室外大规模点云自监督学习代码篇(Occupancy-MAE)
Occupancy-MAE,原版名为Voxel-MAE(v1~v7)
Occupancy-MAE: Self-supervised Pre-training Large-scale LiDAR Point Clouds with Masked Occupancy Autoencoders(代码)
本工作的主要贡献如下:
- 提出了一种新的自监督掩码占用自动编码框架,称为Occupancy-MAE,用于预训练大规模户外LiDAR点云,减少了对昂贵的注释3D数据的需求。
- 提出了一个3D占用预测pretext task,该任务利用大规模LiDAR点云逐渐稀疏的占用结构。通过从少量可见体素中恢复3D周围世界的掩模占用分布,迫使网络提取高级语义信息。
- 引入距离感知随机掩码策略,利用大规模LiDAR点云密度变化的优势,提高预训练性能。
- 提出的Occupancy-MAE在各种下游任务上显著优于从头开始的训练,包括3D目标检测、语义分割、多目标跟踪和无监督域自适应。
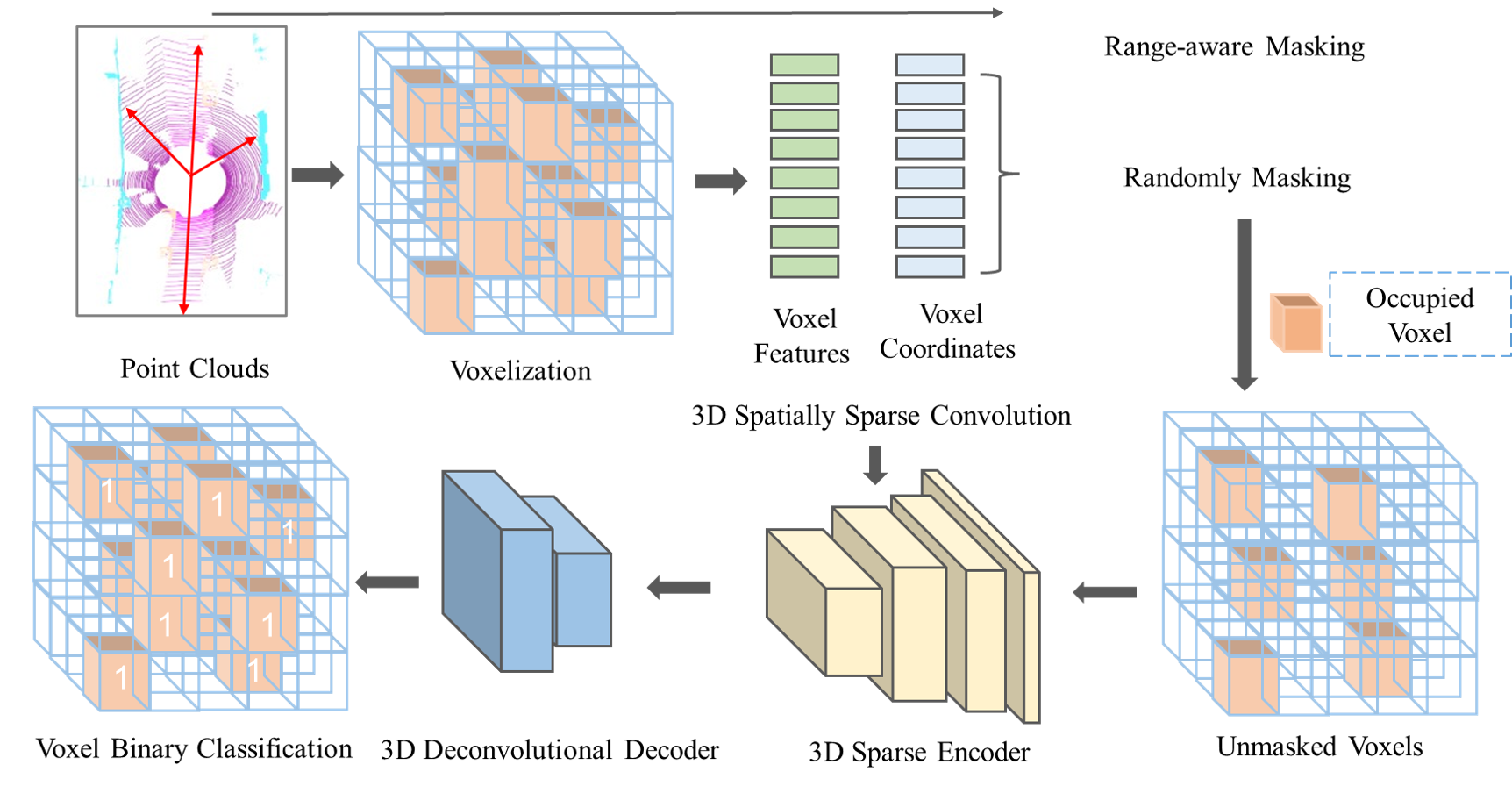
![整体架构。首先将大规模不规则LiDAR点云转换为体积表示,根据体素与LiDAR传感器的距离随机掩码(即距离感知掩码策略),然后使用非对称自编码器网络重建一般3D世界的几何占用结构。采用以位置编码为编码骨干的3D空间稀疏卷积[6]。使用二元占用分类作为pretext task来区分体素是否包含点。预训练后,丢弃轻量级解码器,使用编码器对下游任务的主干进行预热。](/pic/mae3d7.png)
代码介绍
网络依托OpenPCDet(v0.5)进行构建
OpenPCDet 是一个清晰、简单、独立的开源项目,用于基于 LiDAR 的 3D 物体检测。同时也是[PointRCNN]、[Part-A2-Net]、[PV-RCNN]、[Voxel R-CNN]、[PV-RCNN++]和[MPPNet]的官方代码发布。
配置文件保存在tools/cfgs目录下,不同的数据集设置了不同的配置(主要看携带mae的配置文件):
tools/cfgs
├── dataset_configs
│ ├── kitti_dataset.yaml
│ ├── lyft_dataset.yaml
│ ├── nuscenes_dataset.yaml
│ ├── pandaset_dataset.yaml
│ └── waymo_dataset.yaml
├── kitti_models
│ ├── CaDDN.yaml
│ ├── PartA2_free.yaml
│ ├── PartA2.yaml
│ ├── pointpillar_newaugs.yaml
│ ├── pointpillar_pyramid_aug.yaml
│ ├── pointpillar.yaml
│ ├── pointrcnn_iou.yaml
│ ├── pointrcnn.yaml
│ ├── pv_rcnn.yaml
│ ├── second_iou.yaml
│ ├── second_multihead.yaml
│ ├── second.yaml
│ ├── voxel_mae_kitti.yaml
│ └── voxel_rcnn_car.yaml
├── lyft_models
│ ├── cbgs_second_multihead.yaml
│ └── cbgs_second-nores_multihead.yaml
├── nuscenes_models
│ ├── cbgs_dyn_pp_centerpoint.yaml
│ ├── cbgs_pp_multihead.yaml
│ ├── cbgs_second_multihead.yaml
│ ├── cbgs_voxel0075_res3d_centerpoint.yaml
│ ├── cbgs_voxel01_res3d_centerpoint.yaml
│ └── voxel_mae_res_nuscenes.yaml
└── waymo_models
├── centerpoint_dyn_pillar_1x.yaml
├── centerpoint_pillar_1x.yaml
├── centerpoint_without_resnet.yaml
├── centerpoint.yaml
├── PartA2.yaml
├── pointpillar_1x.yaml
├── pv_rcnn_plusplus_resnet.yaml
├── pv_rcnn_plusplus.yaml
├── pv_rcnn_with_centerhead_rpn.yaml
├── pv_rcnn.yaml
├── second.yaml
