室外场景的点云对比学习方法(CO^3,结合代码)
对比学习(Contrastive Learning)方法综述
对比学习(Contrastive Learning),必知必会
论文地址:CO^3: Cooperative Unsupervised 3D Representation Learning for Autonomous Driving
论文主页
代码地址
《COˆ3: Cooperative Unsupervised 3D Representation Learning for Autonomous Driving》室外场景的无监督对比学习方法(使用MMDetection3D和OpenPCDet实现)
动机
- 室内场景点云的无监督对比学习取得了巨大的成功。然而,室外场景点云的无监督表示学习仍然具有挑战性
- 到目前为止,随机初始化和直接从头开始对详细注释数据进行训练仍然在室外场景点云任务中占据主导地位
挑战
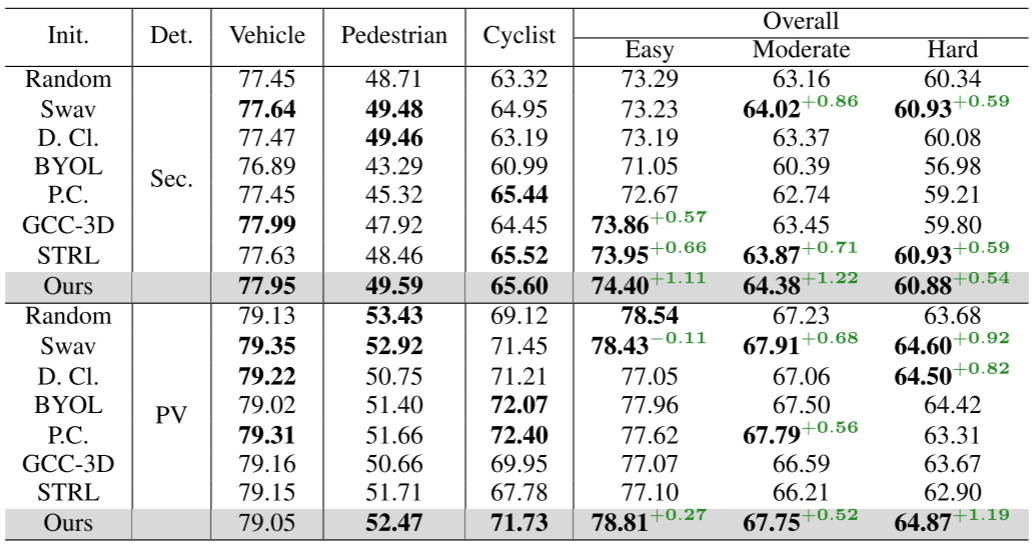
- 如何找到更好的视图来学习室外场景激光雷达点云的表示?
- 之前的方法:
- 室内场景:
- PointContrast 建议重建整个室内场景,收集两个不同姿势的部分点云,并将它们用作对比学习中的两个视图,以学习密集(点级或体素级)表示
- 然而,室外场景是动态的、大规模的,无法重建建筑景观的整个场景
- 室外场景:
- 将数据增强应用于单帧点云,并将原始版本和增强版本视为不同的视图,然而,点云的所有增强,包括随机下降、旋转和缩放,都可以通过线性变换来实现,并且以这种方式构建的视图没有足够的差异
- 将不同时间戳的点云视为不同的视图,然而,移动的物体会很难找到正确的对应关系来进行对比学习,由于这些限制,预训练的 3D 编码器在传输到不同 LiDAR 传感器收集的数据集时无法取得明显的改进。
- 室内场景:
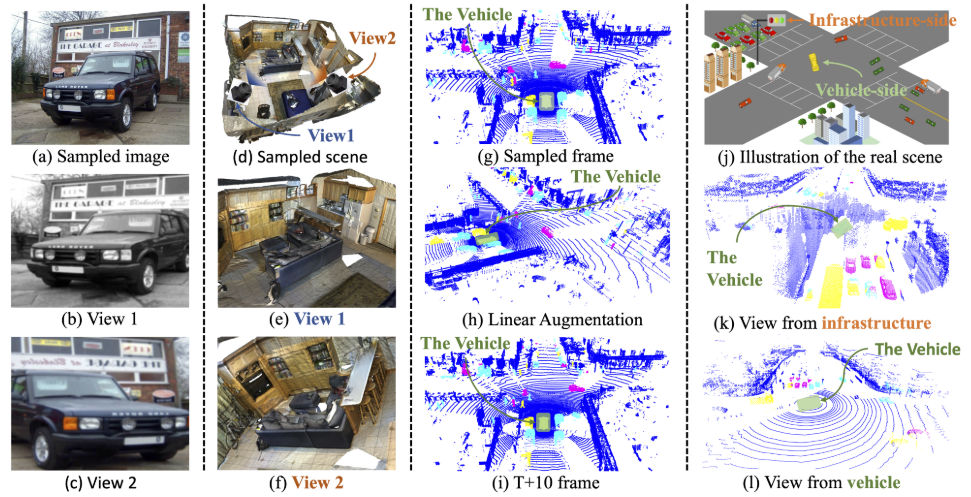
提出了两个模块,分别是协同对比学习方法(Cooperative Contrastive)以及上下文形状预测(Contextual Shape Prediction):
- 协同对比学习方法使用的是DAIR-V2X数据集,从基础设施LiDAR和车辆LiDAR的点云来构建用于对比表示学习的两个视图(不同位置相同时间戳获取足够不同并共享足够语义信息);
- 上下文形状预测使用密集表示来重建相邻点的局部分布,使用的是形状上下文来描述每个点邻域的局部分布,预训练的任务是利用提取的点级或体素级表示来预测每个点或体素的局部分布,论文说这种精细化的重建预训练任务引入了更多与任务相关的信息,并有助于学习更好的表征
- 最后将COˆ3在DAIR-V2X数据集上训练的预训练模型中的稀疏卷积的3D编码器主干网络应用到不同数据集(ONCE,KITTI,NuScenes,Waymo)下游任务三维目标检测(SECOND,PV-RCNN,CenterPoint)中,发现效果都有提升。

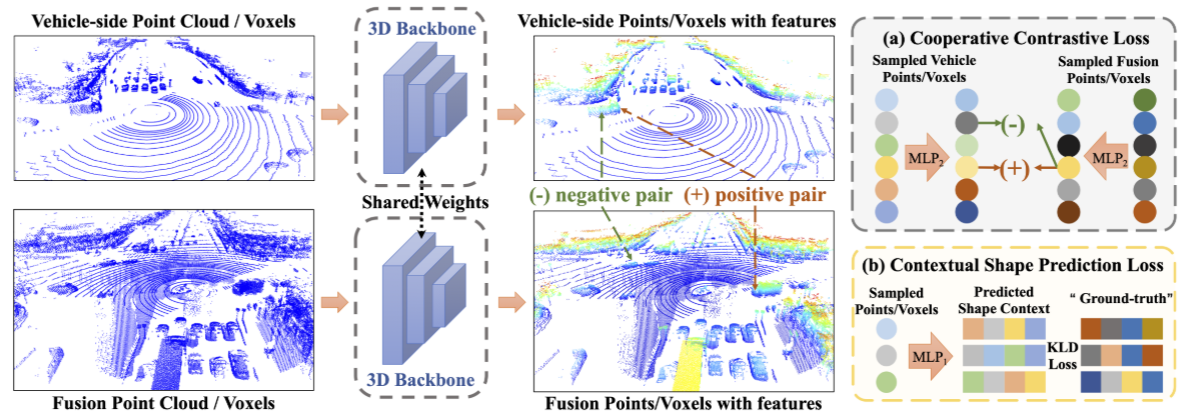
协同对比损失
损失的定义如下:
$$L_{CO_2}=\frac1N_1\sum_{n=1}^{N_1}-\log(\frac{\exp(z_{veh}^n\cdot z_{fusion}^n/\tau)}{\sum_{i =1}^{N_1}\exp(z_{veh}^i \cdot z_{fusion}^i /\tau)}) \tag{1} $$
$$ { z_{v/f}^n }{n=1}^{N_1} \stackrel{sample}{\sim} Z{v/f} $$
$$ Z_{v/f}=normalize(MLP_1(\textbf{P}_{v/f}^{feat^{enc}})) $$
其中,车辆和融合点云的嵌入特征,$\textbf{P}{veh} ^{feat^{enc}}$和$\textbf{P}{fusion} ^{feat^{enc}}$,
