SAM(segment-anything)与自动驾驶(Autonomous driving)
SAM(Segment Anything)讲解及自动驾驶应用思考
2023机器人行业深度研究报告:12大模型迭代智能驾驶机器人算法进化
Segment Anything Model (SAM) – The Complete 2024 Guide
How to Use the Segment Anything Model (SAM)
Segment Anything(sam)项目整理汇总
Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities
SAM3D: Zero-Shot 3D Object Detection via Segment Anything Model
SAM3D代码
超越BEVFusion | RoboFusion:通过SAM实现稳健的多模态3D检测
RoboFusion: Towards Robust Multi-Modal 3D obiect Detection via SAM
3D-Box-Segment-Anything
[工具分享][AnyLabeling][SAM+Labelme]
《SAM3D: Zero-Shot 3D Object Detection via Segment Anything Model》
室外场景的应用SAM进行零样本 3D 对象检测(目前是单目标,缺乏语义标签,使用MMDetection3D和Segment-Anything实现)
- 将点云投影成BEV图像:使用投影方程决定每个点在图像平面的坐标,并预定义一组反射强度到RGB的映射,以得到BEV图像像素的RGB值
- 由于转化后的BEV图像比较稀疏,使用最大池化减小间隙
- 然后使用SAM语义分割,SAM支持使用各种提示,如点、框和掩膜,本文使用网格提示覆盖整张图像。具体来说,创建32 × 32的在图像平面均匀分布的网格,将它们视作SAM的点提示。分割处尽可能多的前景目标
- SAM输出的掩膜是有噪声的,使用汽车是有大概的面积和长宽比这些先验知识,用于滤除不符合规则的掩膜
- 直接从2D掩膜估计3D边界框的水平属性,高度属性使用的是落在2D掩膜的点云高度进行计算的
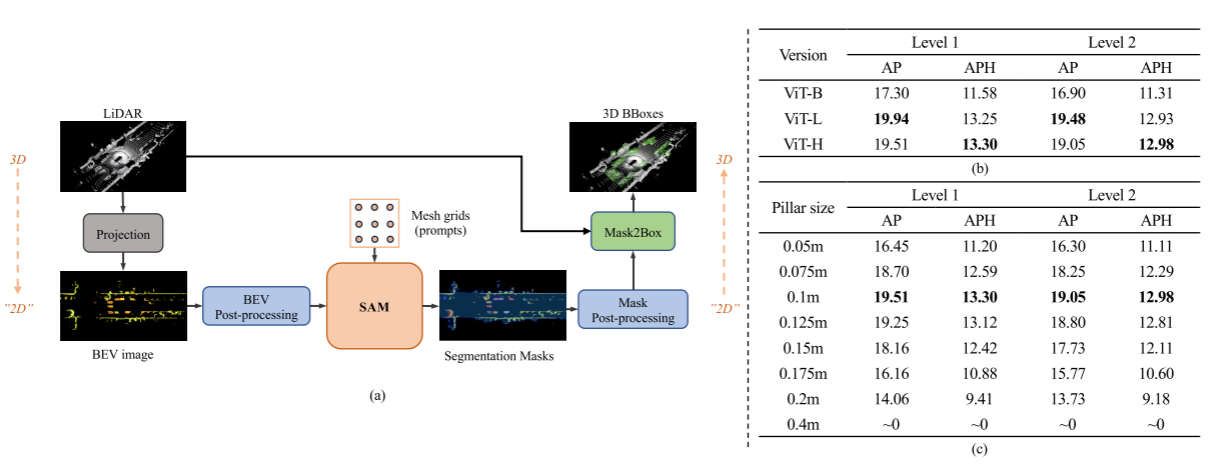
(b) 使用不同版本的 SAM 的 SAM3D 结果。 (c) 使用不同柱尺寸的 SAM3D 结果。在 Waymo 验证集上报告 [0,30)范围内的 VEHICLE 指标。
《RoboFusion: Towards Robust Multi-Modal 3D obiect Detection via SAM》
