室外大规模点云自监督学习理论篇(MAE,持续更新)
一:Voxel-MAE:Masked Autoencoder for Self-Supervised Pre-training on Lidar Point Clouds
二:Occupancy-MAE,原版名为Voxel-MAE(v1~v7)
代码链接
原版Voxel-MAE讲解
Occupancy-MAE讲解
三:MAELi: Masked Autoencoder for Large-Scale LiDAR Point Clouds
第一篇:Voxel-MAE:Masked Autoencoder for Self-Supervised Pre-training on Lidar Point Clouds
摘要
掩码自动编码已经成为文本、图像和最近的点云Transformer模型的成功预训练范例。原始汽车数据集适合用于自我监督预训练,因为与用于3D目标检测(OD)等任务的注释相比,它们的收集成本通常更低。然而,针对点云的掩码自编码器的开发只关注于合成数据和室内数据。因此,现有的方法将其表示和模型定制为具有均匀点密度的小而密集的点云。在这项工作中,我们研究了汽车场景中点云的掩码自动编码,这些点云是稀疏的,并且在同一场景中不同物体之间的点密度可能会发生巨大变化。为此,我们提出了Voxel-MAE,这是一种用于体素表示的简单掩码自动编码预训练方案。我们预训练一个基于Transformer的3D物体检测器的主干来重建掩码体素,并区分空体素和非空体素。在具有挑战性的nuScenes数据集上,我们的方法将3D OD性能提高了1.75个mAP点和1.05个NDS。此外,我们表明,通过使用Voxel-MAE进行预训练,我们只需要40%的注释数据就可以优于随机初始化的等效数据。
引言
自监督学习可以在不需要人工注释的情况下从数据中提取丰富的特征。这开辟了新的途径,可以在更大的数据集上训练模型。在鲁棒表示的推动下,自监督模型在自然语言处理(NLP)[3,12,32]和计算机视觉(CV)[5,8,19]等领域取得了巨大成功。具体来说,掩码语言建模[BERT]和掩码图像建模[BEIT,MAE]已经被证明是简单而有效的预训练策略。这两种方法都训练模型从部分掩码的输入中重建句子或图像。随后,模型可以很好地调整到下游任务,通常比完全监督的等效模型表现得更好。

自动驾驶是一个非常适合自监督预训练策略的应用,包括掩码自动编码。在汽车领域,原始数据的收集相对便宜,而目标检测(OD)、跟踪和语义分割等常见任务的注释则昂贵且耗时。特别是对于3D数据,激光雷达和雷达传感器的稀疏性可能会使标记变得费力甚至模糊。因此,自我监督的预训练是创建鲁棒和通用特征表示的一个有吸引力的替代方案,并最终减少对人工注释数据的需求。
近年来,已有多篇论文将掩码点建模技术应用于点云编码器的预训练。这些方法在形状分类、形状分割、少镜头分类、室内3D OD等下游任务上都取得了良好的效果,表明了掩码自编码器在点云领域的有效性。然而,评估主要集中在ShapeNet和ModelNet40等合成数据,以及ScanObjectNN、ScanNet和SUN RGB-D等室内数据集上。与汽车点云相比,这些数据集包含所有物体的许多点,并且点密度在扫描中通常是恒定的,这使得物体的检测和分类变得不那么具有挑战性。
此外,现有的方法针对数据集特征定制了点云表示和模型选择等设计选择。例如,每个场景更少的点降低了对计算效率的要求,并允许使用普通的transformer。此外,以前的工作完全依赖于最远点采样(FPS)和k近邻(kNN)将点云划分为相同数量点的子集,如图1所示。当点云均匀分布时,这种方法效果很好,并且简化了预训练期间的重建,因为模型为每个子集预测固定数量的点。然而,这种表示对于有效解决汽车领域的下游任务来说是次优的。首先,存在丢弃点的风险,如图1中机翼尖端所示。这种潜在的信息丢失使得它不适合安全关键型应用程序。其次,由于子集可能重叠,表示是冗余的,从而产生不必要的计算负载。
在这项工作中,我们建议在汽车设置中使用掩码点建模。为此,我们提出了VoxelMAE,一种体素化点云的掩码自编码器预训练策略,并将其部署在大规模汽车数据集nuScenes[4]上,研究其对3D OD的影响。体素表示由于能够有效地描述大型点云而被广泛应用于3D OD中,但尚未用于掩码自编码器的预训练。为了在重建过程中捕捉体素的独特性质,我们提出了一组独特的损失函数来同时捕获形状、点密度和缺位点。与PointBERT和POS-BERT等先前的方法相比,我们的方法更简单,因为它不依赖于训练一个单独的标记器来嵌入和重建点云。
继自监督Transformer在NLP和CV中的成功之后,Voxel-MAE利用Transformer主干提取点云特征。之所以选择Transformer架构,是因为在部署广泛掩码时,它的预训练规模更有利,因为只有未掩码的数据被嵌入到编码器中。此外,该模型通过仅处理非空体素来有效地处理稀疏点云。有趣的是,只有少数用于汽车点云的Transformer主干存在,并且它们的自监督预训练之前没有被探索过。
在这项工作中,我们使用单步稀疏Transformer(Single-stride Sparse Transformer, SST)作为我们的点云编码器,它直接对体素化的点云应用移位窗口Transformer,类似于图像的SwinTransformer[26]。SST在3D物体检测方面取得了有竞争力的结果,在计算效率高的同时捕获了精细的细节,使其成为一个强大的基线来改进。对于预训练,我们遵循MAE[19]的范式,并为模型配备一个轻量级的解码器,该解码器在结构上与编码器相似。
综上所述,我们提出以下贡献:
- 我们提出了一种在体素化点云上部署MAE式自监督预训练的方法Voxel-MAE,并在大规模汽车点云数据集nuScenes上对其进行了评估。我们的方法是第一个自监督预训练方案,该方案使用Transformer主干用于汽车点云。
- 我们针对体素表示定制我们的方法,并使用一组独特的重建任务来捕获体素化点云的特征。
- 我们证明了我们的方法是数据高效的,并且减少了对注释数据的需求。通过预训练,我们在仅使用40%的注释数据时优于完全监督的等效方法。
- 此外,我们表明,Voxel-MAE将基于transformer的检测器的性能在mAP中提高了1.75%,在NDS中提高了1.05个百分点,与现有的自监督方法相比,性能提高了2倍。
。被掩码的非空体素和随机选择的空体素使用相同的可学习掩码toke嵌入。然后由解码器处理掩码toke序列和编码的可见体素,以重建掩码点云并区分空体素和非空体素。预训练后,丢弃解码器,将编码器应用于解掩点云。](/pic/mae3d2.png)
相关工作
用于语言和图像的掩码自动编码器。掩码语言建模(MLM)及其衍生工具,如BERT[12]和GPT[3,32,33],在NLP中已经非常成功。这些方法通过掩码输入句子的一部分来学习数据表示,并训练模型来预测缺失的部分。这些方法的可扩展性很好,可以在前所未有的数据集上进行训练,并且它们的表示可以推广到各种下游任务。受其成功的启发,多种方法将类似的技术应用于图像域[2,7,13,19,40]。最近,[19]的作者提出了MAE,这是一种简单的方法,其中随机图像补丁被掩码,并将其像素值作为重建目标。此外,他们部署了非对称编码器-解码器架构,其中编码器只嵌入可见的补丁,并且使用轻量级解码器进行重建。与完全监督的基线相比,MAE在一系列下游任务上的性能得到了提高。Voxel-MAE遵循这一设计理念,对稀疏点云数据进行非平凡的转换。