- 首先由多层感知器$\rm MLP_1$投影到公共特征空间,
- 然后进行归一化。$Z_{v/f}\in\mathbb R^{N_{v/f}^{p^{enc}}\times d_1}$是车辆点云和融合点云的投影特征,其中$d_1$表示公共特征空间的维度,$N_{v/f}^{p^{enc}}$分别是编码车辆和融合点云的点/体素数。
- 然后,从$Z_{v/f}$中采样$N_1$对特征($z$)进行对比学习。根据的经验观察,基点对对比学习有很大的负面影响。因此,将那些高度值低于阈值$z_{thd}$的点标记为地面点,并在采样时将其过滤掉。
- 经过滤波后,从车辆点云中随机采样N1个点,并在融合点云中找到它们对应的点(或体素),形成N1对点(或体素)。将对应点(或体素)视为正对,否则视为负对进行对比学习,最终的损失函数如公式(1)所示,其中τ是温度参数。
补充:公式(1)为对比学习损失(常用的是InfoNCE loss,在何凯明大佬的论文MoCo中也有讲解,跟cross entropy loss相似,唯一的区别是,在cross entropy loss里,$N_1-1$指代的是数据集里类别的数量,而在对比学习InfoNCE loss里,这个$N_1-1$指的是负样本的数量。注意上式分母中的sum是在1个正样本和$N_1-1$个负样本上做的,从1到$N_1$,所以共$N_1$个样本)
参考代码
整个网络的代码配置文件,模型名为LIDAR_3D_ENCODER,由5部分组成,分别是车载点云和融合点云栅格化范围尺寸的配置、栅格编码(简单平均每个Voxel中的点云特征作为Volex的特征)、中间层编码(稀疏卷积)以及训练的配置文件(主要是自监督的两个损失函数的设计):
- 将基础设施点云转化为车载点云坐标下的代码
- 转换后的基础设施点云融合车载点云的融合点云代码,在第一维上直接进行拼接
- 根据车载点云和融合点云栅格化范围尺寸进行体素化代码,返回 voxels: [M, max_points, ndim]、coordinates: [M, 3]、num_points_per_voxel: [M]、voxels_coors:[points.size(0), 3],表示每个点云属于对应体素的坐标
- 通过HardSimpleVFE获取Voxel的特征代码
- 使用稀疏卷积(SparseConv3d和SubMConv3d)返回spatial_features, voxel_features, coors
- 损失函数设计,分别是协同对比损失(cooperative_contrastive_loss)和下面要讲到的上下文形状预测损失(contextual_shape_prediction_loss),这里先讲前者:
- 从encode_features[-1].dense()到permute(0,2,3,4,1):N, D, H, W, C到view(-1, C)到一个简单的全连接层(pts_transform_spatial_feature,最后一维是256)到view(N, D, H, W ,256),即恢复成dense的情况
- 最后将车载点云特征和融合点云特征以、对应的Voxel坐标、打乱的融合点云的id以及车载点云(用于获取z轴值来过滤地面点)送进损失函数中
- 损失函数的参数主要为温度系数,采样数量,是否过滤地面点等,这里进行简略的介绍
if self.fileter_ground_points:
none_ground_idx = torch.where(vehicle_point[:,2] > -1.6)[0]
sample_from_none_ground = torch.randperm(none_ground_idx.shape[0])[:self.sample_num].to(vehicle_voxels_coor.device)
sampled_idx = none_ground_idx[sample_from_none_ground]
else:
sampled_idx = torch.randperm(vehicle_voxels_coor.shape[0])[:self.sample_num].to(vehicle_voxels_coor.device)- 这部分代码根据一个标志决定是否过滤地面点,并从剩余点中随机采样一定数量的点。
sampled_vehicle_voxels_coor = vehicle_voxels_coor[sampled_idx]
sampled_vehicle_D, sampled_vehicle_H, sampled_vehicle_W = sampled_vehicle_voxels_coor[:, 0], sampled_vehicle_voxels_coor[:,1], sampled_vehicle_voxels_coor[:,2]
sampled_vehicle_voxel_feat = dense_vehicle_voxel_feat[sampled_vehicle_D, sampled_vehicle_H, sampled_vehicle_W, :]- 这几行根据采样的点索引提取出对应的体素坐标和特征。
sampled_fusion_points_shuffled_id = torch.where((fusion_points_shuffled_id.unsqueeze(0) - sampled_idx.unsqueeze(1))==0)[1]
sampled_fusion_voxels_coor = fusion_voxels_coor[sampled_fusion_points_shuffled_id]
sampled_fusion_D, sampled_fusion_H, sampled_fusion_W = sampled_fusion_voxels_coor[:,0], sampled_fusion_voxels_coor[:,1], sampled_fusion_voxels_coor[:, 2]
sampled_fusion_voxel_feat = dense_fusion_voxel_feat[sampled_fusion_D, sampled_fusion_H, sampled_fusion_W, :]- 这部分代码根据采样的点索引提取出对应的融合体素坐标和特征。
sampled_vehicle_voxel_feat = torch.nn.functional.normalize(sampled_vehicle_voxel_feat, dim=1)
sampled_fusion_voxel_feat = torch.nn.functional.normalize(sampled_fusion_voxel_feat, dim=1)- 这两行对采样的特征进行归一化处理。
s = torch.matmul(sampled_vehicle_voxel_feat, sampled_fusion_voxel_feat.permute(1, 0).contiguous())- 这行计算采样的车辆体素特征和融合体素特征之间的相似度矩阵。
s_ = s.clone().detach()
s_pos_out = torch.diag(s_)
s_sum_out = torch.sum(s_, dim=1)- 这几行从相似度矩阵中提取出正样本相似度和负样本相似度的分量。
s = s / self.temperature
s = torch.exp(s)- 这两行对相似度矩阵进行温度缩放和指数运算。
s_pos = torch.diag(s)
s_sum = torch.sum(s, dim=1)- 这两行从缩放后的相似度矩阵中提取出正样本相似度和负样本相似度。
cooperative_contrastive_loss += torch.mean(-1.0 * torch.log(s_pos / s_sum))- 这行计算当前样本的协作对比损失,并累加到总的损失中。
pos_sim.append(torch.mean(s_pos_out).unsqueeze(0))
