弱监督下的三维目标检测(单目篇)
一、基于单目图像的三维目标检测
3D Object Detection from Images for
Autonomous Driving: A Survey
第一篇:WeakM3D
Towards Weakly Supervised Monocular 3D Object Detection(2022)
摘要
单目 3D 物体检测是 3D 场景理解中最具挑战性的任务之一。由于单目图像的不适定性质,现有的单目 3D 检测方法高度依赖于 LiDAR 点云上手动注释的 3D 框标签的训练。这个注释过程非常费力且昂贵。为了摆脱对 3D 框标签的依赖,在本文中,我们探索了弱监督的单目 3D 检测。具体来说,我们首先检测图像上的 2D 框。然后,我们采用生成的2D框来选择相应的RoI LiDAR点作为弱监督。最终,我们采用网络来预测 3D 框,它可以与相关的 RoI LiDAR 点紧密对齐。该网络是通过最小化我们新提出的 3D 框估计和相应的 RoI LiDAR 点之间的 3D 对齐损失来学习的。我们将说明上述学习问题的潜在挑战,并通过在我们的方法中引入几种有效的设计来解决这些挑战。
贡献如下:
- 首先,我们探索了一种弱监督单目 3D 检测的新方法 (WeakM3D),消除了对 3D 框标签的依赖。
- 其次,我们提出了 WeakM3D 中的主要挑战,并相应地介绍了四种有效的策略来解决这些问题,包括几何对齐损失、光线追踪损失、损失平衡和学习解纠缠。
- 第三,根据 KITTI 基准进行评估,我们的方法为弱监督单目 3D 检测构建了强大的基线,甚至优于一些现有的使用大量 3D 框标签的完全监督方法。
相关工作
基于单目的三维目标检测方法
近年来,单目 3D 物体检测取得了显着的进步。 巴西和刘(2019);马等人(2021)。先前的作品,例如 Mono3D Chen 等人(20Penet) 和 Deep3DBox Mousavian 等人(2017)主要利用几何约束和辅助信息。最近,Mondle Ma 等人 (2021) 通过三种定制策略来减少单目 3D 检测中的定位误差。此外,随着深度估计的发展,其他一些单目方法尝试使用由现成的深度估计器生成的显式深度信息。伪LiDARWang等人(2019); Weng & Kitani (2019) 转换纯图像表示,以模仿真实的 LiDAR 信号,以利用现有的基于 LiDAR 的 3D 探测器。 PatchNet Ma 等人 (2020)重新思考伪激光雷达的底层机制,指出其有效性来自于3D坐标变换。尽管最近的单目 3D 物体检测方法取得了令人兴奋的结果,但它们严重依赖于大量手动标记的 3D 框。
基于弱监督的三维目标检测方法
为了减轻繁重的注释成本,提出了一些弱监督方法。 WS3D 孟等人(2020) 引入了一种用于基于 LiDAR 的 3D 对象检测的弱监督方法,该方法仍然需要一小组弱注释的场景和一些精确标记的对象实例。他们使用两阶段架构,第一阶段学习在鸟瞰视图中单击注释的水平中心下生成圆柱形对象建议,第二阶段学习细化圆柱形建议以获得 3D 框和置信度分数。这种弱监督设计并没有完全摆脱对 3D 框标签的依赖,仅适用于 LiDAR 点云输入。另一种弱监督3D检测方法Qin等人(2020,VS3D)也将点云作为输入。它提出了一个 3D 提案模块,并利用现成的 2D 分类网络来识别从点云生成的 3D 框提案。这两种方法都不能直接应用于拟合单个 RGB 图像输入。此外,扎哈罗夫等人(2020,Autolabeling) 提出了一个自动标记管道。具体来说,他们将一种新颖的可微分形状渲染器应用于有符号距离场(SDF),并与归一化对象坐标空间(NOCS)一起使用。他们的自动标记流程由六个步骤组成,并具有课程学习策略。与 WeakM3D 相比,他们的方法不是端到端的,而且相当复杂。
方法

- 首先,通过 RANSAC Fischler & Bolles (1981) 从原始 LiDAR 点云估计地平面,用于删除原始点云中的地面点。
- 选择在 2D 框内的图像上投影的剩余 LiDAR 点作为初始目标点云,其中包含一些不感兴趣的点,例如背景点。或者,我们还可以使用预训练网络中的 2D 实例掩模来选择初始对象点云。
- 然后,我们通过 Ester 等人的无监督密度聚类算法过滤初始点云来获得对象 LiDAR 点。 (1996),附录中有详细说明。
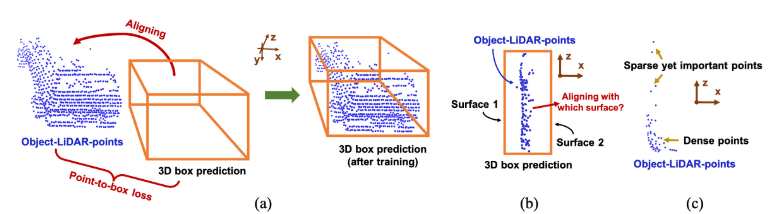
几何对齐的3D框预测