点云的掩码自动编码器。受MLM在自然语言处理和MAE在计算机视觉上的成功启发,人们提出了对点云域的多种适应。Point-BERT[41]首先引入了BERT风格的点云预训练,掩码和重建部分输入。虽然取得了有竞争力的结果,但他们的方法依赖于训练一个单独的离散变分自动编码器(dVEA)来标记点云补丁,增加了复杂性和对标记器性能的依赖。Point-MAE[31]去除标记器,直接重建点补丁,使用Chamfer距离来测量预测点云与真实点云之间的相似性。与Point-BERT相比,这加快了训练速度,也提高了下游性能。MaskPoint[24]通过去除点云重构进一步加快了预训练。相反,解码器被训练来区分被掩码的点补丁和随机采样的假的空的点补丁。
3D目标检测的自监督学习。虽然户外3D检测可以从自我监督学习中获益良多,但该领域通常尚未得到充分开发。STRL[20]遵循BYOL[18]方法,训练两个点云编码器,在呈现两个时间相关的点云时创建一致的潜在表示。然而,训练两个编码器可能会限制模型的大小,因为在预训练期间内存需求增加。GCC3D[23]通过训练模型应用对比学习,在呈现同一点云的两个增强视图时产生体素方面的相似特征。使用两个后续点云进行预训练,并训练模型以估计帧之间的场景流。这可以看作是掩码自动编码器的一个特殊情况,其中掩码是暂时完成的。然而,他们的方法依赖于一种特殊的交替训练方案,在自我监督和监督训练之间切换。相比之下,我们的方法支持一种更简单的顺序训练策略,首先对模型进行预训练,然后根据需要进行微调。因此,我们避免了每次将模型训练到下游任务时必须处理大型未注释数据集的问题。
方法
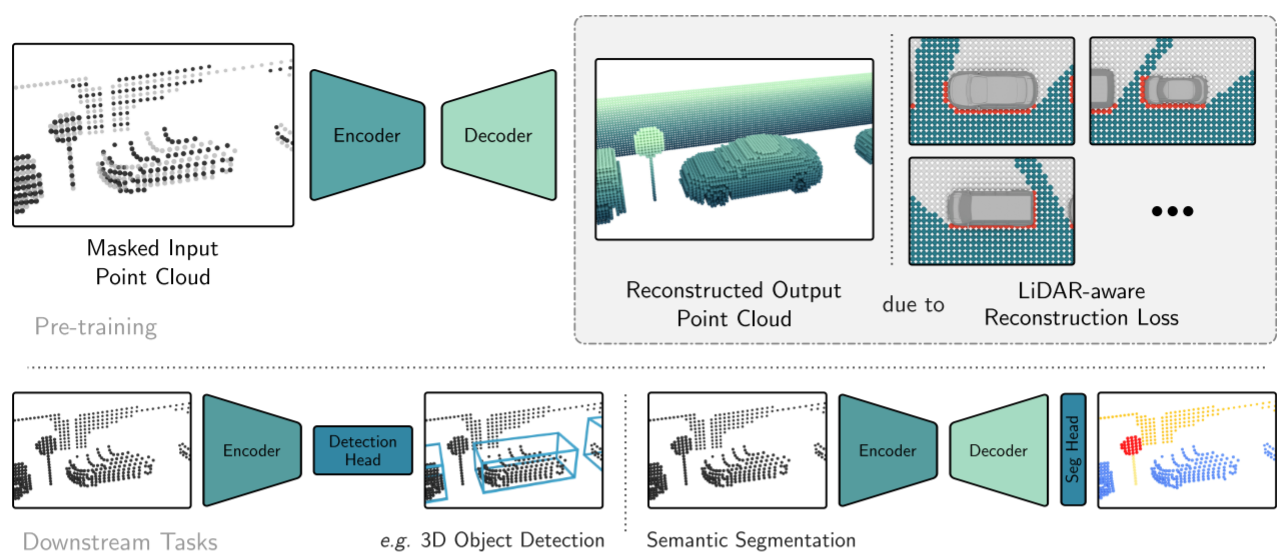
本工作旨在将MAE风格的预训练[19]扩展到体素化点云。核心思想仍然是使用编码器从输入的部分观察中创建丰富的潜在表示,然后使用解码器重建原始输入,如图2所示。经过预训练后,编码器被用作三维目标检测器的主干。但是,由于图像和点云之间的根本差异,需要进行一些修改才能有效地训练Voxel-MAE,如下所述。
掩码和体素嵌入
与将图像划分为不重叠的小块类似,首先将点云划分为体素。体素为不规则的点云带来结构,使高效的处理成为可能,同时为密集的预测任务(如3D OD)保留足够的细节。然而,与图像补丁相比,体素也带来了独特的挑战。
- 首先,由于遮挡和激光雷达数据固有的稀疏性,视场中很大一部分体素通常是空的。而不是使用所有体素,我们丢弃空体素,以避免不必要的计算压力。
- 在预训练中,我们掩码了很大一部分(70%)的非空体素,并用编码器只处理可见体素,进一步提高了计算效率。场景之间不同数量的可见体素通过Transformer的多对多映射巧妙地处理。其次,由于点密度的变化,分配给单个体素的点的数量可以从一个到几百个不等。为了将每个可见体素中的所有点嵌入到单个特征向量中,我们使用动态体素特征编码器MVF。掩码体素被嵌入一个共享的、可学习的掩码token。
编码
对于编码可见体素,我们使用单步稀疏转换器(SST)的编码器[15]。SST是一种基于transformer的3D目标检测器,操作在体素上,可以很容易地将预训练的骨干权重转移到3D OD的下游任务。
- SST编码器是通过堆叠多个Transformer编码器层构建的,其中非空体素被视为单独的token,点云被认为是这些token的序列。此外,每个标记都伴随着基于体素在视场中的位置的位置嵌入。
- 由于自注意机制中的二次复杂度,Transformer对序列长度的扩展能力较差,因此SST引入了区域分组和区域移位。受Swin Transformer[26]中移位窗口的启发,将视场划分为不重叠的3D区域。自注意仅在同一区域内的体素之间计算,与全局自注意相比,大大减少了计算负荷。为了实现来自不同区域的体素之间的交互,每个编码器层都会移动这些区域,并根据新区域对体素进行分组。区域分组和仅处理非空体素的结合限制了使用Voxel-MAE预训练SST的计算空间,特别是在广泛掩码的情况下。
解码
在对可见体素进行编码后,使用解码器利用丰富的潜在表示来重建原始点云。请注意,解码器仅在预训练期间使用,并且在对下游任务的模型进行微调时被丢弃。如图2所示,
- 嵌入体素的序列被掩码体素扩展。它们作为共享的、学习的掩码token以及它们各自的位置嵌入一起嵌入,这样解码器就可以区分它们。
- 除了编码和掩码体素外,我们还添加了一组空的掩码体素,类似于[24]。我们通过在视场中的空体素中随机采样,并以与非空体素相同的方式嵌入它们来实现这一点。增加了空掩码体素,使重建任务更加困难,有效地促进了编码器的学习。通过只处理包含点的体素,模型将具有接近完美的占用知识,从而不必学习点云的这一属性。
- 相反,我们迫使解码器学习区分非空和空掩码体素,并忽略空体素进行重建。根据经验,我们发现采样10%的空体素可以提供良好的性能,而不会引入不必要的计算开销。解码器具有与编码器相似的结构,由SST编码器层组成,但使用较少的层。部分原因可能是预训练所需的时间减少了,但我们也发现,当与较小的解码器一起训练时,编码器可以获得更高的下游任务性能,类似于[19]中的结果。
重建目标
解码器由三个不同的重建任务监督,每个任务监督点云固有的某个特征。对于每个任务,我们对解码器输出应用一个单独的线性层,以将嵌入投影到合适的维度。下面描述了这三个任务及其相应的损失函数。
如前所述,每个体素包含不同数量的点。对于精确的重建,这将要求预测头为每个体素预测不同数量的点。这可以使用递归神经网络来实现,但代价是简单。相反,我们建议预测固定数量的点n,从而可以使用简单的线性层来预测这些点。这种重建是用Chamfer距离来监督的,Chamfer距离测量两组点之间的距离,并允许两组点具有不同的基数。设Pgt = {Pgt i}N i=1为被遮挡点云,该点云被划分为N个体素,其中每个体素Pgt i= {xj}ni j=1包含ni个点,其中ni可以在体素之间变化。类似地,预测的点云Ppre = {Ppre i}N i=1包含N个体素Ppre i= {xj} N j=1,其中所有i的N固定。我们计算每个掩码体素的Chamfer距离,并定义我们的Chamfer损失为
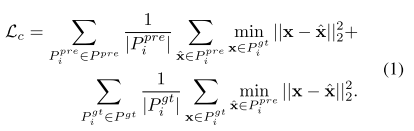
当预测点的数量n超过体素中真实点的数量ni时,该模型仍然可以通过在同一位置放置重复点来最小化Chamfer损失。对于另一种情况,n < ni,研究表明[38],即使在基数不匹配的情况下,Chamfer损失也会促使模型预测捕获真实点云中的细节。
为了进一步明确地学习点云分布的不均匀性,我们还预测了每个非空掩码体素的点数ni。由于目标ni的范围可以从1到几百,我们使用平滑L1损失来监督预测,以避免梯度爆炸
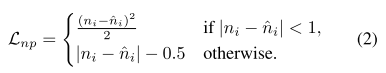
最后,对于每个被掩码体素,我们预测它是空的还是非空的。这个任务是用一个简单的二元交叉熵损失Locc来监督的。预训练的总损失是
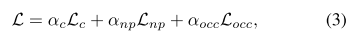
第二篇:Occupancy-MAE: Self-supervised Pre-training Large-scale LiDAR Point Clouds with Masked Occupancy Autoencoders
摘要