neg_sim.append(torch.mean(s_sum_out - s_pos_out).unsqueeze(0) / (self.sample_num - 1))- 这两行分别将当前样本的正样本相似度和负样本相似度存储到对应的列表中。
if len(pos_sim) > 0:
pos_sim = torch.mean(torch.cat(pos_sim))
neg_sim = torch.mean(torch.cat(neg_sim))
self.log_var['pos_sim'] = pos_sim
self.log_var['neg_sim'] = neg_sim
del pos_sim
del neg_sim- 这部分代码在遍历完所有样本后,计算平均正样本相似度和平均负样本相似度,并将它们记录到
log_var字典中,最后释放这两个列表的内存。
return cooperative_contrastive_loss- 最后,该方法返回计算得到的协作对比损失。
上下文形状预测损失
CO^3 旨在学习适用于各种下游数据集的表示。但是公式(1)中的对比损失很难编码任务相关信息,如这个论文中讲到的所示,作者诉诸于图像上的额外重建目标来引入任务相关信息。然而,对于室外场景点云,用点/体素级表示重建整个场景极其困难。为了缓解这个问题,建议用其表示重建每个点/体素的邻域。具体来说,上下文形状预测损失设计如下。描述了车辆特征的过程,类似的过程也适用于融合特征,损失函数如下:
$$ L_{CSP} =\frac1N_2\sum_{n=1}^{N_2}\sum_{m=1}^{N_{bin}}p_{n,m}\log\frac{p_{n,m}}{q_{n,m}} \tag{2}$$
$$ {p_{n,*}}_{n=1}^{N_2} \stackrel{sample}{\sim}P $$
$$ {q_{n,*}}{n=1}^{N_2} \stackrel{sample}{\sim}Q;P= softmax(MLP_2(\textbf{P}{veh}^{feat^{enc}})) $$
其中车辆点云的编码特征$\textbf{P}_{veh}^{feat^{enc}}$ :
- 首先通过另一个多层感知器 $MLP_2$,并对投影特征应用 softmax 操作以获得每个点/体素的预测局部分布,$N_{veh}^{p^{enc}}$ 是由 3D 编码器嵌入后的车辆侧点/体素的数量,$N_{bin}$ 是划分每个点/体素的局部邻域的 bin 数。
- 在本文中使用 $N_{bin} = 32$ 并预先计算“groundtruth”局部形状上下文 ($N_{veh}^p$是原始输入车辆点/体素的数量),这将在稍后讨论。
- 对于 P 和 Q,从 P 和 Q 中抽取 $N_2$ 个采样点/体素。有 $ p_{n,} \in \mathbb R^{N_{bin}}$和 $ q_{n,} \in \mathbb R^{N_{bin}}$ 。请注意,这些采样的预测上下文形状分布是成对的。
- 最后,如等式(2)中的第一行所示,$L_{CSP} $是应用于 $p_{n,}$和 $q_{n,}$的 KL 散度损失,其中 KL 散度描述了两个概率分布($p_{n,}$和 $q_{n,}$)之间的距离。
为了计算第 i 个点/体素的“ground Truth”形状上下文,首先将点/体素的邻域沿 x-y 平面划分为 $N_{bin}$ 个 bin,其中 R1 = 0.5m,R2 = 4m。然后计算每个 bin 中的点/体素的数量,这导致 $N_{bin} = 32$ 个数字 $ Q_{i,} ^{raw} \in \mathbb R^{N_{bin}}$ 。接下来,$Qi,$ 最终确定如下,其中 $SF_{CSP}$ 是使分布合理的比例因子。
$$ Q_{i,}=softmax(normalize(Q_{i,} ^{raw})\times SF_{CSP})\tag{3} $$