不失一般性,3D 对象框应包含对象LiDAR 点并沿框边缘与它们对齐。为了促进物体 3D 位置的学习,我们在网络的 3D 框预测和物体 LiDAR 点之间施加了位置约束。简单的解决方案:
- 最小化从物体中心到每个激光雷达点的欧几里德距离。
- 然而,这种微不足道的损失由于其定位不准确而误导了网络。这个中心距离损失 Lcenter 会将预测的对象中心推到尽可能靠近点云的位置。不幸的是,物体激光雷达点通常是从物体的可见表面捕获的,这意味着仅使用 Lcenter 的预测中心往往接近真实框边缘,而不是真实框中心。
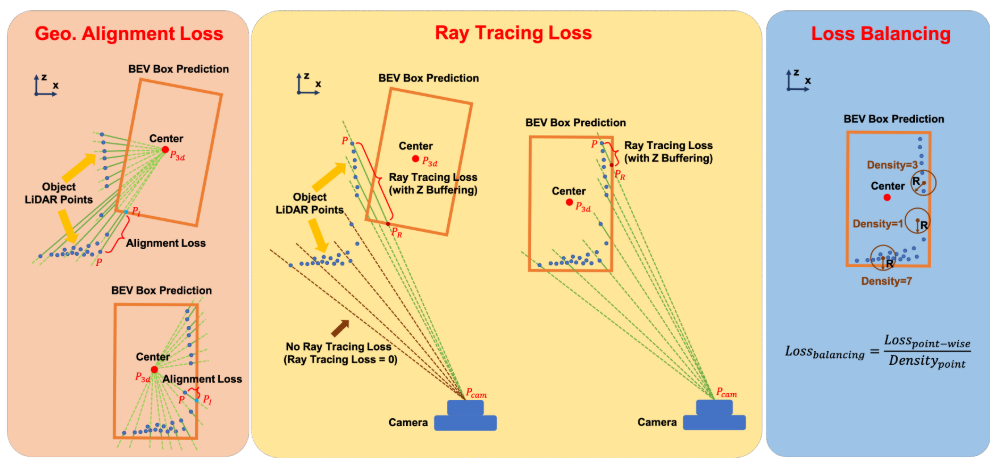
基于上述分析,我们提出了预测的 3D 框和关联的目标 LiDAR 点之间的几何对齐损失,其中主要障碍在于正确测量点到 3D 框的距离。为此,我们创建一条从 3D 框中心 P3d 到每个物体 LiDAR 点 P 的射线,其中该射线与框预测的边缘在 PI 处相交。因此,物体-LiDAR点之间每个点的几何对准损失如下:
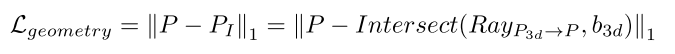
光线追踪消除对准模糊性
尽管几何对齐限制了 3D 框预测和物体 LiDAR 点,但当物体 LiDAR 点无法表示物体的充分 3D 轮廓时,就会出现歧义,例如,物体 LiDAR 点仅从物体的一个表面捕获目的。具体来说,模糊度是指在对齐过程中如何在语义上决定每个目标激光雷达点与框预测的边缘之间的对应关系。我们称这个问题为对齐模糊性。
一般来说,我们通过考虑遮挡约束来解决对齐模糊性。与相机成像的过程类似,在扫描场景时,如果遇到障碍物,激光雷达设备的信号就会被反射。考虑到相机FOV(视场)内反射的LiDAR信号,我们建议实现从相机光心Pcam到每个物体LiDAR点的光线追踪,最小化每个物体LiDAR点到物体上交点的距离盒子。如图4所示,激光雷达点为P,交点为PR(使用Z缓冲,即选择较近的交点),光线追踪损失如下:
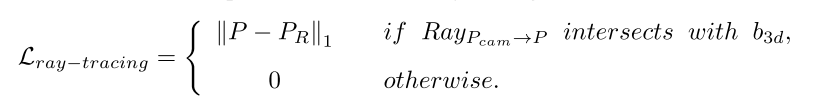
{P1, P2} = Intersect(RayPcam→P, b3d),如果 P1 更靠近相机,则 PR = P1,否则为 P2。请注意,如果光线不与预测的 3D 框相交,则光线追踪损失为零,这意味着此处的损失不会对反向传播中的梯度下降产生影响。通过这种方式,我们消除了对齐模糊性,鼓励 3D 框预测遵循遮挡约束,同时与对象 LiDAR 点进行几何对齐。
逐点损耗平衡
目标激光雷达点的不同空间分布也是一个障碍,即点密度有些高,有些低。诸如几何对准损失和光线追踪损失等逐点损失都受到不均匀分布的影响。具体来说,密集区域产生的损失可以主导总损失,忽略其他相对稀疏但重要的点所产生的损失。为了平衡影响,我们在计算损失时对目标激光雷达点的密度进行归一化。让我们计算 Pi 点附近的 LiDAR 点 Ei 的数量,如下所示:
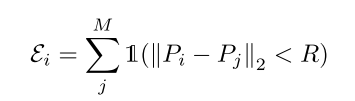
其他具体参考原论文
第二篇:Weakmono3d
Weakly Supervised Monocular 3D Object Detection using Multi-View Projection and Direction Consistency(2023)
摘要
单目3D物体检测因其易于应用而成为自动驾驶的主流方法。一个突出的优点是在推理过程中不需要LiDAR点云。然而,大多数当前方法仍然依赖 3D 点云数据来标记训练阶段使用的地面事实。训练和推理之间的这种不一致使得大规模反馈数据难以利用并增加了数据收集费用。为了弥补这一差距,我们提出了一种新的弱监督单目 3D 物体检测方法,该方法可以仅使用图像上标记的 2D 标签来训练模型。具体来说,我们在该任务中探索了三种一致性,即投影一致性、多视图一致性和方向一致性,并基于这些一致性设计了弱监督架构。此外,我们在此任务中提出了一种新的2D方向标记方法来指导模型进行准确的旋转方向预测。实验表明,我们的弱监督方法取得了与一些完全监督方法相当的性能。当用作预训练方法时,我们的模型可以显着优于仅具有 1/3 3D 标签的相应完全监督基线。
主要贡献:
- 在这项工作中,我们提出了一种新颖的单目 3D 物体检测弱监督方法,该方法仅利用 2D 标签作为地面实况,而不依赖 3D 点云进行标记,使我们成为第一个这样做的人。
- 我们的方法结合了投影一致性和多视图一致性,用于设计两种一致性损失,指导准确的 3D 边界框的预测。