当前的自动驾驶感知模型严重依赖于大规模标记的3D数据,这些数据的标注既昂贵又耗时。这项工作提出了一种解决方案,通过使用掩码自动编码器(MAE)对大规模未标记的户外LiDAR点云进行预训练,来减少对标记3D训练数据的依赖。现有的掩码点自动编码方法主要集中在小规模室内点云或基于柱的大规模室外LiDAR数据上,而我们的方法引入了一种新的自监督掩码占用预训练方法,称为Occupancy-MAE,专门针对基于体素的大规模室外LiDAR点云设计。Occupancy-MAE利用了室外LiDAR点云逐渐稀疏的体素占用结构,并结合了距离感知随机掩码策略和占用预测的Pretext Task。通过根据体素与激光雷达的距离随机屏蔽体素,并预测整个3D周围场景的被屏蔽占用结构,Occupancy-MAE鼓励提取高级语义信息,仅使用少量可见体素重建被屏蔽体素。大量的实验证明了Occupancy-MAE在几个下游任务中的有效性。对于3D物体检测,Occupancy-MAE将KITTI数据集上汽车检测所需的标记数据减少了一半,并将Waymo数据集上AP的小物体检测提高了约2%。对于3D语义分割,Occupancy-MAE在mIoU中比从头开始训练高出约2%。对于多目标跟踪,Occupancy-MAE在AMOTA和AMOTP方面从零开始提高了大约1%的训练。
引言
准确的3D感知是自动驾驶的核心技术,它使车辆能够获得关于周围环境的精确信息[1]。KITTI[2]、Waymo[3]、nuScenes[4]和ONCE[5]等大量大型户外激光雷达点云数据集已经发布,展示了无人驾驶车辆环境感知的潜力。然而,为3D物体检测和语义分割等常见任务收集和注释大规模LiDAR点云可能非常耗时和费力。例如,熟练工人每天只能注释大约100-200帧[5]。因此,利用大规模无标注的LiDAR点云进行自监督学习对于提高自动驾驶的感知能力至关重要。它可能为开发下一代强大而稳健的行业级自动驾驶感知模型铺平道路[5]。
近年来,自监督学习取得了重大进展,可以在没有人工注释的情况下对丰富的特征进行预训练。简单的掩码自动编码方法在学习代表性特征方面特别有效,其任务是从未掩码输入中重构掩码数据[7]-[10]。在自然语言处理中,掩码自动编码可以训练大型语言模型,如BERT[7]。同样,在2D视觉中,掩码自动编码优于监督预训练[8]。
近年来,人们提出了一些关于掩码点自动编码的研究成果,如point - mae[11]、point - bert[12]、MaskPoint[13]和point - m2ae[14]。然而,这些方法主要集中在小尺度点云,如合成点云数据集ShapeNet[15]和室内点云数据集ScanNet[16]。相比之下,大规模户外LiDAR点云的掩模自动编码[2]-[5]受到的关注较少。在大规模标记LiDAR点云上从零开始训练仍然是主流方法[5]。为了将掩码自编码的思想引入到大规模户外LiDAR点云的自监督学习中,我们首先识别了与掩码小规模点云自编码相比的挑战[11]-[14],然后提出解决方案:
首先,小尺度点云[15]、[16]与大型室外激光雷达点云[2]-[5]在几个方面有所不同。
- (1)小规模点云通常比大规模点云包含的点要少得多,ShapeNet包含大约2k个点,ScanNet被压缩到大约2k个点,用于掩码小规模点云的自动编码工作[11]-[14]。相比之下,像Velodyne hd - 64e激光雷达这样的激光雷达传感器每帧可以扫描192,000个点,覆盖160×160×20米的区域[17]。
- (2)小尺度点云往往分布均匀,而大尺度激光雷达点云随着距离激光雷达传感器的增加而变得稀疏。
- (3)现有的掩码小尺度点云自动编码工作[11]-[14]通常依靠最远点采样(FPS)和k近邻(kNN)将点划分为相等的子集,不适合大规模户外LiDAR点云。在之前的工作中[17],[18]已经强调了高效、实时地处理这种大规模点云的挑战,这使得对这些数据集的预训练成为一项更具挑战性的任务。
其次,现有的掩模小尺度点云自动编码工作[11]、[12]、[14]主要集中在缺失点的回归上。然而,大规模LiDAR点云的特征并不适合通过回归来重建,因为这些特征包含了必要的空间信息[6]。此外,体素的位置编码可以为解码器提供一条捷径[19]。为了解决这一问题,我们将重点转向大规模激光雷达点云的占用分布,并设计占用预测目标作为pretext task。通过这样做,网络被迫学习具有代表性的特征来恢复3D场景的整体结构,使得这个简单的任务成为我们预训练方法的有效解决方案。
第三,现有的掩模小尺度点云自动编码作品[11]-[14]采用的随机掩模策略,由于大规模户外LiDAR点云分布不均匀,可能不适用于大规模户外LiDAR点云。与小尺度点云不同,大尺度激光雷达点云的密度根据与激光雷达传感器的距离而变化。因此,对所有体素采用统一的随机掩码策略并不是最优的。为了解决这个问题,我们提出了一种大规模激光雷达点云的距离感知随机掩码策略。该策略根据体素与LiDAR传感器的距离调整掩码比,掩码比随着与传感器距离的增加而减小。
Transformer已经开始在处理点云中出现[20]。例如,PCT[21]在整个点云上执行全局自关注,而PointASNL[22]、PointFormer[23]和VoxSet[24]将基于Transformer的架构应用于每个点的局部邻域。然而,这些局部Transformer的效率受到邻域查询和特征重构的限制。SST[25]和FlatFormer[26]采用基于窗口的点云Transformer。这些模型将点云投影到鸟瞰图(BEV)中,并将BEV空间划分为相同空间大小的不重叠窗口。然而,这些方法可能会在纵轴中丢失有价值的信息。我们在编码器中使用3D稀疏卷积[6]和位置编码模块。这使得网络可以专注于可见的3D体素,而不是处理整个点云,从而大大降低了计算成本。位置编码模块,类似于Transformer中使用的位置嵌入,将体素的空间信息编码成固定大小的嵌入向量。
最近,针对大规模户外LiDAR点云,已经提出了几种基于掩模自编码器的自监督预训练算法(如:Voxel-MAE[27]、MV-JAR[28]、GeoMAE[29]、GD-MAE[30])。然而,这些算法是专门为预训练基于柱子的室外LiDAR点云方法SST [25] (SST用Transformer[32]代替Pointpillars[31]骨干,不能处理3D体素)而量身定制的,忽略了点云的关键高度信息。
激光雷达点云中的信息冗余是指点云数据集中存在重复或高度相似的数据点[37],[38]。这种冗余可能来自各种来源[39],[40],如重叠的LiDAR条、多次返回、采样密度、传感器伪影和噪声。重叠点包含相似的地形信息,这些信息可能是冗余的。多次返回通常从不同角度包含关于同一物理特征的信息,从而导致冗余。高采样密度可能导致冗余,因为多个点可能描述相同的地面,特别是在平坦或均匀的区域。这些工件可能导致冗余的数据点,而这些数据点不能代表地面上的实际特征。因此,大量的冗余空间信息仍然隐藏在LiDAR点云中,使它们适合于掩模自动编码方法来学习丰富和代表性的特征。
作为激光雷达点云的压缩表示,占位可以定义为3D网格中的体素是否包含点。在自动驾驶任务中,占用率预测是一种常用的3D世界表示方法[33]。它包括将环境划分为网格,并估计每个单元被占用或空闲的概率。该方法已应用于各种任务,如障碍物检测、路径规划和同步定位和映射(SLAM)[34] -[36]。
F