├── voxel_mae_waymo.yaml
└── voxel_rcnn_with_centerhead_dyn_voxel.yaml下面将以kitti数据集上的配置代码撸一遍流程
**以kitti数据集为例,它的配置文件是cfgs/dataset_configs/kitti_dataset.yaml**:
这是一个用于配置KITTI数据集处理的配置文件。以下是主要部分的解释:
DATASET: 数据集的名称,指定为’KittiDataset’。
DATA_PATH: 数据集的路径,指定为’../data/kitti’。
POINT_CLOUD_RANGE: 点云的范围,指定为
[0, -40, -3, 70.4, 40, 1]。DATA_SPLIT: 数据集的划分,包含’train’和’test’两个子集。
INFO_PATH: 数据集信息的路径,分别指定了’train’和’test’子集的信息文件。
GET_ITEM_LIST: 获取数据项的列表,包括”points”。
FOV_POINTS_ONLY: 是否仅使用视场内的点,指定为True。
DATA_AUGMENTOR: 数据增强的配置,包括禁用的增强、增强配置列表等。
DISABLE_AUG_LIST: 禁用的数据增强,包括’placeholder’。
AUG_CONFIG_LIST: 数据增强的配置列表,包括gt_sampling、random_world_flip、random_world_rotation和random_world_scaling。
POINT_FEATURE_ENCODING: 点特征的编码配置,采用绝对坐标编码,包括使用的特征列表等。
DATA_PROCESSOR: 数据处理的配置,包括mask_points_and_boxes_outside_range、shuffle_points和transform_points_to_voxels。
mask_points_and_boxes_outside_range: 在范围之外屏蔽点和框。
shuffle_points: 随机打乱点的顺序,指定在训练和测试阶段是否启用。
transform_points_to_voxels: 将点转换为体素的配置,包括体素大小、最大点数等。
这个配置文件定义了KITTI数据集的加载、处理和增强流程,以及训练和测试阶段的一些设置。配置文件中的每个部分都用于指导数据流程的一个方面。
配置文件以voxel_mae_kitti.yaml为例:
CLASS_NAMES: ['Car', 'Pedestrian', 'Cyclist']
DATA_CONFIG:
_BASE_CONFIG_: cfgs/dataset_configs/kitti_dataset.yaml
MODEL:
NAME: Voxel_MAE
VFE:
NAME: MeanVFE
BACKBONE_3D:
NAME: Voxel_MAE
MASKED_RATIO: 0.5 # masked_ratio for Voxel_MAE
OPTIMIZATION:
BATCH_SIZE_PER_GPU: 4
NUM_EPOCHS: 30
OPTIMIZER: adam_onecycle
LR: 0.003
WEIGHT_DECAY: 0.01
MOMENTUM: 0.9
MOMS: [0.95, 0.85]
PCT_START: 0.4
DIV_FACTOR: 10
DECAY_STEP_LIST: [35, 45]
LR_DECAY: 0.1
LR_CLIP: 0.0000001
LR_WARMUP: False
WARMUP_EPOCH: 1
GRAD_NORM_CLIP: 10
这是一个用于配置模型、优化器和训练过程的配置文件。以下是主要部分的解释:
CLASS_NAMES: 数据集中的类别名称,包括’Car’, ‘Pedestrian’, ‘Cyclist’。
DATA_CONFIG: 数据集的配置,包括基础配置文件的引用。
- BASE_CONFIG: 数据集配置的基础配置文件,指定为’cfgs/dataset_configs/kitti_dataset.yaml’。
MODEL: 模型的配置。
NAME: 模型的名称,指定为’Voxel_MAE’。
VFE: 体素特征编码器的配置,包括名称为’MeanVFE’的体素特征编码器。
BACKBONE_3D: 3D主干网络结构的配置,包括名称为’Voxel_MAE’的结构和’MASKED_RATIO’的设置。
OPTIMIZATION: 优化器和训练过程的配置。
BATCH_SIZE_PER_GPU: 每个GPU的批量大小,设置为4。
NUM_EPOCHS: 训练的总时期数,设置为30。
OPTIMIZER: 优化器的名称,设置为’adam_onecycle’。
LR: 学习率,设置为0.003。