- 此外,我们引入了一种称为 2D 方向标签的新标签方法,取代了点云数据中的 3D 旋转标签以及基于新标签的方向一致性损失。
- 我们的实验表明,我们提出的弱监督方法实现了与一些完全监督方法相当的性能,即使只有 1/3 的真实标签,我们的方法也优于相应的完全监督基线,展示了其基于反馈生产数据改进模型的潜力。
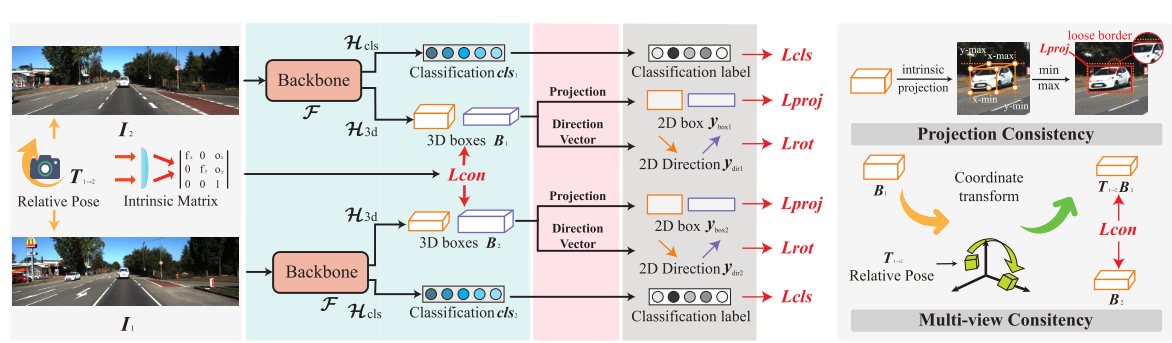
第三篇:SKD-WM3D
Weakly Supervised Monocular 3D Detection with a Single-View Image(2024)
论文链接
[代码暂未公布]
摘要
单目 3D 检测 (M3D) 旨在从单视图图像中精确定位 3D 对象,这通常涉及 3D 检测框的劳动密集型注释。最近研究了弱监督 M3D,通过利用许多现有的 2D 注释来消除 3D 注释过程,但它通常需要额外的训练数据,例如 LiDAR 点云或多视图图像,这大大降低了其在各种应用中的适用性和可用性。我们提出了 SKD-WM3D,这是一种弱监督的单目 3D 检测框架,它利用深度信息仅通过单视图图像实现 M3D,无需任何 3D 注释或其他训练数据。 SKD-WM3D 的一个关键设计是自知识蒸馏框架,它通过融合深度信息将图像特征转换为 3D 表示,并有效减轻单目场景中固有的深度模糊性,而推理中的计算开销很小。此外,我们设计了一种不确定性感知蒸馏损失和一种梯度目标转移调制策略,分别促进知识获取和知识转移。大量实验表明 SKD-WM3D 明显超越了最先进的方法,甚至与许多完全监督的方法相当。
介绍
弱监督 M3D (WM3D) [32] 最近被探索用于学习没有 3D 框注释的有效 3D 检测器,旨在利用 2D 注释来弥补 3D 信息的缺失。例如,WeakM3D [32] 利用 LiDAR 点云来推断 3D 信息,如图 1(a) 所示。然而,它需要昂贵且复杂的激光雷达传感器来收集点云,这极大地限制了其适用性和可用性。 WeakMono3D [40] 仅通过利用来自多个摄像机的图像的多视图双目或从连续视频帧构建伪多视图透视来使用 2D 信息,如图 1(b) 所示。然而,收集多视角图像很复杂,并且采用伪多视角视角会明显降低检测性能。随着单视图深度估计的进步,具有单视图图像深度的 WM3D 为补偿 3D 注释的缺失提供了一种潜在的解决方案。另一方面,将这种深度直接集成到现有框架中通常需要复杂的网络架构,这会进一步产生大量的计算成本。这就提出了一个相关问题:当不使用额外的激光雷达点云或多视图图像对时,是否可以利用现成的深度估计器的深度,而不会在推理中引入大量计算开销?
我们设计了 SKD-WM3D,这是一种新颖的弱监督单目 3D 物体检测方法,专门基于单视图图像。 SKDWM3D 的一个关键设计是自我知识蒸馏框架,由深度引导自教学网络 (DSN) 和单目 3D 检测网络 (MDN) 组成。如图 1(c)所示,
- SKD-WM3D 利用从现成的深度估计器 [Penet] 获得的深度信息来增强 DSN 的 3D 定位能力,并通过自知识蒸馏将这种能力转移到 MDN。这种自蒸馏设计使得MDN能够独立地从单视图图像中挖掘内在的深度信息,绕过预训练深度估计网络等附加模块,实现精确高效的 3D 定位,推理期间的计算开销很小。
- 在 DSN 和 MDN 之上,我们设计了一种不确定性感知蒸馏损失,通过加权更确定的知识同时降低不太确定的知识来优化传输的 3D 定位知识的利用率。
- 此外,我们设计了一种梯度目标转移调制策略,在学习3D定位知识的过程中同步DSN和MDN的学习进度,通过在MDN落后于DSN的初始阶段优先考虑MDN学习并使其能够提供更多反馈当 MDN 在后期得到更好的训练时,转向 DSN。
![图 1. 弱监督单目 3D 检测的不同范例。 (c) 中的方法利用单视图图像中的伪深度标签来实现弱监督的单目 3D 检测,不需要额外的训练数据,如 (a) 和 (b) 中的 LiDAR 点云或多视图图像。它大大提高了可用性和适用性。伪深度标签是使用现成的深度估计器[Penet]获得的,无需额外的训练和地面实况深度标签。红色数据表示网络训练中的额外数据。](/pic/weak3d7.png)
主要贡献:
- 首先,我们设计了一个新颖的框架,通过在深度引导自学网络和单目 3D 检测网络之间提取知识来实现弱监督单目 3D 检测。无需任何额外的训练数据(例如 LiDAR 点云或多视图图像),该框架仅利用单个图像的深度,推理时的计算开销很小。