在上述分析的推动下,我们提出了第一个自监督掩码占用自动编码框架,称为Occupancy-MAE,用于预训练大规模户外激光雷达点云。图2展示了我们的Occupancy-MAE的工作流程,它首先采用距离感知掩码策略来随机掩码体素,然后将未掩码的体素馈送到3D稀疏编码器中。三维解码器的输出是每个体素包含点的概率,我们计算二元占用分类损失来预训练网络。掩码占用分类的pretext task训练鼓励编码器网络对整个物体形状具有体素感知,从而学习3D感知的代表性特征。
![图2所示整体架构。我们首先将大规模不规则LiDAR点云转换为体积表示,根据体素与LiDAR传感器的距离随机掩码(即距离感知掩码策略),然后使用非对称自编码器网络重建一般3D世界的几何占用结构。我们采用以位置编码为编码骨干的3D空间稀疏卷积[6]。我们使用二元占用分类作为pretext task来区分体素是否包含点。预训练后,丢弃轻量级解码器,使用编码器对下游任务的主干进行预热。](/pic/mae3d7.png)
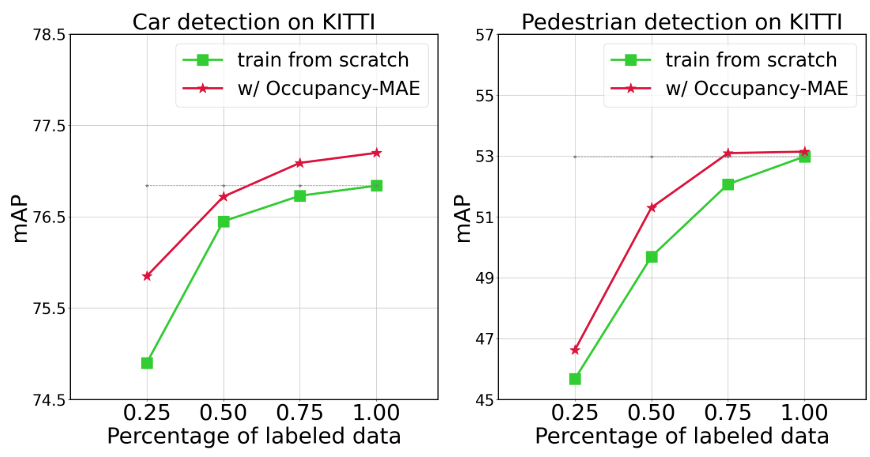
通过对实验结果的分析,我们得出结论,Occupancy-MAE是一个简单有效的自监督学习框架,可以很好地泛化到各种下游任务。在3D目标检测任务中,我们的方法在ONCE数据集上比最先进的自监督学习方法高出0.5% ~ 6% mAP, ONCE数据集是最近发表的用于大规模LiDAR点云自监督学习的数据集。此外,使用Occupancy-MAE进行预训练可以显著提高流行的3D检测器的性能,如SECOND[6]、PV-RCNN[41]、CenterPoint[42]和PV-RCNN[43],这些检测器在KITTI、Waymo和nuScenes数据集上从头开始训练,特别是对于小物体。如图1所示,Occupancy-MAE是一种数据高效学习器,可以用有限的注释3D数据有效地训练大规模LiDAR点云。对于3D语义分割任务,采用双层解码器的Occupancy-MAE可以将从头开始的训练提高约2% mIoU。对于多目标跟踪任务,Occupancy-MAE在AMOTA和AMOTP方面将从零开始的训练提高了约1%。我们还证明了该方法在无监督域适应任务中的有效性,这证实了occuancymae的迁移学习能力。即使掩码率为90%,由于大规模LiDAR点云是信息冗余的,Occupancy-MAE仍然可以学习代表性特征,最终提高了3D感知的性能。
本工作的主要贡献如下:
- 我们提出了一种新的自监督掩码占用自动编码框架,称为Occupancy-MAE,用于预训练大规模户外LiDAR点云,减少了对昂贵的注释3D数据的需求。
- 我们提出了一个3D占用预测pretext task,该任务利用大规模LiDAR点云逐渐稀疏的占用结构。通过从少量可见体素中恢复3D周围世界的掩模占用分布,迫使网络提取高级语义信息。
- 引入距离感知随机掩码策略,利用大规模LiDAR点云密度变化的优势,提高预训练性能。
- 我们提出的Occupancy-MAE在各种下游任务上显著优于从头开始的训练,包括3D目标检测、语义分割、多目标跟踪和无监督域自适应。
相关工作
基于激光雷达的3D感知
基于lidar的三维感知模型具有准确的三维空间信息,已广泛应用于自动驾驶领域[44],[45]。基于lidar的三维目标检测器可分为基于点的[46]、[47]、基于体素的[6]、[31]、[48]和基于点体素的[41]、[49]。基于点的目标检测器利用PointNet从原始点云中提取判别特征[50],并以每个点为中心生成建议,计算成本高。基于体素的检测器将不规则的点云转化为体表示,这将降低细粒度定位的精度。基于点体素的方法利用了点检测器的定位精度和体素检测器的计算效率。基于lidar的三维分割方法分为基于网格的[51]、[52]和基于体素的[18]、[53]。基于网格的方法侧重于将三维点云转换为二维正视图像或距离图像,无法对三维几何信息进行建模。基于体素的方法将点云转换成体积表示。现有的三维感知方法是使用大规模标记的三维数据进行训练的。如何设计自监督学习网络以减少对三维标注的依赖,这方面的研究很少。
Self-supervised学习
近年来,自监督学习(Self-supervised Learning, SSL)作为一种避免昂贵数据注释的有效方法得到了广泛的应用。[54]提出了预测图像斑块相对位置的托辞任务。[55] -[57]的方法设计了旋转预测任务,在学习代表性特征方面显示出良好的效果。在[58]中,引入了一种拼图预测任务,它在目标识别的领域自适应中具有很好的泛化性。DeepCluster[59]和SwAV[60]通过kmeans聚类获得伪标签,并使用这些标签来训练网络。其他方法如Moco[61]、PointContrast[19]、BYOL[62]、ProposalContrast[63]和DepthContrast[64]为自监督学习构建对比视图。最近,MAE[8]通过首先屏蔽输入图像的随机补丁,然后使用简单的自编码器框架重建缺失的像素,在自监督学习中显示出令人鼓舞的结果。VideoMAE[65]将MAE扩展到从视频中学习时空表征,具有更大的信息冗余。ALSO[66]在一个借口任务上训练模型,该任务是重建3D点被采样的表面。ISCC[67]将对比聚类和隐式表面重建应用于自监督预训练大规模室外LiDAR点云。我们的Occupancy-MAE遵循MAE的设计理念,并基于其几何特征(如稀疏性和密度变化)将其应用于大规模户外LiDAR点云。
点云的掩码自动编码器
掩码自编码在NLP[7]和图像[8]中取得了成功,导致了去年点云的掩码自编码技术的发展。point - bert[12]首先引入MAE对小尺度点云进行预训练。point - mae[11]利用Chamfer距离重建小尺度点斑块。MaskPoint[13]设计了用于识别小尺度掩码点补丁的解码器。Point-M2AE[14]将金字塔架构应用于空间几何模型,并捕获3D形状的细粒度和高级语义。然而,这些聚焦于小尺度室内点云的方法,由于场景范围大、密度变化的特点,无法处理大尺度室外激光雷达点云。Voxel-MAE[27]、MV-JAR[28]、GeoMAE[29]和GD-MAE[30]对大规模点云采用掩码自动编码,但仅限于基于柱的方法,会丢失垂直信息。我们提出的Occupancy-MAE克服了这些限制,并能够对体素和基于柱的方法进行大规模LiDAR点云的预训练。
方法
针对大规模LiDAR点云的实例,自监督预训练是利用未标记的数据对网络进行训练,生成具有代表性的特征。受掩码自编码[7],[8],[11]优异性能的启发,我们设计了用于三维感知的掩码占用自编码网络。该算法对体素进行随机掩码,然后利用自编码器网络重构体素的占用值。利用二元交叉熵损失训练占用率预测的pretext task。Occupancy-MAE覆盖大部分骨干网,不包括最后的头部部分。
对于ns未标记的点云数据xi ns i=1,我们的目标是首先预训练掩码自动编码网络以学习高级语义。然后我们使用预训练的模型来预热下游任务的网络。我们还将预训练方法扩展到目标点云xj nt j=1上的域自适应任务。Occupancy-MAE的详细信息列在表1中。解码器仅由两到三个3D反卷积层组成,因此非常轻巧。
![我们的Occupancy-MAE架构的细节,其中包括一个3d编码器和一个3d解码器。3DSparsecvonv和3DTranscvonv分别表示second[45]中提出的三维稀疏卷积层和常见的三维反卷积层。这里我们在kitti数据集上显示预训练秒的输出大小。](/pic/mae3d8.png)