WEIGHT_DECAY: 权重衰减,设置为0.01。
MOMENTUM: 动量,设置为0.9。
MOMS: 动量的配置,包括[0.95, 0.85]。
PCT_START: OneCycleLR学习率策略的初始学习率占总时期数的百分比,设置为0.4。
DIV_FACTOR: OneCycleLR学习率策略的学习率最大值和最小值的比例,设置为10。
DECAY_STEP_LIST: 学习率衰减的时期列表,设置为[35, 45]。
LR_DECAY: 学习率衰减因子,设置为0.1。
LR_CLIP: 学习率的下限,设置为0.0000001。
LR_WARMUP: 是否进行学习率预热,设置为False。
WARMUP_EPOCH: 学习率预热的时期数,设置为1。
GRAD_NORM_CLIP: 梯度范数的裁剪值,设置为10。
这个配置文件定义了模型的结构、优化器的选择以及训练的各种参数。每个部分都用于指导模型训练的一个方面。
主干网络包含如下这些,其中我们主要使用Voxel_MAE:
from .detector3d_template import Detector3DTemplate
from .PartA2_net import PartA2Net
from .point_rcnn import PointRCNN
from .pointpillar import PointPillar
from .pv_rcnn import PVRCNN
from .second_net import SECONDNet
from .second_net_iou import SECONDNetIoU
from .caddn import CaDDN
from .voxel_rcnn import VoxelRCNN
from .centerpoint import CenterPoint
from .pv_rcnn_plusplus import PVRCNNPlusPlus
from .detector3d_template_voxel_mae import Detector3DTemplate_voxel_mae
from .voxel_mae_net import Voxel_MAE
__all__ = {
'Detector3DTemplate': Detector3DTemplate,
'SECONDNet': SECONDNet,
'PartA2Net': PartA2Net,
'PVRCNN': PVRCNN,
'PointPillar': PointPillar,
'PointRCNN': PointRCNN,
'SECONDNetIoU': SECONDNetIoU,
'CaDDN': CaDDN,
'VoxelRCNN': VoxelRCNN,
'CenterPoint': CenterPoint,
'PVRCNNPlusPlus': PVRCNNPlusPlus,
'Detector3DTemplate_voxel_mae': Detector3DTemplate_voxel_mae,
'Voxel_MAE': Voxel_MAE
}
def build_detector(model_cfg, num_class, dataset):
model = __all__[model_cfg.NAME](
model_cfg=model_cfg, num_class=num_class, dataset=dataset
)
return model
voxel_mae_net.py代码如下,继承Detector3DTemplate_voxel_mae,这里主要讲了如何配置主干网络,其中维护了一个model_info_dict字典
class Detector3DTemplate_voxel_mae(nn.Module):#部分代码
def __init__(self, model_cfg, num_class, dataset):
super().__init__()
self.model_cfg = model_cfg
self.num_class = num_class
self.dataset = dataset
self.class_names = dataset.class_names
self.register_buffer('global_step', torch.LongTensor(1).zero_())
self.module_topology = [
'vfe', 'backbone_3d'
]
@property
def mode(self):
return 'TRAIN' if self.training else 'TEST'
def update_global_step(self):
self.global_step += 1