补充:K-L散度是一种量化两种概率分布P和Q之间差异的方式,又叫相对熵,散度越小,说明概率 Q 与概率 P 之间越接近,那么估计的概率分布与真实的概率分布也就越接近。参考链接1,参考链接2
参考代码
损失函数名为contextual_shape_prediction_loss,代码,输入为vehicle_points(车载点云)、vehicle_voxels_coors(每个车载点云对应的栅格的坐标)、vehicle_spatial_features(车载点云的dense特征,维度是N, D, H, W, C)、vehicle_spatial_feature_voxels_coors(车载栅格特征所对应的点云的栅格坐标,与vehicle_voxels_coors相同)、fusion_spatial_features(融合点云的dense特征,维度是N, D, H, W, C)、fusion_spatial_feature_voxels_coors(融合栅格特征所对应的点云的栅格坐标)、fusion_points(融合点云),前向传播代码,主要作用是计算两个方面的 contextual shape prediction loss,分别是车辆端和融合端:
def forward(self, **kwargs):
vehicle_points = kwargs['vehicle_points']
fusion_points = kwargs['fusion_points']
vehicle_voxels_coors = kwargs['vehicle_voxels_coors']
vehicle_spatial_features = kwargs['vehicle_spatial_features']
vehicle_spatial_feature_voxels_coors = kwargs['vehicle_spatial_feature_voxels_coors']
fusion_spatial_features = kwargs['fusion_spatial_features']
fusion_spatial_feature_voxels_coors = kwargs['fusion_spatial_feature_voxels_coors']
batch_size = len(vehicle_points)
contextual_shape_prediction_loss = torch.zeros(1).to(vehicle_points[0].device)- 获取传入的关键字参数,这些参数包含了车辆端和融合端的相关数据,如车辆点云、融合点云、车辆体素坐标等。
- 初始化 contextual shape prediction loss 为零。
for b in range(batch_size):
vehicle_point = vehicle_points[b]
vehicle_voxels_coor = vehicle_voxels_coors[b]
vehicle_spatial_feature = vehicle_spatial_features[b]
vehicle_spatial_feature_voxels_coor = vehicle_spatial_feature_voxels_coors[b].long() // 8
vehicle_spatial_feature_voxels_coor = limit_coor_range(vehicle_spatial_feature_voxels_coor, vehicle_spatial_feature)
fusion_spatial_feature = fusion_spatial_features[b]
fusion_spatial_feature_voxels_coor = fusion_spatial_feature_voxels_coors[b].long() // 8- 遍历每个批次中的样本。