距离感知随机掩码
在这项工作中,我们采用了将LiDAR点云划分为间隔体素的常用方法,该方法经常用于3D感知模型[6],[18]。对于X × Y × Z轴上尺寸为W × H × D的LiDAR点云,每个体素的大小为vW × vH × vD,总共为nl体素,其中每个包含nv点。基于体素的方法比基于点的方法计算效率更高[46],使其非常适合处理自动驾驶汽车等应用中的大规模LiDAR点云。
虽然随机掩码策略已被证明在语言[7]、图像[8]和小规模点云[11]的预训练模型中是有效的,但大规模LiDAR点云的分布是独特的,因为它们的稀疏度水平与与LiDAR传感器的距离相关。靠近传感器的点是密集的,而远离传感器的点则稀疏得多。因此,我们不能对近距离点和远距离点应用相同的掩码策略。相反,我们提出了一种距离感知随机掩码策略,该策略可以掩码一小部分远距离点的数据。
为此,我们引入了考虑距离信息的距离感知随机掩码策略。我们坚持使用常用的距离配置来评估LiDAR点云检测结果[3],[5],根据占用体素与LiDAR传感器的距离将其分为三组:0-30米,30-50米和>50米。掩码比随着距离的增加而减小,我们采用分段的方法对每一组应用随机掩码策略。对应的体素数为nv1、nv2、nv3。我们对每一组采用随机掩码策略,掩码比依次递减为r1、r2、r3(即r1 > r2 > r3)。因此,未遮挡的被占用体素数为nun = nv1(1−r1) nv2(1−r2) nv3(1−r3),体素集Vinput∈Rnun×4作为训练数据。ground truth表示体素的占用状态,T∈{0,1}nl×1。每个体素可以包含点(已占用)或空(空闲)。值为1表示已占用体素,值为0表示空闲体素。
需要注意的是,对于距离感知掩码,也可以使用更多的分割组,但在预训练中会占用大量的预处理时间。因此,我们通过实现三组距离来实现距离感知掩码,从而在精度和速度之间取得平衡。
3D稀疏卷积编码器
用于NLP[7]、2D视觉[8]和小规模点云[11]、[13]的掩码自动编码的Transformer网络对训练数据的未掩码部分进行自关注,这些部分不受掩码的影响。然而,在一个3D场景中有数百万个点,即使在屏蔽了90%的体素之后,仍然有数十万个未被屏蔽的体素,这使得Transformer网络无法从如此庞大的输入数据中聚合信息[7]。一些算法(例如,Voxel-MAE [27], MVJAR[28])利用transformer进行掩码,但它们仅适用于2D柱结构,而忽略了3D高度信息。
为了解决这个问题,提出了3D Sparse Convolution[6],[68]来处理大规模点云。该方法使用位置编码,仅从已占用的体素中聚合信息,从而提高了效率。流行的3D感知方法[6],[18],[41],[42]已经使用该技术开发。基于此,我们采用SECOND[6]中的3D Spatially Sparse Convolution来构建编码器网络,允许我们使用位置编码模块从未被遮挡的、被占用的体素中聚合信息。因此,我们的体素掩码策略降低了训练的记忆复杂性,类似于Transformer网络在NLP[7]、2D视觉[8]和小规模点云[11]-[14]中的工作方式。
轻量级3D解码器
我们的解码器由3D反卷积层组成,最后一层输出每个体素包含点的概率,得到一个输出张量P∈Rnl×1。在预训练期间,解码器的唯一目的是执行占用体素重建。通过将掩码token转移到解码器,我们鼓励编码器为下游任务学习更好的潜在特征。解码器是轻量级的,仅由两到三个3D反卷积层组成,使其可扩展到更大的感知范围。
重构占用目标
大多数掩码自动编码工作的主要目标是通过回归任务重建被掩码部分[11],[12],[14],由于体素的位置编码,这对网络来说并不具有挑战性。然而,在3D感知中,一般3D世界的占用结构在感知模型中起着至关重要的作用[6],[18],[48]。例如,特斯拉推出了用于自动驾驶的占用网络[?]。基于此,我们提出了大规模户外LiDAR点云预训练的占用率预测任务,旨在鼓励网络在高级语义上进行推理,从少量可见体素中恢复被掩码的3D场景占用率分布。由于空体素的大量存在,占用率的预测面临着类不平衡的二元分类挑战。为了解决这个问题,我们使用focal损失进行二元占用分类,使用预测占用值P和地面真实占用体素T。
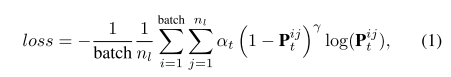
其中Pij表示第i个训练样本中体素j的预测概率,batch表示批大小。正样例/负样例的权重因子α设为2,易样例/难样例的权重因子γ设为0.25。对于第1类,αt = α, Pij t = Pij。对于第0类,αt = 1−α, Pij t = 1−Pij。
与现有掩码激光雷达方法的比较
近年来,针对大规模户外LiDAR点云,提出了几种基于掩码自编码器的自监督预训练算法,包括Voxel-MAE[27]、MV-JAR[28]、GeoMAE[29]和GD-MAE[30]。
我们的方法在四个关键方面不同于这些现有的方法。
- 首先,上述掩码激光雷达方法仅限于基于柱的方法,忽略了点云的关键高度信息,而我们的方法既适用于基于体素的3D物体检测,也适用于基于柱的3D物体检测(如VoxelNet[48]和PointPillars[31]),也适用于3D分割(如Cylinder3D[18])和领域自适应算法(如ST3D[69])。
- 其次,我们引入了距离感知掩码策略,该策略对不同距离的点云进行了不同的处理,考虑了不同的信息密度。
- 第三,由于输入点的位置(x, y, z)可能不适合直接回归LiDAR点云,并且为回归提供了捷径,我们设计了整个周围场景的3D占用预测目标。相反,GeoMAE[29]和MV-JAR[28]使用二维占位预测目标,忽略了沿z轴的关键信息。
- 第四,我们的方法利用了稀疏的三维卷积,使其能够专注于三维体素,并有效地融合了体积信息。
相比之下,上述掩模LiDAR方法使用的是Transformers,它只聚合二维柱特征,而忽略高度信息。
设置
数据集
我们的实验使用了四种流行的自动驾驶数据集:ONCE[5]、KITTI[2]、Waymo[3]和nuScenes[4]。
- ONCE。ONCE数据集[5]包含100万个LiDAR场景和700万个相应的相机图像。这些数据涵盖了不同的地区、时间段和天气条件,提供了真实世界驾驶场景的全面代表。值得注意的是,ONCE数据集的关键目标之一是促进研究,探索利用大规模未标记数据的潜力,为自动驾驶研究和开发的创新方法开辟机会。
- KITTI。KITTI数据集[2]是最流行的自动驾驶数据集之一,它提供了7481个训练样本和7518个测试样本。3D边界框注释仅在前置摄像头的视场(FoV)内提供。我们遵循常见的50/50训练/值分割,并使用官方的KITTI评估指标进行三级评估(简单、中等、困难),并评估平均精度。
- Waymo开放数据集。Waymo开放数据集[3]是最近发布的大规模自动驾驶数据集,该数据集包括798个训练序列,约158361个LiDAR样本,202个验证序列,40077个LiDAR样本。遵循流行的点云检测代码库OpenPCDet[70],我们将所有训练样本中20%的数据(约32k帧)的一帧作为训练集进行子采样。它注释了目标在全360度的领域。Waymo的官方评价指标是难度等级(L1和L2)的平均平均精度(AP)和标题加权的平均平均精度(APH)。