def build_networks(self):
model_info_dict = {
'module_list': [],
'num_rawpoint_features': self.dataset.point_feature_encoder.num_point_features,
'num_point_features': self.dataset.point_feature_encoder.num_point_features,
'grid_size': self.dataset.grid_size,
'point_cloud_range': self.dataset.point_cloud_range,
'voxel_size': self.dataset.voxel_size,
'depth_downsample_factor': self.dataset.depth_downsample_factor
}
for module_name in self.module_topology:
"""
使用 getattr 函数从当前对象 self 中获取这个方法。getattr 接受一个对象和一个字符串作为参数,返回对象的属性或方法。
调用获取到的方法,并传递 model_info_dict=model_info_dict 作为参数。这样,构建方法就可以更新 model_info_dict,并返回构建的模块。
"""
module, model_info_dict = getattr(self, 'build_%s' % module_name)(
model_info_dict=model_info_dict
)
#将构建的模块 module 添加到当前对象 self 中,并为它指定一个名称 module_name。
self.add_module(module_name, module)
return model_info_dict['module_list']from .detector3d_template_voxel_mae import Detector3DTemplate_voxel_mae
class Voxel_MAE(Detector3DTemplate_voxel_mae):
def __init__(self, model_cfg, num_class, dataset):
super().__init__(model_cfg=model_cfg, num_class=num_class, dataset=dataset)
self.module_list = self.build_networks()
def forward(self, batch_dict):
for cur_module in self.module_list:
batch_dict = cur_module(batch_dict)
if self.training:
loss, tb_dict, disp_dict = self.get_training_loss()
ret_dict = {
'loss': loss
}
return ret_dict, tb_dict, disp_dict
else:
pred_dicts, recall_dicts = self.post_processing(batch_dict)
return pred_dicts, recall_dicts
def get_training_loss(self):
disp_dict = {}
loss_rpn, tb_dict = self.backbone_3d.get_loss()
tb_dict = {
'loss_rpn': loss_rpn.item(),
**tb_dict
}
loss = loss_rpn
return loss, tb_dict, disp_dict
这里主要看BACKBONE_3D,具体包括这些:
from .pointnet2_backbone import PointNet2Backbone, PointNet2MSG
from .spconv_backbone import VoxelBackBone8x, VoxelResBackBone8x
from .spconv_unet import UNetV2
from .voxel_mae import Voxel_MAE
from .voxel_mae_res import Voxel_MAE_res
__all__ = {
'VoxelBackBone8x': VoxelBackBone8x,
'UNetV2': UNetV2,
'Voxel_MAE': Voxel_MAE,
'Voxel_MAE_res': Voxel_MAE_res,
'PointNet2Backbone': PointNet2Backbone,
