此外,SPFormer没有像非最大值抑制(NMS)那样的后处理,进一步加快了网络速度。
SPFormer在ScanNetv2和S3DIS基准测试中都达到了最先进的水平。特别是,SPFormer在定性和定量指标以及推理速度方面都超过了同类最先进的方法。SPFormer采用了一种新的流水线,可以作为3D实例分割的通用框架。总而言之,我们的贡献如下:
- 我们提出了一种端到端的两阶段方法SPFormer,该方法不依赖于目标检测或语义分割的结果来表示具有潜在超文本特征的3D场景。
- 设计了一个带有transformers的查询解码器,其中可学习的查询向量可以通过超点交叉注意来捕获实例信息。通过查询向量,查询解码器可以直接生成实例预测。
- 通过基于超点掩码的二分图匹配,SPFormer可以实现网络训练,而不需要耗时的中间聚合步骤,也不需要复杂的推理后处理。
相关工作
以proposal为基础的方法。
例如,基于proposal的方法采用自上而下的方法进行分割。以前的方法(Yi等人)2019年;侯、戴和尼埃纳2019年;成田等人。2019)专注于将2D图像要素和点云要素融合到一个体积网格中,并从该网格生成区域proposals。3D-Bonet(Yang et al.2019)使用PointNet++(齐等人2017a,b)从点云中提取特征,并将3D包围盒生成任务视为最优分配问题。GICN(Liu et al.2020)预测高斯热图以选择实例中心候选,并在提议的边界框内产生实例掩码。3D-MPA(Engelmann等人2020)样本预测质心和质心附近的聚集点以形成最终实例遮罩。大多数基于proposals的方法都基于3D边界框。然而,低质量的包围盒预测会影响实例分割模型的性能。
基于分组的方法。
基于分组的方法将3D实例分割视为一条自下而上的pipeline。MTML(Lahoud et al.2019)利用多任务策略学习特征嵌入。PointGroup(酱等人)2020)从原始和中心移动的点云中聚集点,并设计ScoreNet来评估聚集的质量。PE(Zhang And Wonka 2021)引入了一种新的概率嵌入空间。Dyco3D(何、沈和van den Hengel 2021)引入了动态卷积核。HAIS(Chen et al.2021)使用分层聚集来扩展PointGroup,并过滤实例预测内的噪声点。SSTNet(梁等人)2021)构建语义超点树,并通过拆分不相似节点获得实例预测。SoftGroup(Vu等人)2022)使用较低的聚类阈值来解决错误的语义硬预测,并使用微小的3D U-net来优化实例。尽管基于分组的方法可能有一个自上而下的精化模块,但它们仍然不可避免地依赖于中间聚合步骤。
使用Transformer进行2D实例分割。