- nuScenes。nuScenes数据集[4]是另一个流行的自动驾驶数据集。总共有28130个训练样本和6019个验证样本。我们使用nuScenes检测分数(NDS)、平均精度(mAP)、平均平移误差(ATE)、平均尺度误差(ASE)、平均方向误差(AOE)、平均速度误差(AVE)、平均属性误差(AAE)等官方评价指标进行评价。
实验设置
我们通过在四个自动驾驶数据集上执行三个下游任务来评估我们提出的模型的有效性[2]-[5]。为了实现3D目标检测和无监督域自适应任务,我们使用了流行的点云检测代码库OpenPCDet70。对于3D语义分割任务,我们使用开源的Cylinder3D[18]作为预训练主干,它应用圆柱形体素划分。我们首先在ONCE数据集的未标记原始集上预训练Occupancy-MAE,然后对训练集上的感知模型进行微调。然而,对于KITTI、Waymo和nuScenes数据集,预训练和微调都在训练集上。ONCE数据集为自监督学习方法提供了一个基准,但没有可用的代码。因此,我们只比较了我们的Occupancy-MAE自监督学习方法在ONCE数据集上的结果。
我们利用预训练的3D编码器来初始化和预热下游任务的骨干,而不会在微调期间冻结3D编码器参数。随后,我们使用与原始模型相同的训练参数训练下游任务。我们将0-30米、30-50米和> 50米的体素掩码率分别设置为90%、70%和50%。预训练epoch的个数为3。更详细的参数设置请参考OpenPCDet[5]、[70]和Cylinder3D[18]。
具体实验结果看原文
第三篇:MAELi: Masked Autoencoder for Large-Scale LiDAR Point Clouds
摘要
大规模激光雷达点云的传感过程不可避免地会产生较大的盲点,即传感器不可见的区域。我们通过设计一个高效的预训练框架来演示如何有效地利用这些固有的采样属性进行自监督表示学习,该框架大大减少了训练最先进目标检测器所需的繁琐的3D注释。我们的Masked AutoEncoder for LiDAR point clouds(MAELi)直观地利用了激光雷达点云在编码器和解码器重建期间的稀疏性。这将产生更具表现力和有用的初始化,可直接应用于下游感知任务,如3D物体检测或自动驾驶的语义分割。在一种新的重建方法中,MAELi区分了空空间和遮挡空间,并采用了一种新的掩码策略,以激光雷达固有的球形投影为目标。因此,在没有任何基础真理的情况下,MAELi仅在单帧上进行训练,从而获得了对底层3D场景几何和语义的理解。为了证明MAELi的潜力,我们以端到端方式对骨干进行预训练,并展示了我们的无监督预训练权重在3d目标检测和语义分割任务上的有效性。
引言
由于最近大规模和精心策划的数据集,如Waymo开放数据集[35],我们见证了在各种各样的3D感知任务中取得的巨大进步,这些任务对自动驾驶至关重要。然而,即使有这样的成本密集型数据集的帮助,模型仍然只能转移到其他领域,同时遭受显著的性能下降[40]。
自监督表示学习(SSRL)提供了一种减少昂贵标记工作的技术。总体思路是以无监督的方式学习通用特征表示,然后用于特定的下游任务,例如目标检测。3D中最常见的方法之一是通过点云重建来学习表征[1,25,30,37,38,41,56]。在那里,任务是恢复点云的删除部分,从而学习对场景和物体几何结构的隐式理解。这对于由CAD模型(如ModelNet[44]或ShapeNet[6])生成的全3D点云尤其有用。最近,这些方法被用于汽车领域的大规模点云[Voxel-MAE,Occupancy-MAE,GeoMAE]。
然而,现有的SSRL方法忽略了激光雷达点云固有的基本特性:
- i)我们无法感知撞击表面以外的物体(即我们只能感知2.5D),
- ii)激光雷达传感器的角度分辨率有限。
在这项工作中,我们适应了这些特性,并提出了MAELi,一种transformer-less掩模自编码器(MAE),它不简单地遵循重建原始LiDAR点云的直接方法。相反,我们提出了一种新的重建方法,使我们能够超越(可见)点。因此,MAELi可以从任何观看方向学习物体的样子,从而获得具有良好泛化能力的强预训练权值。如图1所示,它隐式地学习重建整个目标,同时以一种真正无监督的方式,在没有任何基础真理的情况下,对单个帧进行训练。

直觉上,我们明确区分已占用空间、空白空间和未知空间。当跟踪激光雷达光束从传感器到物体(以及返回)的路径时,中间的空间被认为是空的,物体本身在撞击点占据空间,物体后面的空间由于遮挡而未知。此外,由于激光雷达的分辨率有限,无法对未覆盖的区域做出结论。因此,我们要求我们的模型重建点云的移除部分,但我们不会因为完成未知区域(即遮挡或未采样区域)中的结构而惩罚它。
在训练过程中,模型遇到的目标范围很广,姿态和采样密度不同。尽管缺少标签,但我们独特的目标允许模型重建整个目标,即隐式捕获整个几何结构。在这个过程中,MAELi学习了一种更接近底层几何结构的表示,而不是简单地模仿激光雷达点云中可观察到的特定采样模式。
为了评估,我们选择了最主要的汽车感知任务,即目标检测和语义分割。我们的内存高效,稀疏解码器结构能够在单个GPU上以端到端方式高效地预训练最先进的目标检测器。在Waymo开放数据集[35]、KITTI[2,12,24]和ONCE[26]上的大量实验中,我们证明了MAELi对于预训练各种最先进的3D检测器和语义分割网络是非常有效的。
总之,我们的贡献有三个方面:
- 我们提出了一种激光雷达感知的SSRL方法来预训练适用于各种架构和下游任务的3D骨干网。
- 我们引入了一种新的掩码策略和重建损失,用于无监督表示学习,特别是针对激光雷达特性设计的。
- 我们展示了我们的预训练,视觉可验证表示的有效性,改进了3D物体检测和语义分割的几个基线。
相关工作
2D图像和3D点云的SSRL:自监督表示学习努力在引入人工标记的地面真值数据形式的任何监督之前学习有益的表示。这些表示用于改进各自下游任务的结果或减少标记训练数据所需的数量。
对比学习方法要求模型在使用不同的扩展进行转换时为相同的数据实例维护相似的嵌入。因此,不同的数据实例应该导致不同的嵌入。这些方法最初应用于二维图像[8,16,18,39],也适用于点云[21,23,28,29,31,31,42,46,54,58]。自然地,诱导一致性损失的粒度定义了模型所同意的语义级别。换句话说,在描述整个图像或点云的全局嵌入上的对比学习更适合于分类等下游任务。然而,像目标检测或语义分割这样的任务需要更细粒度的处理。因果困境是在不知道什么是语义连贯的情况下,以适当的细节水平对语义连贯的区域进行采样。例如,Yin等人[54]在去除地平面后,通过最远点采样和球查询生成建议。TARL[29]和STSSL[43]将分析扩展到多个时间框架,以聚类感兴趣的目标,这需要使用全局配准的点云。这个增加的时间维度引入了一个额外的信息层,将它们与基于单帧的方法区分开来。
基于重建的SSRL:最近,生成式自监督表示学习方法正在兴起。它最成功的概念之一是去噪自动编码器。基于编码器的输出嵌入,解码器的任务是重建去噪的输入,如果成功,编码器被迫学习一种有用的抗噪声表示。特别是在不同的应用领域,如自然语言处理(NLP)[11]和2D图像[15]等,对蒙面输入的重建获得了巨大的吸引力。主要的研究重点开始于学习全3D、合成或室内数据集的表示[7,13,19,25,30,38,49,52,56,57],例如ModelNet[44]或ScanNet[10]。