'PointNet2MSG': PointNet2MSG,
'VoxelResBackBone8x': VoxelResBackBone8x,
}
核心部分,先看Voxel_MAE.py
这段代码定义了一个名为 Voxel_MAE 的 PyTorch 模型。以下是对代码的一些主要解释:
SparseBasicBlock 类:这是一个基本的稀疏块,用于构建深度神经网络。它继承自
spconv.SparseModule,其中包含了一系列稀疏卷积、批量归一化和激活函数的层。该类被用作 Voxel_MAE 模型中的基本构建块。Voxel_MAE 类:这是主要的模型类。以下是该类的一些关键部分:
初始化方法:模型的初始化方法定义了网络的结构,包括一系列的稀疏卷积层 (
SparseSequential和SparseConv3d)、归一化层 (BatchNorm1d和BatchNorm3d)、激活函数 (ReLU) 以及转置卷积层 (ConvTranspose3d)。模型的结构主要包括四个卷积阶段 (conv1到conv4),每个阶段都包含了多个基本块 (SparseBasicBlock)。前向传播方法:
forward方法实现了模型的前向传播过程。在前向传播中,输入的点云数据首先通过一系列的稀疏卷积层,然后经过转置卷积层进行上采样。同时,根据模型配置,选择性地对输入进行掩码操作。最终,模型输出包括预测的稀疏张量和与输入相对应的目标。get_loss 方法:用于计算模型的损失。在这里,使用二进制交叉熵损失 (
BCEWithLogitsLoss) 计算预测值与目标值之间的差异。
总体而言,这段代码实现了一个处理稀疏点云数据的神经网络模型,其中使用了稀疏卷积和转置卷积层,以及一些基本的块来构建网络结构。
以下是 Voxel_MAE 模型的前向传播方法的逐行介绍:
def forward(self, batch_dict):
"""
Args:
batch_dict:
batch_size: int
vfe_features: (num_voxels, C)
voxel_coords: (num_voxels, 4), [batch_idx, z_idx, y_idx, x_idx]
Returns:
batch_dict:
encoded_spconv_tensor: sparse tensor
point_features: (N, C)
"""这个前向传播方法接受一个 batch_dict 参数,其中包含了输入数据的一些关键信息,如批大小、体素特征 (vfe_features) 和体素坐标 (voxel_coords)。返回一个更新后的 batch_dict,其中包含了编码的稀疏卷积张量 (encoded_spconv_tensor) 和点特征 (point_features)。
voxel_features, voxel_coords = batch_dict['voxel_features'], batch_dict['voxel_coords']从输入的 batch_dict 中提取体素特征和体素坐标。
select_ratio = 1 - self.masked_ratio # ratio for select voxel计算用于选择体素的比率,即 1 减去模型配置中指定的 masked_ratio。
voxel_coords_distance = (voxel_coords[:,2]**2 + voxel_coords[:,3]**2)**0.5计算体素坐标在 y 和 x 方向上的欧氏距离。
select_30 = voxel_coords_distance[:]<=30
select_30to50 = (voxel_coords_distance[:]>30) & (voxel_coords_distance[:]<=50)
select_50 = voxel_coords_distance[:]>50根据欧氏距离将体素划分为三个区域,分别是距离小于等于 30、30 到 50、大于 50。
id_list_select_30 = torch.argwhere(select_30==True).reshape(torch.argwhere(select_30==True).shape[0])
id_list_select_30to50 = torch.argwhere(select_30to50==True).reshape(torch.argwhere(select_30to50==True).shape[0])
id_list_select_50 = torch.argwhere(select_50==True).reshape(torch.argwhere(select_50==True).shape[0])为每个区域生成相应的索引列表。