- 其次,我们设计了一种不确定性感知蒸馏损失和一种梯度目标转移调制策略,分别促进知识获取和知识转移。
- 第三,所提出的方法明显优于弱监督单目 3D 检测的最新技术,其性能甚至与几种完全监督方法相当。
相关工作
基于单目的三维目标检测方法
单目 3D 对象检测旨在从单视图图像预测 3D 对象定位。标准单目探测器 [1, 6, 13, 51, 54] 仅对单个图像进行操作,无需使用额外的数据。然而,与双目检测相比,单目检测固有的深度模糊性严重阻碍了其性能。为了解决这一限制,各种方法在额外数据的帮助下寻求解决方案,例如 LiDAR 点云 [4,7,20,25]、视频序列 [2]、3D CAD 模型 [5,23,29] 和深度估计[9,33,43,46]。具体来说,MonoRUNn [4] 采用不确定性感知区域重建网络,以 LiDAR 点云作为额外监督来回归像素关联的 3D 对象坐标。 MonoDistill [7] 引入了一种有效的基于蒸馏的方法,该方法将 LiDAR 信号的空间信息合并到单目 3D 检测中。此外,基于伪 LiDAR 的方法 [43, 46] 转换估计的深度图以模拟真实的 LiDAR 点云,以利用精心设计的基于 LiDAR 的 3D 探测器。在推理过程中,与使用深度估计的方法相比,我们的方法不需要伪深度标签和复杂的网络架构,计算开销很小。此外,现有的完全监督方法需要大规模的 3D 框地面实况,这对于收集和注释来说是劳动密集型的。
弱监督 3D 物体检测
由于在 3D 对象检测任务中注释 3D 框的成本很高,因此提出了各种弱监督方法。例如,WS3D [27] 提出了一种用于 3D LiDAR 物体检测的弱监督方法,该方法仅需要有限数量的带有中心注释 BEV 地图的弱注释场景。 VS3D[34]引入了一种跨模型知识蒸馏策略,将知识从RGB域转移到点云域,使用LiDAR点云作为弱监督。最近关于弱监督 3D 对象检测的研究已转向探索单目设置。例如,WeakM3D[32]生成2D框来选择RoI激光点云作为弱监督,然后预测与所选 RoI LiDAR 点云紧密对齐的 3D 框。最近,WeakMono3D [40] 消除了对 LiDAR 的需求,提供多视图和单视图多帧版本。前者从多个摄像机获取立体图像输入,而后者使用多个视频帧构建伪多视图透视。与多视图方法相比,多帧版本由于其较小的帧间视差而表现出较差的 3D 场景理解能力,从而导致性能下降。我们不需要 LiDAR 点云或多视图图像等额外的训练数据,而是通过专门利用单视图图像来解决弱监督单目 3D 检测的挑战。
自认识蒸馏
知识蒸馏[8,10,15,17,22,30,36,41,52]旨在将知识从预先训练的教师网络转移到学生网络以提高其性能。自我知识蒸馏[28,39,45]与传统的知识蒸馏不同,它利用学生网络内的信息来促进其学习,而无需预先训练的教师网络。具体来说,数据增强方法[14,44,48]通过相同训练数据的不同扭曲来传递知识。然而,它们很容易受到不适当的增强的影响,例如不适当的实例旋转或扭曲,可能会引入阻碍网络学习的噪音。另一种典型的方法利用辅助网络 [50, 55]。例如,DKS [38]引入了辅助监督分支和成对知识对齐,而FRSKD [18]添加了由原始特征监督的新分支,并利用了软标签和特征图蒸馏。我们的工作是第一个引入自知识蒸馏和辅助网络的弱监督单目 3D 检测的工作。它有效地利用单视图图像的深度信息,在推理过程中几乎不需要计算开销。
方法
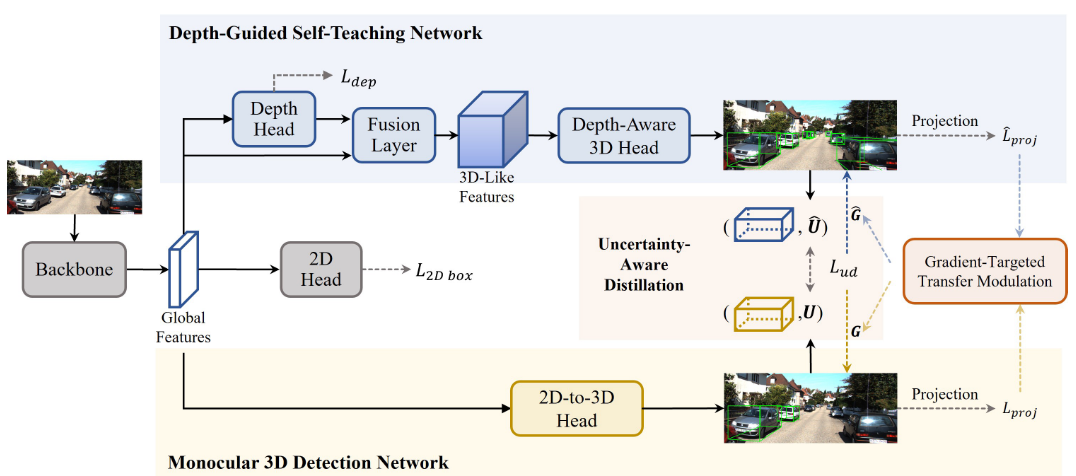
问题定义和概述
弱监督单目 3D 检测以 RGB 图像和相应的 2D 边界框作为监督,旨在在 3D 空间中对对象进行分类并确定其边界框,而无需在训练中涉及任何 3D 注释。每个对象的预测由对象类别C、2D边界框B2D和3D边界框B3D组成。具体来说,3D框B3D可以进一步分解为对象3D位置(x3D,y3D,z3D),具有高度、宽度和长度的对象尺寸(h3D,w3D,l3D)以及方向θ。