近年来,一些研究工作考虑了激光雷达点云,如[17,27,37,45,48,51]。Xie等人[45]需要充分的监督,而我们不需要任何标签进行预训练。MV-JAR[48]使用主干来重建体素的掩码位置编码和内部点分布,强制网络重建精确的采样模式。在Occupancy-MAE[27]中,作者使用mae方法在没有鸟瞰(BEV)编码器的情况下预训练常见的3D体素骨架,而GDMAE[51]引入了一种新开发的复杂多级transformer。这两种方法都采用密集解码器,并且不区分激光雷达点云中固有的空空间和遮挡空间。相比之下,我们的重建策略与我们的稀疏解码器相结合,使我们能够对最常见的3D物体检测器的整个编码器进行预训练,而不会在单个GPU上的未采样区域进行重建。
只有少数研究考虑了激光雷达点云的固有特性,即其采样分辨率和2.5D感知。在这种情况下,Wang等人[38]在小规模全3D点扫描上合成闭塞,并利用它来预训练编码器。Hu等人[20]通过光线投射生成可见性地图,以减轻不一致的物体增强[50],作为检测网络的额外输入。Xu等人[47]通过分组相似的实例来增强地面真值目标点,并利用它们来训练辅助任务,估计被遮挡区域被目标占用的可能性。GeoMAE[37]提出了一种掩码自编码器,该编码器经过训练后可以重建底层点统计和表面属性,即基于相邻体素的法线和曲率估计。与我们的方法最密切相关的ALSO[3]采用了通过曲面插值的SSRL。它沿着位于探测目标前后的激光雷达光线生成查询点,并指示网络预测这些选定点的占用情况,将遮挡区域视为占用。虽然这种策略很简单,但它可能会抵消自动驾驶汽车上多激光雷达设置的限制,Waymo开放数据集(Open Dataset)中特别使用了这种配置[35]。相比之下,我们的方法能够鲁棒地处理这种复杂的场景,并且可以隐式地学习采样查询点以外的几何结构。一旦网络能够插值下垫面,GeoMAE和ALSO的自我监督任务就被认为是完成的。虽然最终的特征表示已经显示出有希望的结果,但我们的LiDARaware重建展示了进一步的改进,因为我们的模型固有地捕获了整个物体的几何形状。
大规模激光雷达点云MAE
我们的目标是通过自监督表示学习(SSRL)显着减少大规模LiDAR点云的昂贵标记工作。我们建立在成功的掩码和重建范式的基础上,但解决了现有方法主要集中于重建原始输入点云的基本限制。虽然这种策略对于完整的3D模型是有效的,例如由CAD渲染生成的模型[6,44],但它在两个主要方面限制了学习表征对LiDAR点云的有用性:
- 首先,激光雷达传感器的有限角分辨率会导致激光雷达光束之间的间隙。简单地重建原始点云将意味着对这些间隙中(正确地)重建点的模型进行惩罚。
- 其次,单次激光雷达扫描无法完全捕获目标。一旦光束被表面反射,传感器就无法从该表面后面的物体上捕获任何空间信息。
因此,基于标准重建的模型在完成被遮挡的部分时会受到惩罚阻碍了对潜在目标的固有理解和对隐含上下文信息的学习。借助MAELi,我们通过引入激光雷达感知损失来应对这些挑战。这种损失不是均匀地惩罚,而是专门针对激光雷达采样的已知区域。
虽然我们的方法是通用的,可以应用于广泛的任务,但我们选择证明其在3D检测和语义分割方面的有效性,因为它们在该领域的重要性和广泛应用。对于3D检测,我们通过在编码器的最后一层附加一个重建解码器来预训练编码器。一旦预训练完成,我们丢弃解码器并利用编码器的权重作为后续检测任务的初始化。对于语义分割,我们使用编码器和解码器的权重作为下游微调的初始化。图2说明了这一点。
在描述我们的重建目标和掩码策略之前,我们将简要解释我们的稀疏解码器。
稀疏重建解码器
我们的目标是通过为各自的下游任务预训练整个主干来获得更具表现力的特征表示。与现有的稀疏的、基于体素的LiDAR点云编码器/解码器结构(如Part-A2[33])相反,我们必须解决一个关键的区别。典型的方法是通过专用稀疏卷积(SC)对稀疏数据进行体素化和处理。与密集的对等物不同,SC仅在内核覆盖任何活动位点时才应用。即使使用较小的3 × 3内核,这些活性位点也会迅速稀释,从而增加计算工作量。因此,像[32,50,55]这样的方法使用子流形稀疏卷积(submanifold sparse convolutions, SSC)[14],其中内核中心只放置在活动位点上,只考虑内核覆盖的活动位点,同时保持有利的内存消耗。解码器然后在上采样期间重用各自编码器层的活动位点。然而,这使得常见的上采样模式对于重建编码器中不存在的体素无效,使其不适合重建任务。
为了在点云上执行重建,我们需要一个解码器,它也可以恢复被删除的体素,并扩展到编码器中存在的活动站点之外。对原始空间分辨率进行密集上采样是可能的,但由于内存和计算需求过大,在有限的硬件设置上预训练较大的架构是相当不切实际的。因此,我们允许每个上采样层(立方)增长,但添加一个学习删除冗余体素的后续修剪层,如图3所示。为此,我们利用小尺度点云重建的思想[9],对学习修剪的稀疏特征映射应用1 × 1卷积。这样,解码器能够重建和完成点云的部分,而修剪层去除多余的体素。为了获得更强的特征表示,我们提出了一个扩展的重建目标。

重建目标
我们制定了重建目标,以更深入地了解潜在的环境结构。直观地说,模型应该更直接地掌握汽车的完整外观,而不仅仅是重建激光雷达光束捕获的特定点。此外,预训练的表示应该更紧密地与下游任务的目标保持一致,例如,在整个汽车周围安装一个3D边界框。因此,在解码器内的重建过程中,我们区分了三种体素:已占用体素、空体素和未知体素。这些类别如图4所示。
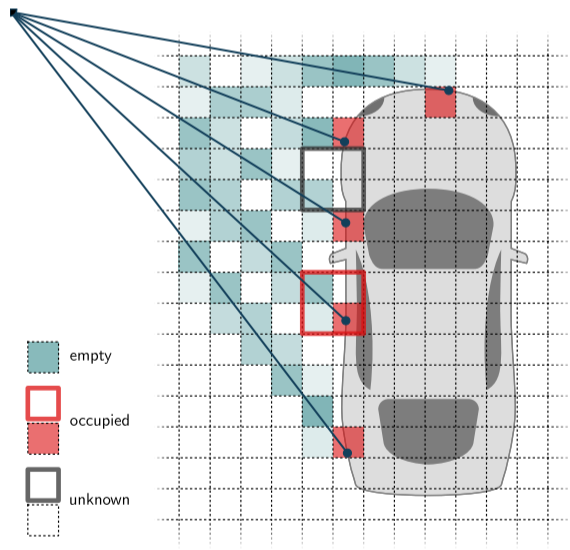
被占用的体素包含来自原始点云的表面点(在掩码之前),因此应该是重建的一部分。空体素是激光雷达光束穿过而没有击中任何表面的体素,因此应该保持为空。最后,如果前两种情况都不适用,我们将体素分类为未知,即这些体素要么被遮挡,要么由于有限的角度分辨率而未被光束感知。这种分类使重建能够超越最初感知的点云。直观地说,这是有道理的,因为惩罚网络重构未采样的点是适得其反的,即使它们是底层物体的一部分。
我们观察到离散体素化会导致不精确,特别是在低分辨率体素网格下。为了减轻这种情况,我们通过从体素中心到最近激光雷达光束的垂直距离ds i来减少空体素的损失。更正式地说,我们将体素的权重定义为:
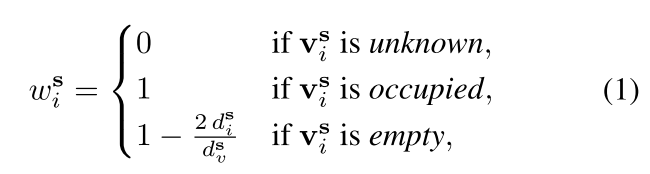
其中ds v表示步长s处体素对角线的长度。请注意,使用多个LiDAR(例如Waymo[35])的设置可以通过迭代每个LiDAR的分类过程来简单地处理。在那里,由于额外的激光雷达传感器,未知体素的数量将会减少。
我们需要对低分辨率和大跨步的体素分别进行相同的分类。例如,步长为s的体素在空间上覆盖步长为s/2的8个体素(见图3)。但是,这里需要考虑的是,如果对低分辨率体素进行剪枝,那么在上采样过程中,低分辨率体素将不再对其高分辨率体素产生自监督信号。因此,如果一个低分辨率体素包含了任何高分辨率的被占用体素(图4中的红色方块),那么这个低分辨率体素就被认为是被占用的。同样,如果它包含了任何未知的体素,但没有被占用的体素,那么这个低分辨率体素就是未知的(灰色方块)。否则,低分辨率体素将被归类为空。
综上所述,自监督预训练的目标是正确分类一个体素是被占用还是空的,同时不惩罚未知的体素。为此,我们使用加权二值交叉熵损失:
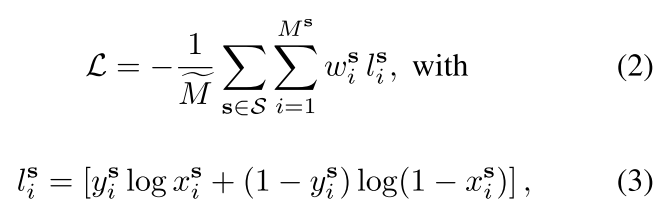