动机:现实环境的复杂性和恶劣条件,提高自动驾驶中多模态 3D 物体检测的鲁棒性和泛化性带来了机遇和挑战,利用 SAM 等 VFM 来解决分布外 (OOD) 噪声场景
基本思路:引入了 AD-FPN 对 SAM 提取的图像特征进行上采样。采用小波分解对深度引导图像进行去噪,以进一步降低噪声和天气干扰。最后,采用自注意力机制来自适应地重新加权融合特征,增强信息特征,同时抑制多余的噪声
改进策略:
- 1)利用从 SAM 中提取的特征而不是推理分割结果。
- 2)提出SAM-AD,它是针对AD场景的预训练SAM。
- 3)引入了一种新颖的 AD-FPN 来解决特征上采样问题,以将 VFM 与多模态 3D 物体检测器对齐。
- 4)为了进一步减少噪声干扰并保留基本信号特征,设计了深度引导小波注意(DGWA)模块,可以有效衰减高频和低频噪声。
- 5)融合点云特征和图像特征后,提出自适应融合,通过自注意力自适应地重新加权融合特征,进一步增强特征鲁棒性和抗噪性。
- 在 KITTI-C 和 nuScenes-C 数据集中验证了 RoboFusion 针对 OOD 噪声场景的鲁棒性 [Dong et al., 2023],在噪声中实现了 SOTA 性能。
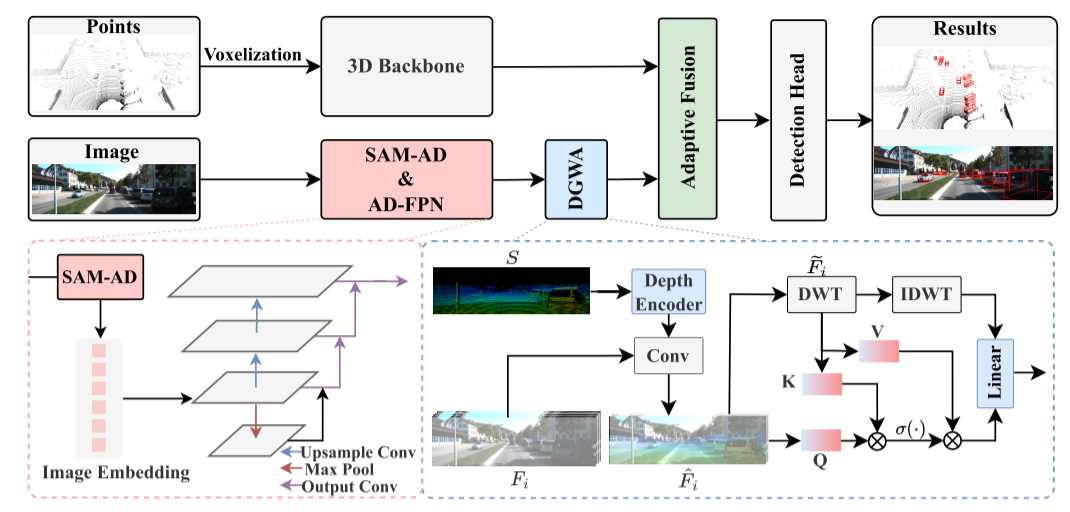
LiDAR 分支几乎遵循基线 [FocalsConv; Transfusion] 生成 LiDAR 特征。在相机分支中,首先,使用高度优化的 SAM-AD 提取鲁棒的图像特征,并使用 AD-FPN 获取多尺度特征。其次,由原始点生成稀疏深度图S,并将其输入深度编码器以获得深度特征,并与多尺度图像特征融合以获得深度引导图像特征。然后使用小波注意力来消除突变噪声。最后,自适应融合通过自注意力机制将点云特征与鲁棒图像特征和深度信息相结合。
SAM-AD模型的构成:
SAM-AD。为了进一步使SAM适应AD(自动驾驶)场景,对SAM进行预训练以获得SAM-AD。具体来说,从成熟的数据集(即 KITTI [Geiger et al., 2012] 和 nuScenes [Caesar et al., 2020])中收集了大量图像样本,形成了基础 AD 数据集。遵循 DMAE [Wu et al., 2023],对 SAM 进行预训练,以获得 AD 场景中的 SAM-AD,如下图所示。
- 将 x 表示为来自 AD 数据集的干净图像(即 KITTI [Geiger et al., 2012] 和 nuScenes [Caesar et al., 2020]) 和 η 作为 [Dong et al., 2023] 基于 x 生成的噪声图像。噪声类型和严重程度分别从四种天气(即雨、雪、雾和阳光)和从1到5的五个严重程度中随机选择。