我们设计了一个自我知识蒸馏框架来应对单视图图像弱监督单目 3D 检测的挑战。如图 2 所示,该框架由两个子网络组成,包括深度引导自教学网络和单目 3D 检测网络。在深度引导自学习网络中,主干提取的全局特征FG被输入深度头以获得深度特征。接下来,将全局特征 FG 和提取的深度特征输入融合层以获得类 3D 特征 F3D。然后通过 RoIAlign 获得每个对象的 3D 特征,并进一步馈送到深度感知 3D 头以预测 3D 框 Bb 3D p 和不确定性 bU。在单目 3D 检测网络中,我们首先使用 RoIAlign 从全局特征 FG 生成对象级特征,然后将它们提供给 2D-to-3D Head 来预测 3D 框 bB2D p 和不确定性 U。此外,通过以下方式预测的 3D 框两个网络都进一步投影到二维盒子中。此外,我们设计了一种不确定性感知蒸馏损失 Lud 来获得低不确定性知识,并设计了一种梯度目标转移调制策略,通过控制 Lud 的梯度 bG 和 G 来同步两个网络之间的学习速度。
自我知识蒸馏框架
自知识蒸馏框架利用来自现成深度估计器的深度信息增强深度引导自教学网络的 3D 定位能力,然后通过自知识蒸馏将该能力转移到单目 3D 检测网络。
深度引导自学网络为了使自学网络具备 3D 定位能力,我们建议从现成的深度估计器中学习全局特征 FG 和深度信息,以获得全面的 3D 知识。深度信息通过两种主要设计来利用。首先,我们引入一个提取深度特征FD的深度头D,利用深度特征 FD 来生成深度图 Dp,其中深度图的生成由深度图 Dgt 的伪地面实况监督,深度图 Dgt 是由现成的深度估计器通过使用焦点损失 [21] 来预测的深度损失 Ldep。因此,深度引导自学习网络可以有效地获取深度特征。
备注 1. 我们使用带有冻结权重的现成深度估计器 [16] 生成深度伪标签,从而无需额外的训练和地面实况深度标签。与之前需要 LiDAR 点云 [32] 或多视图图像 [40] 的研究相比,采用现成的深度估计器所产生的成本可以忽略不计。
其次,我们通过集成提供沿深度维度信息的深度特征 FD 以及捕获有关 2D 图像平面的知识的全局特征 FG 来获得类 3D 特征 FG3D。具体来说,我们设计了一个融合层,将深度特征 FD 与全局特征 FG 融合,得到 FG3D,如下所示:
其中FFN是前馈网络,CA、SA分别表示CrossAttention、SelfAttention。 CrossAttention 和 SelfAttention 的结构采用标准的 Transformer 架构 [42]。获得的 3D 理解提高了网络精确定位对象的能力,有效减轻了单视图图像输入引起的深度模糊。
单目 3D 检测网络 单目3D检测网络从深度引导自学习网络获取3D定位知识。通过提取深度引导自学习网络生成的软标签,单目 3D 检测网络可以在推理过程中独立地从图像中提取内在深度信息。这消除了对额外复杂模块(例如预训练深度估计网络或深度融合模块)的需求,从而以很少的计算开销促进推理。
不确定性蒸馏损失
在知识蒸馏过程中,如果平等对待所有转移的知识,不确定的知识可能会对网络训练产生负面影响。为了更多地从某些知识中受益并削弱不确定知识的影响,我们在自知识蒸馏框架中的两个网络预测的 3D 框之间设计了一个不确定性感知的蒸馏损失。不确定性蒸馏损失利用预测不确定性来调节蒸馏损失大小
传输调制策略
深度引导自学网络利用深度信息来预测 3D 框,将其学到的 3D 知识传输到单目 3D 检测网络。两个网络的异步学习速度对有效的 3D 知识迁移提出了潜在的挑战。我们设计了一种梯度目标转移调制策略来同步深度引导自学网络和单目 3D 检测网络的学习速度。我们通过控制不确定性蒸馏损失 Lud 的梯度来动态调节知识转移。具体来说,我们根据每个网络的 2D 投影性能来调整梯度,为性能良好的网络分配较小的后向梯度,为性能差的网络分配较高的后向梯度。梯度目标转移
总体目标由三个损失组成,包括 Lud、Ldep 和 Lbase。 Lud 是定义的不确定性蒸馏损失。 Ldep是用于监督预测深度图的深度损失。 Lbase 包括用于监督 2D 头和 3D 框预测的 2D 框预测的损失,这已在先前的 CenterNet [53] 和 WeakMono3D [40] 中采用。我们将每个损失项的权重设置为1.0
评估协议
对于 KITTI 3D 数据集,按照[37],我们采用评估指标 AP|R40,它是 40 个召回点的 AP 的平均值。我们将鸟瞰图和 3D 物体检测的平均精度报告为 APBEV|R40 和 AP3D|R40 。此外,由于大多数弱监督 3D 对象检测方法对测试集应用 0.7 的 IoU 阈值,对验证集应用 0.5 的 IoU 阈值,因此我们采用相同的阈值进行公平基准测试。我们采用四个指标对nuScenes数据集进行评估,即AP(平均精度)、ATE(平均翻译误差)、ASE(平均尺度误差)和AAE(平均属性误差)。根据[32],由于弱监督方法中缺乏对速度和运动方向的监督,因此未报告 AVE(平均速度误差)和 AOE(平均方向误差)。
