点云自监督学习(MAE,持续更新)
PointBERT pipeline(如下图)里的三个问题:
- 需要训练一个基于DGCNN的dVAE用于生成点云的离散词表表示,整个pipeline比较复杂(引入了非Transformer的结构(DGCNN)来辅助Transformer训练)
- 依赖对比学习和数据增强去学习high-level语义特征(本文用调高mask ratio去解决)
- PointBERT对点云做tokenize之后,被mask掉的token是以一个learnable token + positional embedding表示的,再与visible tokens一起输入Transformer Encoder,存在位置信息的泄漏(positional embedding里有mask token的位置信息,降低了reconstruction任务的难度)
![Point-BERT的pipeline。我们首先将输入点云划分为几个点pathes(子云)。然后使用一个迷你点网[34]来获得点嵌入序列。在预训练之前,通过基于dvae的点云重建(如图右图所示)学习Tokenizer,其中点云可以转换为一系列离散的点tokens;在预训练期间,我们对点嵌入的某些部分进行了掩码,并用掩码tokens替换它们。然后将掩蔽点嵌入到transformer中。在Tokenizer获得的点tokens的监督下,训练模型恢复原始点tokens。我们还添加了一个辅助的对比学习任务,以帮助transformer捕获高级语义知识。](/pic/mae1.png)
PointMAE pipeline:
- 采用MAE的pipeline,在Encoder处仅输入visible tokens + visible token的positional embedding,在Decoder处才将visible tokens 和mask tokens 加上full-set的positional embedding 一起输入
- 采用非常高的mask ratio(60%)
- 直接对初始的点云xyz进行预测
- 整体网络仅由Transformer Blocks构成,没有其他结构
- 采用轻量级的decoder(encoder有12个Transformer blocks,decoder只有4个)
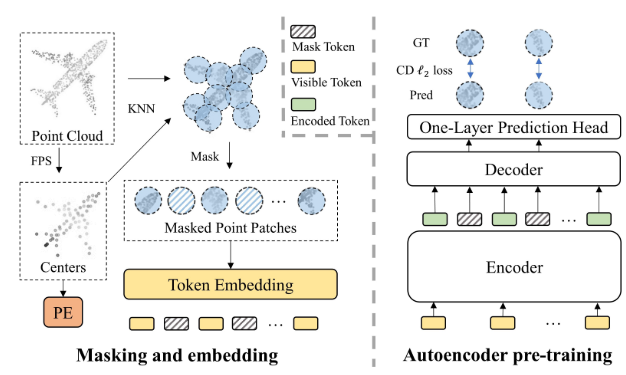
编码器仅处理visible tokens的好处:
- 可以让编码器更好地学习这些point patchs的high-level的语义特征,而不需要学习去区分visible tokens和mask tokens
- 避免了mask tokens的位置信息的泄漏
- 提高了网络的预训练效率(因为采用了高的mask ratio(60%),相当于编码器仅处理40%的tokens,自然就很快啦)
MAE pretrain效率高的原因:
- 编码器仅处理visible tokens
- 解码器虽然要处理全部tokens,但非常轻量级