shuffle_id_list_select_30 = id_list_select_30
random.shuffle(shuffle_id_list_select_30)
shuffle_id_list_select_30to50 = id_list_select_30to50
random.shuffle(shuffle_id_list_select_30to50)
shuffle_id_list_select_50 = id_list_select_50
random.shuffle(shuffle_id_list_select_50)对每个区域的索引列表进行随机打乱。
slect_index = torch.cat((shuffle_id_list_select_30[:int(select_ratio*len(shuffle_id_list_select_30))],
shuffle_id_list_select_30to50[:int((select_ratio+0.2)*len(shuffle_id_list_select_30to50))],
shuffle_id_list_select_50[:int((select_ratio+0.2)*len(shuffle_id_list_select_50))]
), 0)将选择的索引合并成一个索引列表,以实现按比率选择体素。
nums = voxel_features.shape[0]
voxel_fratures_all_one = torch.ones(nums,1).to(voxel_features.device)
voxel_features_partial, voxel_coords_partial = voxel_features[slect_index,:], voxel_coords[slect_index,:]生成所有体素特征为 1 的全 1 张量,并根据选择的索引提取部分体素特征和坐标。
batch_size = batch_dict['batch_size']
input_sp_tensor = spconv.SparseConvTensor(
features=voxel_features_partial,
indices=voxel_coords_partial.int(),
spatial_shape=self.sparse_shape,
batch_size=batch_size
)使用 spconv.SparseConvTensor 构建稀疏卷积张量,输入包括部分体素特征、坐标、稀疏形状和批大小。
input_sp_tensor_ones = spconv.SparseConvTensor(
features=voxel_fratures_all_one,
indices=voxel_coords.int(),
spatial_shape=self.sparse_shape,
batch_size=batch_size
)构建所有体素特征为 1 的稀疏卷积张量,用于计算损失。
x = self.conv_input(input_sp_tensor)将输入的稀疏卷积张量传递给第一个稀疏卷积层。
x_conv1 = self.conv1(x)
x_conv2 = self.conv2(x_conv1)
x_conv3 = self.conv3(x_conv2)
x_conv4 = self.conv4(x_conv3)
out = self.conv_out(x_conv4)依次通过模型的各个卷积层,得到最终的输出 out。
self.forward_re_dict['target'] = input_sp_tensor_ones.dense()将目标值(全 1 张量)添加到 forward_re_dict 中。
x_up1 = self.deconv1(out.dense())
x_up2 = self.deconv2(x_up1)
x_up3 = self.deconv3(x_up2)通过一系列的转置卷积层进行上采样。
self.forward_re_dict['pred'] = x_up3将预测值添加到 forward_re_dict 中。
return batch_dict返回更新后的 batch_dict。
损失计算。
self.criterion = nn.BCEWithLogitsLoss()#二元交叉熵损失函数
self.forward_re_dict = {}
def get_loss(self, tb_dict=None):
tb_dict = {} if tb_dict is None else tb_dict
pred = self.forward_re_dict['pred']
target = self.forward_re_dict['target']