表 1. Car 类别在 KITTI 测试集上的性能比较。对于所有结果,我们使用 IoU 阈值等于 0.7 的 AP|R40 指标。最好的结果以粗体显示。
表 2. Car 类别在 KITTI val 集上的性能比较。对于所有结果,我们使用 AP|R40 指标,IoU 阈值等于 0.5。 * 表示此性能是从官方代码复制的。弱监督 3D 对象检测方法的最佳结果以粗体显示。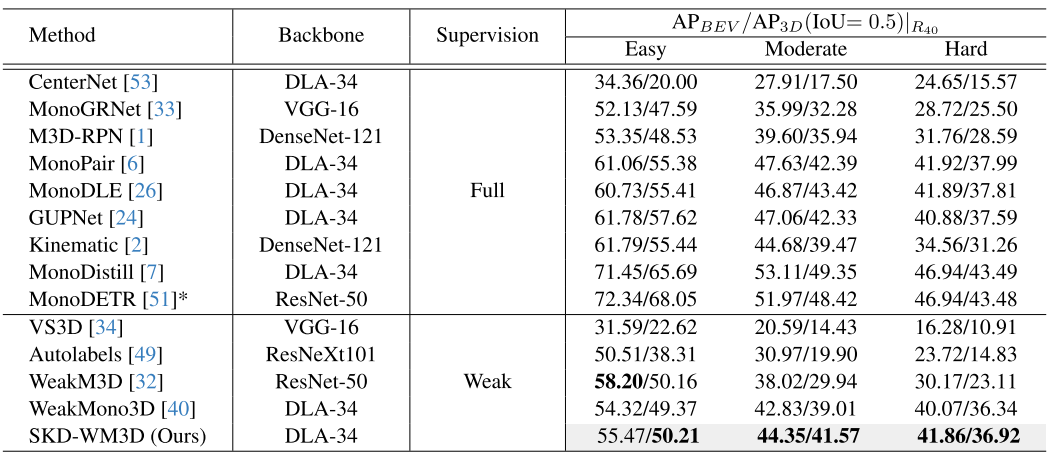
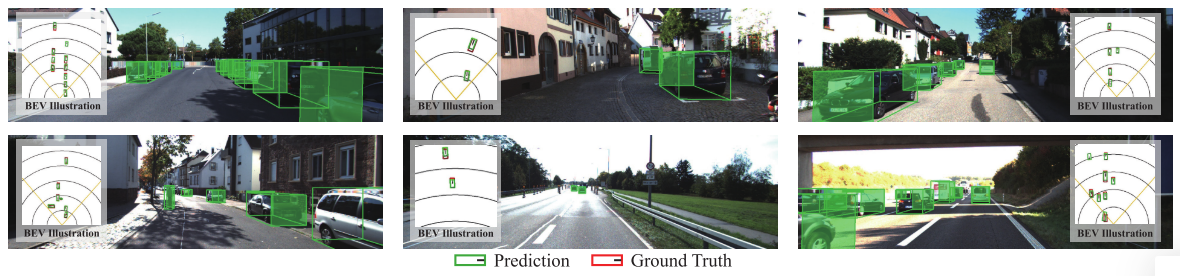
图 3. KITTI val 集的定性说明。红色框表示真实注释,绿色框表示我们的预测。 LiDAR 点云的地面实况仅用于可视化目的。放大观看效果最佳。
第四篇:Ba2det
Weakly Supervised 3D Object Detection with Multi-Stage Generalization(2023)
摘要
随着大型模型的快速发展,对数据的需求变得越来越重要。特别是在 3D 对象检测中,昂贵的手动注释阻碍了进一步的进步。为了减轻注释的负担,我们研究了仅基于 2D 注释实现 3D 对象检测的问题。得益于先进的 3D 重建技术,现在可以重建整个静态 3D 场景。然而,从整个场景中提取精确的对象级注释并将这些有限的注释推广到整个场景仍然是挑战。在本文中,我们介绍了一种称为 BA2-Det 的新颖范式,包括伪标签生成和多阶段泛化。我们设计了 DoubleClustering 算法,从重建的场景级点中获取对象簇,并通过发展从完整到部分、从静态到动态、从近到远的三个泛化阶段,进一步增强模型的检测能力。在大规模 Waymo 开放数据集上进行的实验表明,BA2-Det 的性能与使用 10% 注释的完全监督方法相当。此外,使用大型原始视频进行预训练,BA2-Det 可以在 KITTI 数据集上实现 20% 的相对改进。该方法在复杂场景中检测开放集 3D 对象方面也具有巨大潜力。
相关内容
由于需要大量且昂贵的手动注释,完全监督的 3D 对象检测方法的进一步发展可能受到限制。为了克服这一限制,之前的一些工作探索了弱监督算法(Zakharov et al., 2020; Peng et al., 2022c)和额外的 LiDAR 数据来释放未标记图像的潜力。然而,对激光雷达传感器的依赖限制了这些方法在更一般场景中的实用性。随着二维基础模型的进步(Kirillov et al., 2023),二维注释不再是瓶颈。在本文中,我们旨在研究仅基于 2D 注释实现 3D 对象检测的可行性,这是一个尚未探索的问题。
该问题的核心挑战在于从 2D 图像中获取 3D 信息。从 3D 重建技术(Schonberger & Frahm,2016)中汲取灵感,我们可以获得整体静态 3D 场景结构。因此,核心挑战已经转移到从全局场景中提取对象级伪标签,并将有限的对象伪标签推广到更多对象。
主要贡献:
- 我们提出了一种仅使用 2D 标签进行弱监督单目 3D 物体检测的新范例。利用 3D 重建和神经网络的泛化能力,我们首次提出了该问题的实用解决方案。
- 我们提出的方法名为 BA2-Det,解决了学习 3D 对象检测器时的三个基本技术挑战。我们概括了三个阶段:从全面到局部、从静态到动态、从近到远。
- 我们在各种数据集上进行了实验,包括 KITTI 数据集和大规模 Waymo 开放数据集 (WOD),证明了我们的方法在生成高质量 3D 标签和利用大规模数据进行预训练方面的有效性。 BA2-Det 的性能与仅用 10% 的视频训练的完全监督 BADet 相当,甚至优于一些领先的完全监督方法。作为一种预训练方法,BA2-Det 在 KITTI 数据集上可以实现 20% 的相对提升。
- 我们进一步研究了我们的方法的潜在影响,包括复杂场景中开放集3D 对象的检测以及3D 对象跟踪的下游应用。
方法
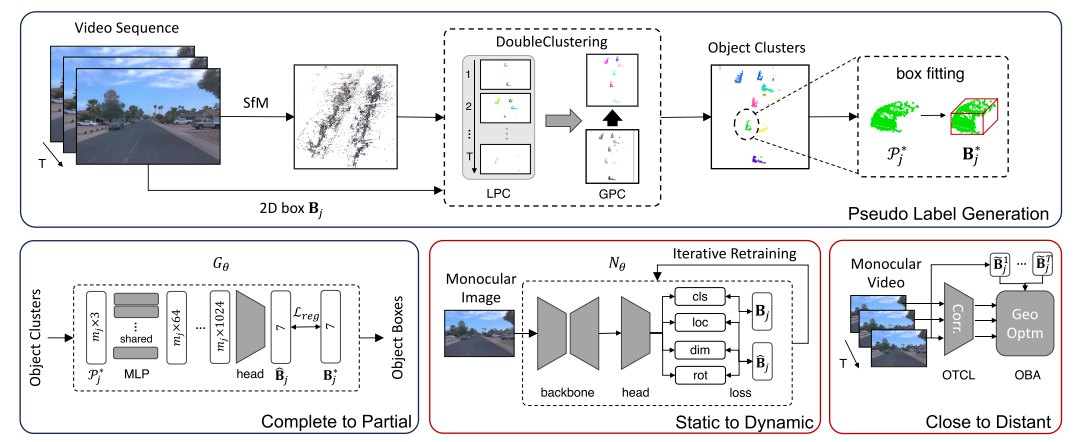
算法概述。我们简要介绍我们的框架 BA2Det 并解释模块设计。如图1所示,BA2-Det包括两个主要部分,高质量伪标签生成和伪标签的多阶段泛化。
- 在伪标签生成阶段,我们首先利用移动摄像机的场景级重建来获取全局点云。为了从场景重建中提取 3D 对象簇,我们设计了 DoubleClustering 算法。对象簇进一步与长方体拟合以形成 3D 边界框。