- 采用 SAM Kirillov et al., 2023和 MobileSAM Zhang et al., 2023a 的图像编码器作为编码器,而解码器和重建损失与 DMAE Wu et al., 2023 相同。
- 对于 FastSAM Zhao et al., 2023,采用 YOLOv8 在 AD 数据集上预训练 FastSAM。为了避免过度拟合,使用随机调整大小和裁剪作为数据增强。还将掩码比率设置为 0.75,并在 8 个 NVIDIA A100 GPU 上训练了 400 个 epoch。
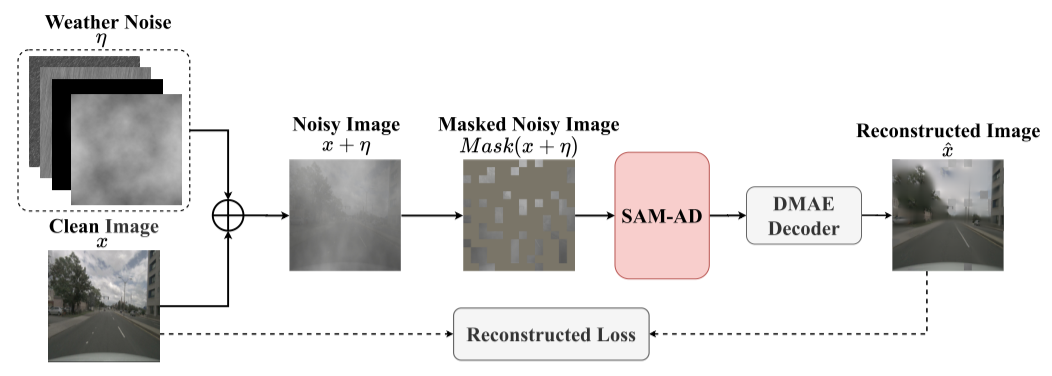
用包含多个天气噪声的 η 来破坏干净的图像 x,然后随机屏蔽噪声图像 x+η 上的几个补丁,以获得屏蔽的噪声图像Mask(x+η)。 SAM-AD 和 DMAE 解码器经过训练,可以根据 Mask(x + η) 重建干净的图像 ^x。
AD-FPN模块
采用 SAM 的图像编码器来提取鲁棒的图像特征。然而,SAM 使用 ViT 系列 Dosovitskiy et al., 2020 作为其图像编码器,它排除了多尺度特征,仅提供高维低分辨率特征。为了生成目标检测所需的多尺度特征,受 ViTDet[Li et al., 2022a] 的启发,我们设计了一个 AD-FPN,它提供基于 ViT 的多尺度特征。具体来说,利用 SAM 提供的步幅为 16(尺度=1/16)的高度维图像嵌入,我们生成了一系列步幅为 {32,16,8,4} 的多尺度特征 Fms。接下来,我们通过类似于 FPN 的自下而上的方式整合 Fms 来获得多尺度特征
深度引导小波注意(DGWA)模块:
- 1)设计了深度引导网络,通过结合图像特征和点云的深度特征,在图像特征之前添加几何形状。
- 2)使用Haar小波变换将图像的特征分解为四个小波子带[Liu et al., 2020a],然后注意力机制允许对子带中的信息特征进行去噪。
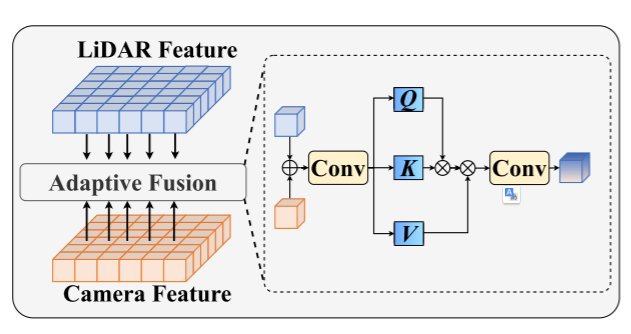
Adaptive Fusion模块
- 采用自注意力机制来自适应地重新加权融合特征,如图3所示。模态特异性的损坏程度是动态的,自注意力机制允许自适应重新加权特征可以增强信息特征并抑制冗余噪声。
实验结果具体看论文
3D-Box-Segment-Anything
这是一个项目,将将Segment Anything与VoxelNeXt相结合,将其扩展到 3D 感知
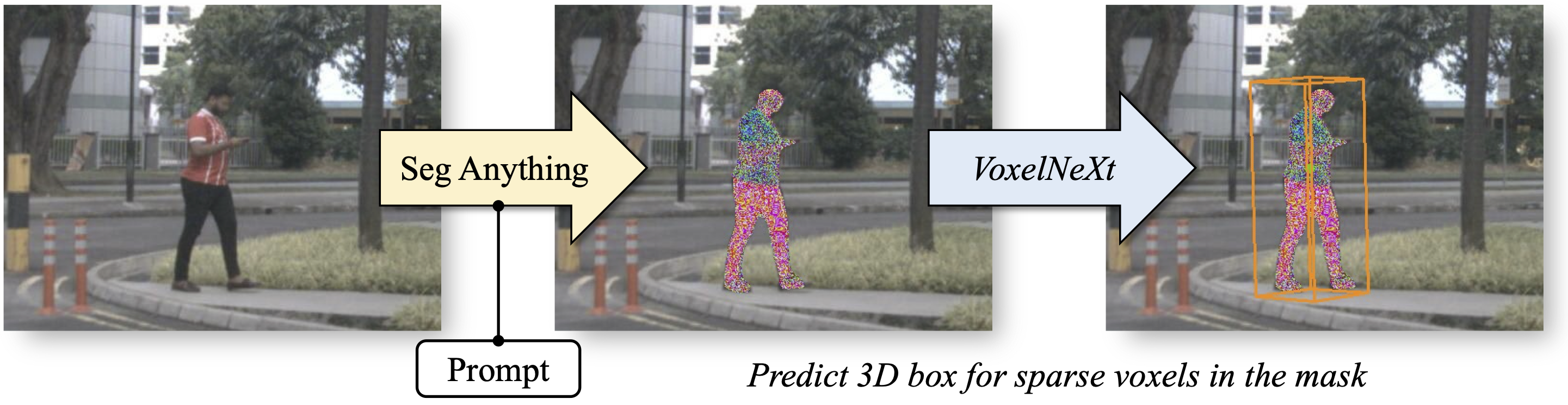
核心思想
VoxelNeXt是一个完全稀疏的 3D 检测器。它根据每个稀疏体素预测 3D 对象。我们将 3D 稀疏体素投影到 2D 图像上。然后可以为 SAM 掩模中的体素生成 3D 框。
一些生成图的样例:

演示的demo代码