- 获取当前批次中的车辆端和融合端数据,包括车辆点云、车辆体素坐标、车辆特征、融合特征以及相应的体素坐标。
- 将车辆空间特征的体素坐标限制在一定范围内。
if self.fileter_ground_points:
none_ground_idx = torch.where(vehicle_point[:,2] > -1.6)[0]
sample_from_none_ground = torch.randperm(none_ground_idx.shape[0])[:self.sample_num].to(vehicle_point.device)
sampled_idx = none_ground_idx[sample_from_none_ground]
else:
sampled_idx = torch.randperm(vehicle_point.shape[0])[:self.sample_num].to(vehicle_point.device)- 根据是否过滤地面点云,选择采样的方式。如果需要过滤地面点云,则从车辆点云中去除地面点云,然后随机采样一定数量的点云数据。否则,直接随机采样车辆点云。
with torch.no_grad():
sampled_vehicle_points = vehicle_point[sampled_idx]
fusion_point = fusion_points[b]
distance_vehicle_to_fusion = torch.sum(
(sampled_vehicle_points.unsqueeze(1) - fusion_point.unsqueeze(0)) ** 2,
dim=-1)
sorted, indices = torch.sort(distance_vehicle_to_fusion, dim=1)
fix_point_number_query_indices = indices[:, :self.topk_nearest]
queried_points = torch.gather(fusion_point.unsqueeze(0).repeat(fix_point_number_query_indices.shape[0], 1, 1)[:,:,:3], 1,
fix_point_number_query_indices.unsqueeze(-1).repeat(1, 1, 3))
source_partition = self.local_feature_extractor.compute_partitions_batch(queried_points)- 使用无梯度计算环境(
torch.no_grad()),计算采样车辆点云与融合点云之间的欧式距离,并选取距离最近的前 k 个点。 - 通过局部特征提取器计算查询点所属的分区。
- 计算每个分区内的点数。
sampled_vehicle_voxels_coor_low_res = vehicle_spatial_feature_voxels_coor[sampled_idx]
sampled_vehicle_D, sampled_vehicle_H, sampled_vehicle_W = sampled_vehicle_voxels_coor_low_res[:,
0], sampled_vehicle_voxels_coor_low_res[:,
1], sampled_vehicle_voxels_coor_low_res[:, 2]
sampled_vehicle_voxel_feat_low_res = vehicle_spatial_feature[sampled_vehicle_D, sampled_vehicle_H,
sampled_vehicle_W, :]
projected_feat_low_res = self.projector_low_res(sampled_vehicle_voxel_feat_low_res)