- 在随后的多阶段泛化阶段(第 3.2 节),
- (1)为了从完整泛化到部分,我们开发了一个神经网络来从良好重构的对象中学习部分对象的 3D 对象边界框;
- (2) 为了从静态推广到动态,我们通过精心设计的学习策略和迭代细化来训练 3D 目标检测器;
- (3) 为了从近到远进行概括,我们遵循具有几何特征聚合的学习时间对象检测器。
场景级重建的伪标签生成
使用运动结构 (SfM) 技术,可以根据自我运动重建 3D 场景。然后,从重建场景中,借助每帧中的 2D 边界框,可以通过对重建场景中的前景点进行聚类来获得 3D 对象簇。因此,在本节中,我们介绍一种称为 DoubleClustering(算法 1)的算法,用于从 3D 重建场景中提取 3D 对象簇。
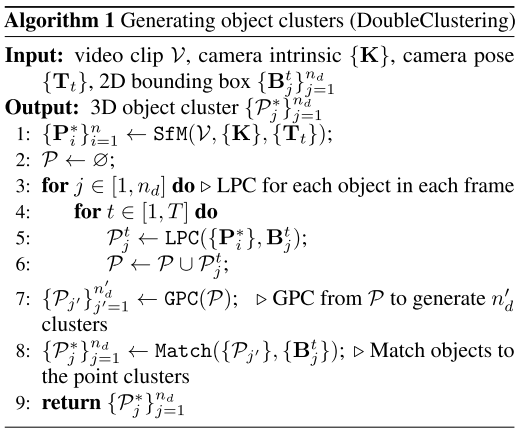
场景重建。首先,让我们回顾一下使用 SfM 进行场景重建。我们将视频序列表示为 V = {It|t = 1, 2 · · · , T},图像 It 中的关键点表示为 pi t = [ui, vi]⊤, (i = 1, 2, · · · , n )和每个关键点上的局部特征为 Ft = {fi t }。在本文中,我们使用关键点提取器和局部特征匹配网络 SuperPoint (DeTone et al., 2018) 和 SuperGlue (Sarlin et al., 2020)。给定时间 t 内摄像机的内在参数 K 和外在参数 Tt = [Rt|tt],全局帧中的 3D 关键点 Pi 可以通过求解束调整 (BA) 进行优化,其中投影误差在任意两个之间的相应关键点上计算图像为: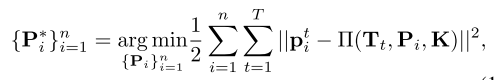
其中 Π(·) 是将世界坐标系中的 3D 点投影到图像的函数。此外,K和Tt也可以在BA过程中进行优化。请注意,当自我缓慢移动时,两帧之间的差异很小,观察噪声会影响重建。因此,当摄像机缓慢移动时,我们忽略视频序列,不重建场景。速度阈值定义为ω。
对象点云聚类。场景重建后,我们引入了一种两步对象聚类算法,称为 DoubleClustering,以分离和聚类重建场景中的对象点云。首先,在每一帧中,我们选择可以投影在2D边界框中的3D点,并执行局部点聚类(LPC)来为每个对象Bt j选择最大的聚类: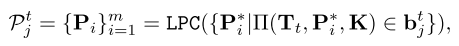
其中我们将 bt j 表示为 2D 框 Bt j 中的图像区域。聚类算法基于连通分量(CC)算法,CC算法中的距离阈值为δ1。
其次,我们收集每一帧的聚类,并在整个场景中进行全局聚类。聚类算法也是基于距离阈值δ2的CC,称为全局点聚类(GPC):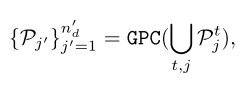
其中 n′ d 是对象簇总数。我们忽略点数低于阈值 θ 的簇,因为它们可能代表噪声点。最后,我们选择其中投影点数量最多的对象簇作为 2D 边界框 Bt j 的对应簇 P*j。
3D 边界框拟合。现在我们获得了对象簇,然后我们需要根据每个簇中的对象点生成初始 3D 伪框。给定对象簇 P* j ,我们根据对象点拟合一个紧密的 3D 边界框。这些紧密的盒子充当初始 3D 标签。利用重建点主要位于物体表面的假设,并受到Zhang等人的启发。 (2017),我们通过最小化点与其最近边缘之间的总距离来优化方向 ry。随后,我们调整鸟瞰图边界框的宽度和长度以实现最小面积: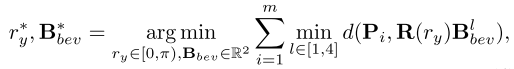
其中 Pi 是对象簇中的 3D 点,R(ry)Bl bev 是鸟瞰图 (BEV) 中旋转边界框的边缘,角度为 ry,我们使用 l2 距离作为距离函数 d(·)。我们使用沿 z 轴的点来计算盒子的高度。我们通过测量点云沿 z 轴的最高点和最低点之间的距离来计算盒子的高度,最终生成对象 j 的 3D 盒子 B* j 。
多阶段泛化
某些对象可能会被异常点遮挡或影响。这些部分对象没有得到很好的重建,导致标签不准确,特别是对于大小和方向估计。因此我们设计了第一阶段的完整到部分泛化。在传统的SfM系统中,重建静态物体上的点很容易,但重建运动物体却很困难,因为它们的运动与自运动不同,并且受到对极几何约束的过滤。只有静态对象位于初始伪标签中。因此我们提出了第二阶段的静态到动态的泛化。此外,远处的物体具有脆弱的视觉特征。因此我们提出了第三阶段的近远时间泛化。
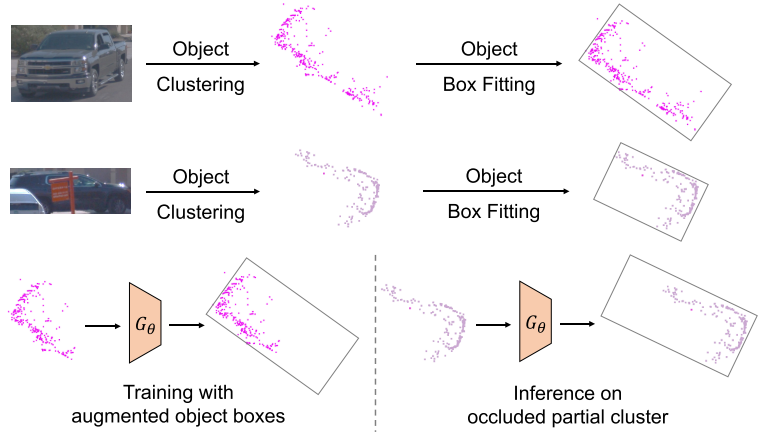