式子中S为所有步幅的集合,M为解码器中所有被占用和空的体素;ys i为体素化输入点云的实际占用,即vs I被占用时为1,否则为0;x1是模型预测的占用率。换句话说,我们对移除被占用的和保留空体素的每个修剪步骤进行惩罚,但我们不会对未知体素造成任何损失。、
掩码策略
在应用于小尺度全3D点云的方法中,一种常见的掩码策略是应用最远点采样(FPS)和k最近邻算法来创建重叠的补丁[30,56],然后随机移除。然而,将FPS应用于LiDAR点云将主要选择孤立的点,这些点通常是遥远的单个异常值。掩码这些对学习强特征表示没有好处,因为这些离群点通常不对应于真实场景结构,并且只有很少的邻近点。相反,我们利用已经存在的体素化步骤并随机掩码体素。
此外,考虑到标准旋转激光雷达传感器的采样分辨率:它发出多个光束,等待它们返回,然后从经过的时间中得出与击中障碍物的距离,即距离。每个光束都有一个倾角,并围绕一个共同的垂直轴旋转,从而定义了一个方位角。由于两个特定的光束围成一个恒定的角度,因此空间分辨率和点的数量随着与被击中物体的距离而减少。考虑通过点云重建的SSRL,随着距离传感器距离的增加,自监督越少。
直观地说,如果我们从附近的区域移除点,使它们看起来与更远的稀疏区域相似,那么模型应该能够更好地推广到这些区域。我们通过降低方位角和倾角的角分辨率来结合这种球形掩码思想。为了有效地做到这一点,我们对激光雷达的距离图像进行子采样。具体地说,我们随机抽取两个整数1≤mr,mc≤4,并分别过滤范围图像中r mod mr≤0或c mod mc≤0的所有行r和列c。例如,每隔一秒使用一行和一列会使角分辨率减半。通过这种方式,一个物体被采样,就好像它在更远的地方一样,但我们能够在重建任务中诱导出更强的自我监督信号。
实验
我们通过关注汽车感知中的关键任务,即目标检测和语义分割来演示我们的MAELi预训练。为了验证我们的方法,我们采用了一系列架构,并在这些领域中广泛认可的数据集上对它们进行预训练。具体来说,我们使用了Waymo开放数据集[35]、KITTI[2、12、24]和ONCE[26]数据集。
我们与最先进的方法进行比较,除非另有说明,否则我们报告其官方结果,这些结果来自官方基准或相应的出版物。补充材料中提供了一个额外的消融研究,以分离我们方法中各种成分的贡献。
**实现细节:**我们将MAELi集成到OpenPCDet[36]框架(v0.5.2)中,并使用Minkowski引擎[9]来设计我们的稀疏解码器。对于KITTI, Waymo和ONCE,我们分别使用[0.05,0.05,0.1],[0.1,0.1,0.15]和[0.1,0.1,0.2]的体素大小。给定各自的架构和数据集,我们预训练了30个epoch,没有任何标记的ground truth。我们使用Adam[22]和一个单周期策略[34],最大学习率为0.003。我们在一台NVIDIA®Quadro RTX™8000上进行了所有实验。
3D目标检测
我们的预训练方法MAELi非常适合3D物体检测器,因为我们的损失公式让模型学习物体应该是什么样子。这些预训练的权重可以很好地泛化数据集,并允许检测器在目标数据集上进行有效的数据微调。
对于3D检测,我们设计了一个具有四个blocks的稀疏解码器,每个block反转编码器的一次下采样操作(确切的架构在补充材料中)。我们预训练整个编码器,包括密集的BEV主干[50]。因此,为了利用解码器的稀疏处理能力,我们从稀疏3D编码器的最后一层提取活动体素,并从BEV特征图中采样。为了使用预训练的权重微调不同的3D检测器,我们通过冻结编码器一个epoch来预热检测头,并根据默认的OpenPCDet配置进行端到端训练。
OpenPCDet提供了几种增强技术,即随机翻转/旋转/缩放和地面真值采样[50]。在预训练期间,我们利用随机翻转/旋转/缩放除了我们的掩蔽策略。对于微调,我们在数据效率实验中,除了地面真值采样[50]外,都是按原样使用。我们不能在这里应用它的普通形式,因为它在整个数据集中采样地面真实对象,并将这些随机复制粘贴到只包含少量对象的帧中。如果不进行更改,这将添加来自我们的次采样帧以外的真实对象,从而使这些研究无效。因此,我们过滤原始的ground truth数据库,并确保它只包含来自实际使用的帧的对象。
检测结果:
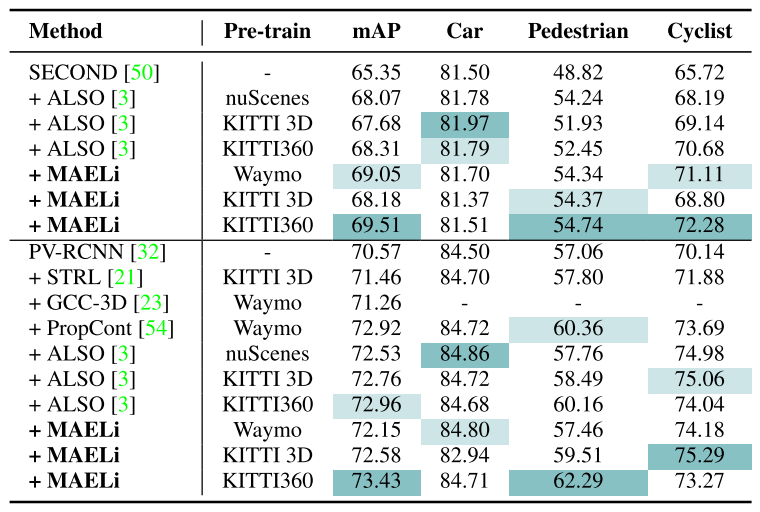
KITTI 3D数据集和基准[12]是第一个公开可用的3D物体检测数据集之一,由~ 7.5k激光雷达帧组成,这些帧在前置摄像头视图中被标记。KITTI360[24]是原始KITTI数据集的扩展,包含约80k激光雷达帧,提供额外的模态和更详尽的注释。为了与其他预训练方法进行比较,我们使用来自KITTI 3D、KITTI360和Waymo的预训练权值,展示了KITTI 3D集上的检测结果。在我们的实验中,我们报告了基于中等难度水平的评估指标,利用具有40个召回点的官方R40指标。
表1显示了广泛使用的SECOND[50]和PV-RCNN[32]检测器在使用不同预训练权值时的检测性能。在所有用于预训练的数据集中,MAELi能够对从头开始训练的检测模型进行强大的改进,并产生最佳性能的检测结果。特别是,我们在整体mAP上优于当前最先进的产品,即ALSO,而汽车类别的性能差异仍然在非常窄的范围内,这表明该类别的性能已经饱和。
**大规模的Waymo开放数据集[35]**包含798个训练序列和202个验证序列。为车辆、行人和骑自行车的人提供标签。我们使用Waymo官方评估协议报告我们的结果,在更具挑战性的LEVEL 2难度下报告APH。包括AP分数在内的详细结果在补充材料中提供。
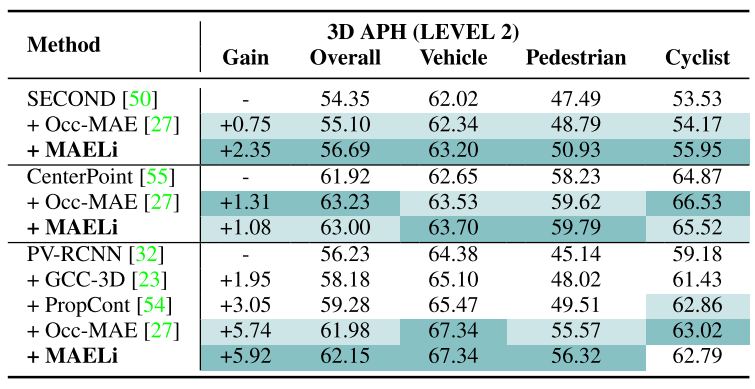
我们在Waymo训练集上预训练我们的权值,并使用它们初始化SECOND[50]、CenterPoint[55]和PV-RCNN[32]的主干。为了与[27,54]进行公平的比较,我们遵循通用协议,使用整个Waymo训练集的20%(包括vanilla ground truth sampling)来微调检测器。
表2显示了Waymo与预训练方法Occupancy-MAE[27]、GCC3D[23]和ProposalContrast[54]的对比结果。使用MAELi进行预训练表明,在所有检测器上都有很大的改进。虽然MAELi预训练的权重显然比Occupancy-MAE更适合SECOND,但CenterPoint和PV-RCNN的结果与Occupancy-MAE相当,明显优于GCC-3D或ProposalContrast。
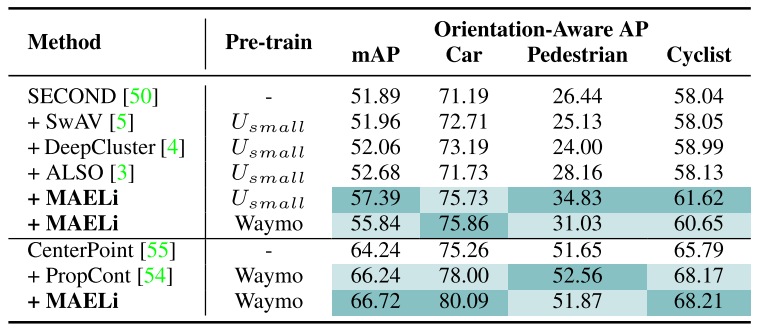
ONCE[26]是一个综合性的数据集,专为诸如3D物体检测、跟踪和运动预测等任务而设计。该数据集包括100万帧,其中大部分是未标记的。ONCE的主要目标是为利用大规模未标记数据的研究奠定基础。在我们的工作中,我们利用官方的Usmall子集进行预训练,随后在训练集上微调我们的模型,并在验证集上进行评估。
表3给出了MAELi与其他预训练方法在ONCE上的对比结果。除了我们的良好结果之外,该评估还证明了我们的预训练方法具有强大的跨域泛化能力:对于SECOND[50],即使使用来自Waymo的预训练权值,我们的表现也优于当前的方法,即55.84 mAP (MAELi在Waymo上预训练)和52.68 mAP(同样在Usmall上预训练)。当然,对ONCE本身进行预训练会进一步改善结果。
其他实验结果请看原文