predicted_dist = torch
.softmax(self.projector_final(projected_feat_low_res), dim=-1)
contextual_shape_prediction_loss += 10.0 * self.kld(predicted_dist.log(), gt_dist)- 从车辆端空间特征中提取采样点对应的低分辨率体素特征。
- 将低分辨率体素特征通过投影器转换为高分辨率特征。
- 通过 softmax 函数计算预测的分布。
- 计算 KL 散度,并加到 contextual shape prediction loss 中。
sampled_fusion_voxels_coor_low_res = fusion_spatial_feature_voxels_coor[sampled_idx]
sampled_fusion_D, sampled_fusion_H, sampled_fusion_W = sampled_fusion_voxels_coor_low_res[:,
0], sampled_fusion_voxels_coor_low_res[:,
1], sampled_fusion_voxels_coor_low_res[:, 2]
sampled_fusion_voxel_feat_low_res = fusion_spatial_feature[sampled_fusion_D, sampled_fusion_H,
sampled_fusion_W, :]
projected_feat_low_res = self.projector_low_res_fusion(sampled_fusion_voxel_feat_low_res)
predicted_dist = torch.softmax(self.projector_final(projected_feat_low_res), dim=-1)
contextual_shape_prediction_loss += 10.0 * self.kld(predicted_dist.log(), gt_dist)- 从融合端空间特征中提取采样点对应的低分辨率体素特征。
- 将低分辨率体素特征通过融合端的投影器转换为高分辨率特征。
- 通过 softmax 函数计算预测的分布。
- 计算 KL 散度,并加到 contextual shape prediction loss 中。
return contextual_shape_prediction_loss- 返回计算得到的 contextual shape prediction loss。
用于计算形状上下文的Python风格代码算法流程图

实验结果
表 1:Once 数据集上的 3D 对象检测结果。在 3 种不同的检测器上进行了实验:Second(简称 Sec.)、PV-RCNN(简称 PV)和 CenterPoint (简称 Cen.)以及 8 种不同的初始化方法,包括随机(简称如 Rand,即从头开始训练)、Swav 、Deep Cluster(简称为 D. Cl.)、BYOL、Point Contrast(简称为 P.C.)、GCC-3D 和STRL 。结果为 mAP(以 % 表示)。 “0-30m”、“30-50m”和“>50m”分别表示0至30米、30至50米和50米至无穷远物体的结果。最后一栏的“mAP”是总体评估和比较的主要指标。为了更好地理解,对每个范围内每个类别中的前 3 个 mAP 使用粗体字体。
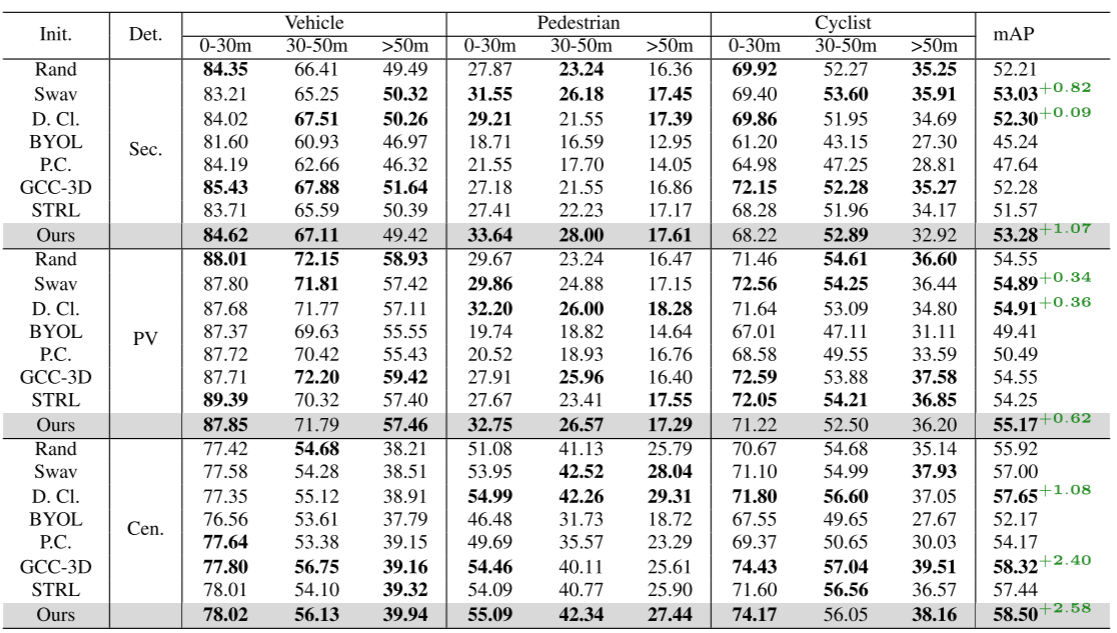
表 2:KITTI 数据集上的 3D 物体检测结果 。结果为 mAP(以 % 表示)。 “Easy”、“Moderate”和“Hard”分别表示 KITTI 数据集中定义的难度级别。每个类别的结果都处于中等水平。最后一列中的“总体”结果是比较的主要指标。为了更好地理解,对每个难度级别的每个类别中的前 3 个 mAP 使用粗体字体。