从完整对象到部分对象的概括。泛化的第一阶段是训练模型以根据遮挡/部分对象点云预测完整的 3D 边界框。因此,我们设计了一个神经网络 Gθ 来从重建良好的完整对象中学习和细化初始 3D 边界框。一般来说,我们期望首先找到重建良好/完整的对象作为训练数据,即可以从对象点云正确拟合其3D边界框的对象。然后从这些对象中学习,网络可以预测所有对象簇的完整 3D 框。图 2 显示了 Gθ 的工作原理。然后,我们为每个对象簇优化并生成紧密的 3D 边界框作为初始伪标签。
该网络以对象簇 Pj ∈ Rmj×3 作为输入,并使用初始 3D 伪框 Bj 的中心标准化 3D 点的坐标。它由 PointNet 主干和预测 7DoF 3D 边界框 Bb j = [cx, cy, cz, w, h, l, ry] 的头组成。我们使用平滑的 L1 边界框定位损失 Lreg。请注意,我们仅将 [σ0, σ1] 之间的长度视为重构良好的对象,并采用这些 3D 伪框来监督 Gθ。为了模拟遮挡引起的部分对象点,我们通过从重建良好的对象簇中随机切除区域来执行数据增强。训练 Gθ 的更多细节在第 2 节中。附录A.3.5。
从静态对象到移动对象的概括。我们还需要解决伪标签主要来自静态对象的问题。我们观察到,在单个单眼图像中,静态和移动的物体具有相似的外观。因此,网络可以将从静态标签学习到的 3D 对象预测推广到其他移动对象。我们将单目 3D 物体检测器表示为 Nθ。网络架构基于CenterNet(Zhou et al., 2019;张等人,2021)。在我们的弱监督设置中,许多对象都有 2D 标签 Bj,但由于它们的运动,没有相应的 3D 伪标签 bBj。此外,伪标签bBj可能具有不准确的方向。所以,不同于全监督的目标检测,我们设计了一个新的标签分配策略和方向损失。
对于未标记的移动物体的问题,使用传统的 3D 标签分配来训练网络会导致许多漏报。我们使用 2D 地面实况 (GT) 标签分配标签,如果没有 3D 伪标签,则忽略它们的 3D 损失:
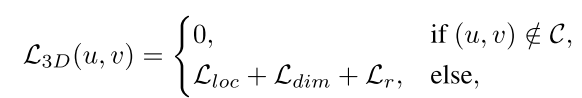
其中 (u, v) 是图像上的像素,C = {(cu, cv)|[(cu, cv) 是 Bj 的中心] ∧ [ bBj ̸= ∅]}。如图 3 所示,所提出的 2D 分配确保未标记的对象不被视为负样本。

弱监督的另一个困难是区分物体是朝前还是朝后。 3D 伪标签的方向可能与真实航向存在 180° 的偏差。我们修改了原始的 MultiBin 方向损失(Mousavian et al., 2017)来缓解这个问题。新的方向损失是原始损失和 180° 反转损失中最小的:
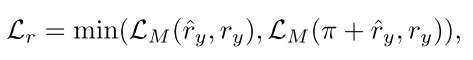
其中 LM 是 MultiBin Loss,^ry 是偏航预测,ry 是伪地面实况。
为了进一步细化广义对象框,我们用预测作为更新的伪标签迭代地重新训练检测器。我们采用重新训练策略,使用 3D 伪标签进行初始训练,并使用上次迭代的预测更新标签:
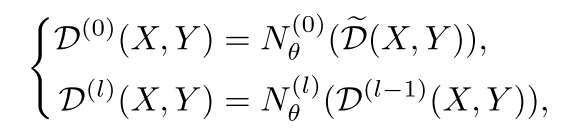
其中eD(X,Y)是具有生成的伪标签的数据集,D(l)(X,Y)是具有预测标签的数据集,(l)表示第l次自训练迭代。请注意,我们不会保留每次自重新训练迭代的最后网络参数,并为相同的 κ epochs训练网络 Nθ。
从近处到远处的物体的概括。单目 3D 物体检测器面临的一个自然挑战是远处物体的像素较少,因此很难估计其 3D 位置,尤其是深度估计。受 BA-Det (He et al., 2023) 的启发,我们利用几何时间聚合将近距离物体推广到远处物体。具体来说,我们使用以对象为中心的时间对应学习(OTCL)模块来学习对象的以对象为中心的特征对应关系,并解决跟踪对象预测{eB1 j,eB2 j,……,eBT之间的对象中心束调整(OBA) j } 在推理过程中由 Nθ 得出。
结果
表 1:WOD val 集的主要结果。 “3D Sup.”是指带有 3D 标签的视频序列的比例。 “Tem.”是指使用时间对象检测器。 †:使用 1/3 帧进行训练。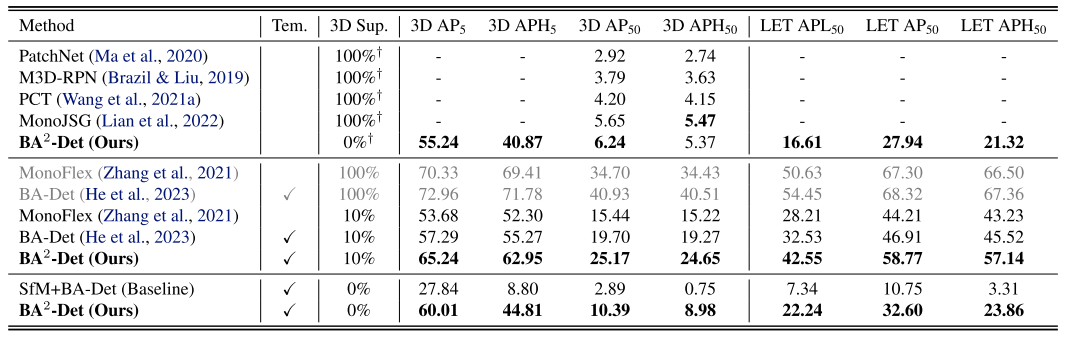
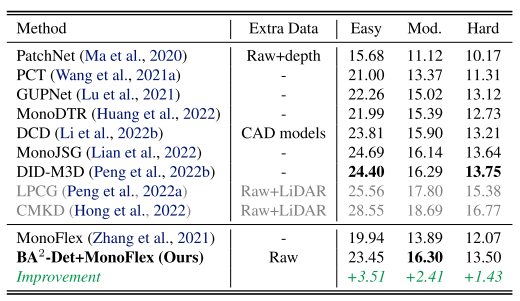
表2:KITTI检测基准测试集的结果。 “Raw”是指使用 KITTI Raw 集中的图像。 “Mod.”是指中等难度。