loss = self.criterion(pred, target)
tb_dict = {
'loss_rpn': loss.item()
}
return loss, tb_dictVoxel_MAE_res.py区别不是很大,具体可以看源码
补充
VFE模块的包括如下:
from .mean_vfe import MeanVFE
from .pillar_vfe import PillarVFE
from .dynamic_mean_vfe import DynamicMeanVFE
from .dynamic_pillar_vfe import DynamicPillarVFE
from .image_vfe import ImageVFE
from .vfe_template import VFETemplate
__all__ = {
'VFETemplate': VFETemplate,
'MeanVFE': MeanVFE,
'PillarVFE': PillarVFE,
'ImageVFE': ImageVFE,
'DynMeanVFE': DynamicMeanVFE,
'DynPillarVFE': DynamicPillarVFE,
}
这里主要看MeanVFE.py:
这是一个用于点云特征提取的模块,该模块实现了一个均值池化的 VFE(Voxel Feature Extractor)。以下是对代码的解释:
import torch
from .vfe_template import VFETemplate
class MeanVFE(VFETemplate):
def __init__(self, model_cfg, num_point_features, **kwargs):
super().__init__(model_cfg=model_cfg)
self.num_point_features = num_point_features
def get_output_feature_dim(self):
return self.num_point_features
def forward(self, batch_dict, **kwargs):
"""
Args:
batch_dict:
voxels: (num_voxels, max_points_per_voxel, C)
voxel_num_points: optional (num_voxels)
**kwargs:
Returns:
vfe_features: (num_voxels, C)
"""
voxel_features, voxel_num_points = batch_dict['voxels'], batch_dict['voxel_num_points']
points_mean = voxel_features[:, :, :].sum(dim=1, keepdim=False)
normalizer = torch.clamp_min(voxel_num_points.view(-1, 1), min=1.0).type_as(voxel_features)
points_mean = points_mean / normalizer
batch_dict['voxel_features'] = points_mean.contiguous()
return batch_dict
类结构:
MeanVFE类继承自VFETemplate类,表示它是一个 VFE 模块的具体实现。
初始化方法:
__init__方法接受模型配置 (model_cfg) 和点的特征数量 (num_point_features) 作为参数,并通过调用父类的初始化方法来初始化模块。
输出特征维度获取:
get_output_feature_dim方法返回 VFE 模块的输出特征维度,即num_point_features。
前向传播方法:
forward方法用于执行前向传播。- 接收一个字典
batch_dict作为输入,其中包含了voxels(体素特征)和可选的voxel_num_points(每个体素中的点的数量)。 - 计算每个体素中点的均值,然后更新
batch_dict['voxel_features']为计算得到的均值特征。 - 返回更新后的
batch_dict。
均值池化过程:
- 通过对
voxel_features在第二个维度(点的维度)进行求和,得到每个体素内点特征的总和。 - 创建一个
normalizer,其值为每个体素内的点的数量,用于规范化均值的计算。 - 利用
normalizer对点特征总和进行均值计算。 - 将计算得到的均值作为更新后的
voxel_features。
- 通过对
这个模块的主要作用是在每个体素中对点的特征进行均值池化,以获得更紧凑的体素特征表示。