最近,Transform(Vaswani et al.)2017)被引入到图像分类中(Dosovitski等人。2020年;Touvron等人。2021年;刘等人。2021)、目标检测(Carion等人2020年;戴相龙等人。2021)和分段(cheng,Schwing,and Kirillov,2021;cheng et al.2022A;郭某等人。2021年)。还有一些实例分割方法(Fang等人)。2021年;程等人。2022b)受到transformer的启发。Mask2Former(程等人)2022A)成功地应用tranformers构建了二维图像语义、实例和全景分割的通用网络。
受到Transform在2D分割任务中的成功应用的启发,我们有动力将Transform引入到3D实例分割中。然而,由于注意机制的复杂性,transformer不能简单地应用于稀疏卷积主干的输出,因为它会引入很高的计算开销。
本文中,我们将设计一种新的查询解码器用于3D实例分割,并使用超点在主干和查询解码器之间架起一座桥梁。
方法
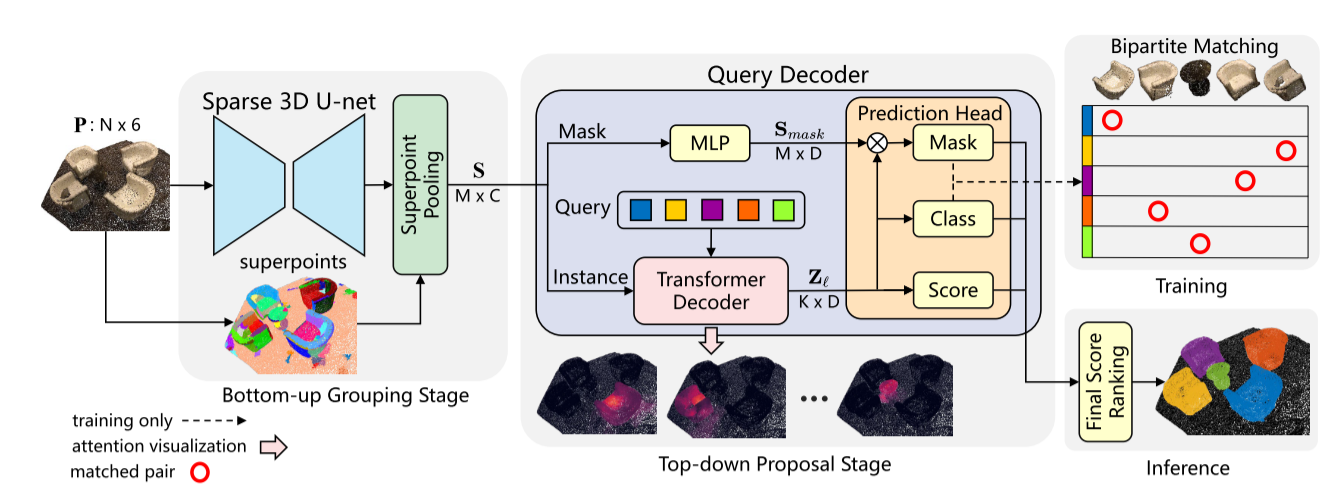

SPFormer的体系结构如图2所示。首先,使用稀疏的3D U-net来提取自下而上的点状特征。提出了一种简单的超点池化层,用于将潜在的逐点特征分组为超点。其次,提出了一种新的带变换的查询解码器,其中可学习的查询向量通过超点交叉注意来获取实例信息。最后,通过基于超点掩码的二分图匹配,SPFormer可以实现端到端的训练,而不需要耗时的聚合步骤。
Backbone and Superpoints
稀疏3D U-net。
假设输入点云有N个点,输入可以表示为P∈RN×6。每个点都有颜色r,g,b和坐标x,y,z。在前面的实现(Graham,Engelcke和Van Der Maten 2018)之后,我们将点云体素化用于常规输入,并使用子流形稀疏卷积(SSC)或稀疏卷积(SC)组成的U-net骨干来提取点特征P∈RN×C。我们在补充材料中给出了稀疏3D U-net的细节。与常用的基于分组的方法不同,我们的方法不增加额外的语义分支和偏置分支。
超点池化层。
为了构建端到端框架,我们直接将逐点功能P∈RN×C馈送到基于预计算超点的超点池层(Landrieu和Simonovsky 2018年)。超点池化层通过对每个超点内部的逐点平均池化,简单地获得超点特征S∈Rm×C。在不失去一般性的情况下,我们假设从输入点云计算出M个超点。值得注意的是,超点池化层可靠地将输入点云下采样到数百个超点,这显著降低了后续处理的计算开销,并优化了整个网络的表示能力。
Large-scale point cloud semantic segmentation with superpoint graphs.
查询解码器
查询解码器由实例分支和掩码分支组成。在MASK分支中,一个简单的多层感知器旨在提取掩码感知特征SMASK∈Rm×D。实例分支由一系列transformer解码器层组成。它们通过超点交叉注意来解码可学习的查询向量。假设有K个可学习的查询向量。我们预定义了来自各transformer解码层的查询向量的特征为Z∈RK×D,D为嵌入维度,=1,2,3…是层索引。



